聚类分析是一种无监督学习方法,通过学习没有分类标记的训练样本分析数据本身的结构来发现数据的内在模式
[TOC]
数据之间的相似性通常用距离度量,类内差异应尽可能小,类间差异应尽可能大
根据形成距离类的方式不同,聚类算法可以分为:层次聚类、原型聚类、分布聚类、密度聚类
聚类分析的重要应用是对用户进行分组与归类
聚类分析是一种无监督学习方法,通过学习没有分类标记的训练样本分析数据本身的结构来发现数据的内在模式
[TOC]
数据之间的相似性通常用距离度量,类内差异应尽可能小,类间差异应尽可能大
根据形成距离类的方式不同,聚类算法可以分为:层次聚类、原型聚类、分布聚类、密度聚类
聚类分析的重要应用是对用户进行分组与归类
2-计算机常识
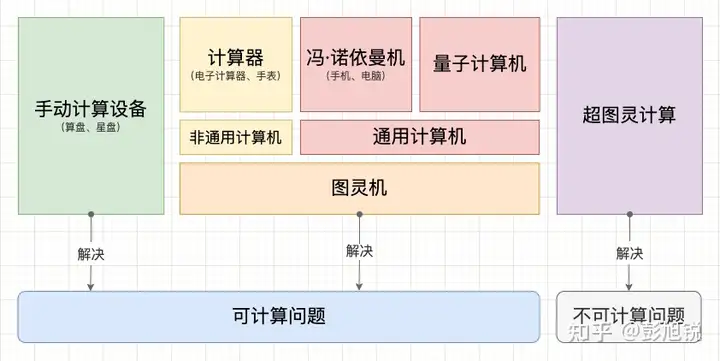
[TOC]
集成学习使多个学习器获得比单个学习器更好的预测性能,包括序列化方法和并行化方法两类
多样性要求集成学习中的不同个体学习器之间具有足够的差异性
序列化方法采用 Boosting 机制,通过重复使用概率分布不同的训练数据实现集成,降低泛化误差的偏差
并行化方法采用 Bagging 机制,通过在训练数据中多次自助抽取不同的采样子集实现集成,降低泛化误差中的方差
计算机配置
支持向量机是一种二分类算法,通过在高维空间中构建超平面实现对样本的分类
[TOC]
线性可分SVM通过硬间隔最大化求出划分超平面,解决线性分类问题
线性SVM通过软间隔最大化求出划分超平面,解决线性分类问题
非线性SVM利用核函数实现从低维原始空间到高维特征空间的转换,在高维空间上解决非线性分类问题
SVM的学习时个凸二次规划问题,可以用SMO算法快速求解
决策树算法采用树形结构,使用层层推理来实现最终的分类
[TOC]
决策树是包含根结点,内部结点和叶结点的树结构,通过判定不同属性的特征来解决分类问题
决策树的学习过程包括特征选择,决策树生成,决策树剪枝三个步骤
特征选择的指标包括信息增益,信息增益比和基尼系数
决策树的剪枝策略包括预剪枝和后剪枝
图:点+边+边与点的映射函数
连通性与判别
欧拉图与哈密尔顿图
二分图和平面图与欧拉公式
树及生成树
单源点最短路径:Dijkstra算法
对偶图
代数系统:把一些形式上很不相同的代数系统,用统一的方法描述、研究、推理,从而得到反映出他们共性的一些结论,在将结论运用到具体的代数系统中
系统:运算+研究对象
- 运算:具有的共同性质的不同演算抽取成一个运算,根据性质的不同取名群、环域等。
研究对象:可以运算的抽象对象
如:集合上的并满足结合律,实数上的加法也满足结合律,用一个符号代表具有结合律的运算,而研究对象变为代表实数或者集合等对象的抽象事物
所以代数系统定义为:非空集合和定义在集合上的封闭运算构成的系统
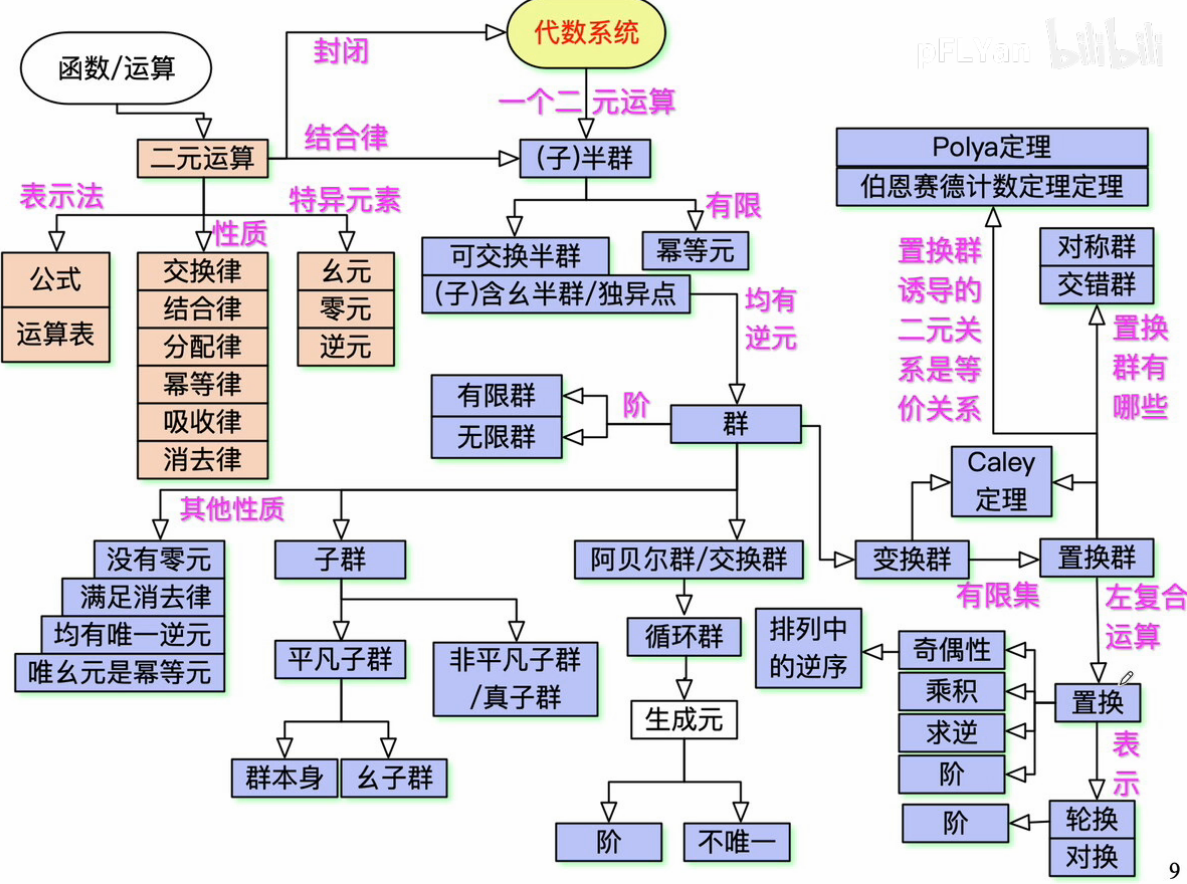
[TOC]
线性模型既能体现出重要的基本思想,又能构造出功能更加强大的非线性模型
[TOC]
线性模型假设输出变量是若干输入变量的线性组合,并根据这一关系求解线性组合的最优系数
最小二乘法可用于解决单变量线性回归问题,当误差函数服从正态分布时,与最大似然估计等价
多元回归问题也可以用最小二乘法求解,但极易出现过拟合线性