微服务的理解
原文:
https://blog.csdn.net/u012256142/article/details/82839728?spm=1001.2014.3001.5502
https://blog.csdn.net/wuxiaobingandbob/article/details/78642020
组件化与模块化
组件化
组件化就是基于可重用的目的,将一个大的软件系统按照分离关注点的形式,拆分成多个独立的组件,主要目的就是减少耦合。
- 一个独立的组件可以是一个软件包、web服务、web资源或者是封装了一些函数的模块。这样,独立出来的组件可以单独维护和升级而不会影响到其他的组件。
模块化
模块化的目的在于将一个程序按照其功能做拆分,分成相互独立的模块,以便于每个模块只包含与其功能相关的内容,模块之间通过接口调用。将一个大的系统模块化之后,每个模块都可以被高度复用。
区别
模块化的目的是为了 重用提高代码复用性 ,模块化后可以方便重复使用和插拨到不同的平台,不同的业务逻辑过程中
组件化的目的是为了 解耦便于独立维护 ,把系统拆分成多个组件,分离组件边界和责任,便于独立升级和维护
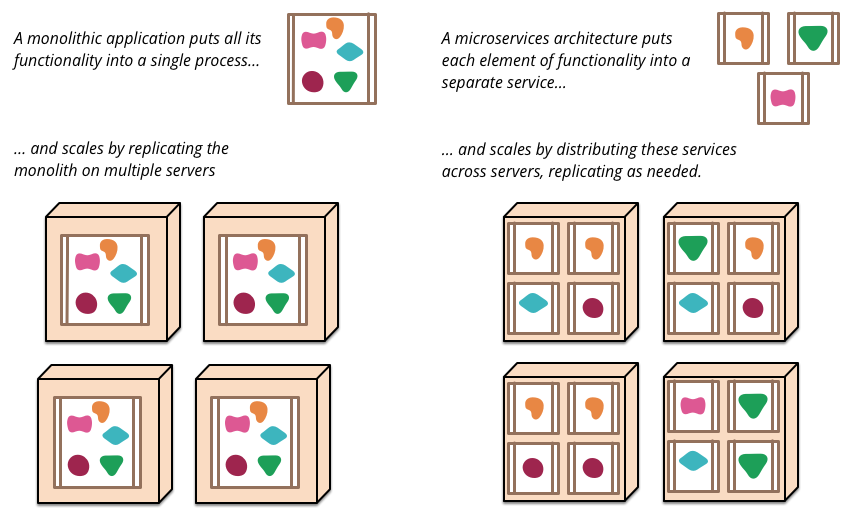
微服务与单体应用
单体应用
应用作为整体打包部署,Java应用会打包成 war 包运,部署在 Tomcact或者 Netty 这样的应用服务器。
优点
- 易于开发
- 易于测试,通过运行应用就可以实现端到端的测试
- 易于部署,仅仅需要复制打包的应用到服务器
缺点:随着应用程序规模的扩大
- 拖慢开发进度,启动时间越来越长
- 无法按需伸缩:为了更新程序的一小部分,需要重新部署整个应用
- 不便于扩展,同一应用的每个功能模块都适用相同的技术实现
- 可靠性低,所有功能模块都在统一进程运行,任何一个模块出现漏洞,都会影响整个进程
微服务
微:体积小
服务:一个或者一组独立的功能单元
微服务架构是一种使用一组小服务来开发单个应用的开发方式,使得这些服务可以独立的开发、部署、运行、维护。服务之间采用轻量级通信机制(通常是HTTP),实现结构上的 松耦合 ,在功能上表现为一个整体。
一个采用微服务架构的Web应用会按照功能模块 组件化 为一组更简单的web应用
微服务架构的优点
一个应用在整体功能没有改变的同时,被分解成若干可被单独管理的服务,每个服务都有以RPC或者Restful的接口形式定义的界限
RPC:Dubbo
RESTful:SpringBoot
每个服务可以使用不同的开发技术,只需要遵守API约定即可,扩展性强
可靠性高,每个服务独立部署和测试,运行在自己的进程中
每个服务可以根据实际需求动态分配资源
微服务的缺点
- 运维要求高
- 分布式的复杂性
- 接口调整成本高
- 重复劳动
最佳实践
整体架构只适合简单的轻量级应用。微服务架构对于复杂的、演化的应用是更好的选择,尽管微服务架构有些缺点和实现上的挑战。
微服务重要部件
服务注册中心
服务之间需要创建一种服务发现机制,用于帮助服务之间互相感知彼此的存在。服务启动时会将自身的服务信息注册到注册中心,并订阅自己需要消费的服务。
服务注册中心是服务发现的核心。它保存了各个可用服务实例的网络地址(IPAddress和Port)。服务注册中心必须要有高可用性和实时更新功能。
能够作为服务注册中心的有:
- etcd : 高可用,分布式,强一致性的,key-value,Kubernetes和Cloud Foundry都是使用了etcd。
- consul :一个用于discovering和configuring的工具。它提供了允许客户端注册和发现服务的API。Consul可以进行服务健康检查,以确定服务的可用性。
- zookeeper:在分布式应用中被广泛使用,高性能的协调服务。 Apache Zookeeper 最初为Hadoop的一个子项目,但现在是一个顶级项目。
zookeeper服务注册和发现
zookeeper可以充当一个服务注册表(Service Registry),让多个服务提供者形成一个集群,让服务消费者通过服务注册表获取具体的服务访问地址(ip+端口)去访问具体的服务提供者。
