提取Ceph O版的所有参数分析
https://blog.csdn.net/qq_67736058/article/details/137922219
结合 src/common/legacy_config_opts.h 再查看
Ceph 参数配置分为运行时生效与启动时生效的参数,
对于运行时生效的参数,在 ceph 创建后一直保存在进程中,只有相关事件才会触发对这些参数的访问,因此只要修改进程所链接的文件,就可认为这些参数的修改已实时生效
对于启动时生效的函数,只有在 ceph 进程创建时才会起作用,如:只有在创建 osd 进程时,才会通过 osd_op_num_shards *osd_op_num_threads_per_shard 计算线程数并向操作系统申请。在 OSD 进程创建之后,即使调整这些参数也不会生效,所以这才是一些参数重启才会生效的真正原因。
参数查看
提取所有参数
1 | touch O_conf.txt # 创建保存参数的文件 |
查看指定参数的值
1 | 获取参数默认值 |
源码查看参数
https://blog.csdn.net/huangwenhuan/article/details/130411626
Ceph中所有可配置的参数都定义在 src/common/legacy_config_opts.h 中,
参数在Ceph中以结构体形式保存,定义在 src/common/options.h 中
1 | struct Option { |
在 src/common/options.cc 中,有参数的具体帮助信息
1 | static std::vector<Option> build_options() |
get_global_options()基本所有的模块都可以使用这些参数。get_rgw_options()函数中的参数是给rgw模块使用。get_rbd_options()函数和get_rbd_mirror_options()函数中的参数是给rbd相关模块使用。get_mds_options()函数中的参数是给mds模块使用。get_mds_client_options()函数中的参数是给mds client模块使用。
1 | const std::vector<Option> ceph_options = build_options(); |
ceph_options这个向量包含了所有的参数,在任何地方,可以通过 md_config_t 这个结构体查看当前Ceph的参数配置
1 | src/common/config.h |
参数修改
通过 ceph daemon 查看运行中进程的参数配置值或修改这些参数。永久配置方式,就是在配置文件 ceph.conf 中添加该参数配置,重启进程后,参数才生效。临时方式,就是通过 ceph daemon 设置内存中的参数。
1 | 在N版以上,可以config set持久化配置,重启后生效 |
https://blog.csdn.net/m0_59586152/article/details/127925028
1 | xxx为 admin_socket = $rundir/$cluster-$id.asok (/run/ceph/ceph-osd.0.asok) |
若持久化,需要写入配置文件;同步配置文件;重启mon服务
写入
ceph.conf1
2
3
4
5
6
7
8
9
10
11[global]
fsid = 4b0fbef4-9617-41d1-94f4-05efb32d5d32
mon_initial_members = node-1
mon_host = 10.0.0.92
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
auth_allow_insecure_global_id_reclaim = false
public_network = 10.0.0.0/24
cluster_network = 10.0.0.0/24
mon_allow_pool_delete = true同步配置文件
1
ceph-deploy --overwrite-conf config push node1 xxx
重启mon服务
1
for I in {1..xxx}: do ssh node${I} systemctl restart ceph-mon.target;done
内核参数修改——避免成为瓶颈
1 | kernel pid max, |
1 | 通过数据预读并且记载到随机访问内存方式提高磁盘读操作 |
PG 数计算公式
1 | Total PGs = (Total_number_of_OSD * 100) / max_replication_count |
Ceph配置经验
https://www.yangguanjun.com/2017/05/15/Ceph-configuration/
引导参数
1 | 通常是通过ceph-deploy生成的,都是ceph monitor相关的参数,不用修改; |
http://docs.ceph.com/docs/master/rados/configuration/network-config-ref/
public network:monitor与osd,client与monitor,client与osd通信的网络,最好配置为带宽较高的万兆网络;
cluster network:OSD之间通信的网络,一般配置为带宽较高的万兆网络;
1 | 认证配置参数 |
默认值为开启ceph认证;
在内部使用的ceph集群中一般配置为none,即不使用认证,这样能适当加快ceph集群访问速度;
global参数
objecter