具体来说,zookeeper就是个分布式文件系统,每当一个服务提供者部署后都要将自己的服务注册到zookeeper的某一路径上: /{service}/{version}/{ip:port}, 比如我们的HelloWorldService部署到两台机器,那么zookeeper上就会创建两条目录:分别为/HelloWorldService/1.0.0/100.19.20.01:16888 /HelloWorldService/1.0.0/100.19.20.02:16888
zookeeper提供了 心跳检测 功能,它会定时向各个服务提供者发送一个请求,如果长期没有响应,服务中心就认为该服务提供者已经“挂了”,并将其剔除。
服务消费者会去监听相应路径(/HelloWorldService/1.0.0),一旦路径上的数据有变化,zookeeper都会通知服务消费方服务提供者地址列表已经发生改变,从而进行更新
容错容灾能力(比如leader选举),可以确保服务注册表的高可用性
负载均衡
服务高可用的保证手段,为了保证高可用,每一个微服务都需要部署多个服务实例来提供服务。此时客户端进行服务的负载均衡
常见策略
随机
把来自网络的请求随机分配给内部中的多个服务器
轮询
每一个来自网络中的请求,轮流分配给内部的服务器,从1到N然后重新开始。此种负载均衡算法适合服务器组内部的服务器都具有相同的配置并且平均服务请求相对均衡的情况
加权轮询
根据服务器的不同处理能力,给每个服务器分配不同的权值,使其能够接受相应权值数的服务请求
IP Hash
通过生成请求源IP的哈希值,并通过这个哈希值来找到正确的真实服务器。对于同一主机来说他对应的服务器总是相同
最少连接数
对内部中需负载的每一台服务器都有一个数据记录,记录当前该服务器正在处理的连接数量,当有新的服务连接请求时,将把当前请求分配给连接数最少的服务器,使均衡更加符合实际情况,负载更加均衡
容错
可以容下错误,不让错误再次扩张,让这个错误产生的影响在一个固定的边界之内
在调用服务集群时,如果一个微服务调用异常,如超时,连接异常,网络异常等,则根据容错策略进行服务容错
常见的降级,限流,熔断器,超时重试等等都是容错的方法
容错策略
快速失败
服务只发起一次待用,失败立即报错。通常用于非幂等下性的写操作
失效切换
服务发起调用,当出现失败后,重试其他服务器。通常用于读操作,但重试会带来更长时间的延迟。重试的次数通常是可以设置的
失败安全
失败安全, 当服务调用出现异常时,直接忽略。通常用于写入日志等操作。
失败自动恢复
当服务调用出现异常时,记录失败请求,定时重发。通常用于消息通知
forking Cluster
并行调用多个服务器,只要有一个成功,即返回。通常用于实时性较高的读操作。可以通过forks=n来设置最大并行数
广播调用
广播调用所有提供者,逐个调用,任何一台失败则失败。通常用于通知所有提供者更新缓存或日志等本地资源信息
熔断
熔断技术可以说是一种“智能化的容错”,当调用满足失败次数,失败比例就会触发熔断器打开,有程序自动切断当前的RPC调用,来防止错误进一步扩大。
主要是考虑三种模式:关闭,打开,半开
限流和降级
保证核心服务的稳定性。为了保证核心服务的稳定性,随着访问量的不断增加,需要为系统能够处理的服务数量设置一个极限阀值,超过这个阀值的请求则直接拒绝。同时,为了保证核心服务的可用,可以对否些非核心服务进行降级,通过限制服务的最大访问量进行限流,通过管理控制台对单个微服务进行人工降级
SLA
SLA:Service-LevelAgreement的缩写,意思是服务等级协议。 是关于网络服务供应商和客户间的一份合同,其中定义了服务类型、服务质量和客户付款等术语
API网关
将所有API调用统一接入到API网关层,有网关层统一接入和输出。一个网关的基本功能有:统一接入、安全防护、协议适配、流量管控、长短链接支持、容错能力。有了网关之后,各个API服务提供团队可以专注于自己的的业务逻辑处理,而API网关更专注于安全、流量、路由等问题。
多级缓存
最简单的缓存就是查一次数据库然后将数据写入缓存比如redis中并设置过期时间
因为有过期失效因此我们要关注下缓存的穿透率,这个穿透率的计算公式
超时和重试
超时与重试机制也是容错的一种方法,凡是发生RPC调用的地方,比如读取redis,db,mq等,因为网络故障或者是所依赖的服务故障,长时间不能返回结果,就会导致线程增加,加大cpu负载,甚至导致雪崩。所以对每一个RPC调用都要设置超时时间。
线程池隔离
线程隔离的之间优势就是防止级联故障,甚至是雪崩。