1 | objecter_inflight_ops = 10240 默认值 1024 |
osd client端objecter的throttle配置,它的配置会影响librbd,RGW端的性能;
配置建议: 调大这两个值
debug
每一个Ceph子系统有自己的输出日志等级,并记录在内存中。
可以给日志设置一个log文件等级和内存等级,第一个设置是日志等级,第二个配置是内存等级 debug<subsystem> = <log-level>/<memory-level>
1 | debug_lockdep = 0/0 |
关闭了所有的debug信息,能一定程度加快ceph集群速度,但也会丢失一些关键log,出问题的时候不好分析;
osd相关参数
osd pool
1 | pool size配置参数 |
osd down
1 | ceph标记一个osd为down and out的最大时间间隔 |
基于实际情况合理配置上述参数,能减少或及时发现osd变为down(降低IO hang住的时间和概率),延长osd变为down and out的时间(防止网络抖动造成的数据recovery);
osd op
1 | osd_enable_op_tracker = false 默认值 true |
osd_enable_op_tracker:追踪osd op状态的配置参数,默认为true;不建议关闭,关闭后osd的 slow_request,ops_in_flight,historic_ops 无法正常统计;
打开op tracker后,若集群iops很高,osd_num_op_tracker_shard可以适当调大,因为每个shard都有个独立的mutex锁;
osd_op_threads:对应的work queue有peering_wq(osd peering请求),recovery_gen_wq(PG recovery请求);osd_disk_threads:对应的work queue为 remove_wq(PG remove请求);osd_op_num_shards和osd_op_num_threads_per_shard:对应的thread pool为osd_op_tp,work queue为op_shardedwq;
处理的请求包括:
OpRequestRefPGSnapTrimPGScrub
调大osd_op_num_shards可以增大osd ops的处理线程数,增大并发性,提升OSD性能;
osd client message
1 | client data allowed in-memory (in bytes) |
这个是osd端收到client messages的capacity配置,配置大的话能提升osd的处理能力,但会占用较多的系统内存;
配置建议:
服务器内存足够大的时候,适当增大这两个值
osd scrub
1 | osd_scrub_begin_hour = 2 默认值 0 |
Ceph osd scrub是保证ceph数据一致性的机制,scrub以PG为单位,但每次scrub会获取PG lock,所以它可能会影响PG正常的IO;
Ceph后来引入了chunky的scrub模式,每次scrub只会选取PG的一部分objects,完成后释放PG lock,并把下一次的PG scrub加入队列;这样能很好的减少PG scrub时候占用PG lock的时间,避免过多影响PG正常的IO;
同理,引入的osd_scrub_sleep参数会让线程在每次scrub前释放PG lock,然后睡眠一段时间,也能很好的减少scrub对PG正常IO的影响;
配置建议:
osd_scrub_begin_hour和osd_scrub_end_hour:OSD Scrub的开始结束时间,根据具体业务指定;osd_scrub_sleep:osd在每次执行scrub时的睡眠时间;有个bug跟这个配置有关,建议关闭;osd_scrub_load_threshold:osd开启scrub的系统load阈值,根据系统的load average值配置该参数;osd_scrub_chunk_min和osd_scrub_chunk_max:根据PG中object的个数配置;针对RGW全是小文件的情况,这两个值需要调大;
参考:
http://www.jianshu.com/p/ea2296e1555c
http://tracker.ceph.com/issues/19497
osd thread timeout
1 | osd_op_thread_timeout = 580 默认值 15 |
osd_op_thread_timeout和osd_op_thread_suicide_timeout关联的work queue为:
op_shardedwq- 关联的请求为:OpRequestRef,PGSnapTrim,PGScrubpeering_wq- 关联的请求为:osd peering
osd_recovery_thread_timeout和osd_recovery_thread_suicide_timeout关联的work queue为:
recovery_wq- 关联的请求为:PG recovery
1 | /// Pool of threads that share work submitted to multiple work queues. |
这里的 timeout_interval 和 suicide_interval 分别对应上面所述的配置 timeout 和 suicide_timeout ;
当thread处理work queue中的一个请求时,会受到这两个timeout时间的限制:
timeout_interval- 到时间后设置m_unhealthy_workers+1suicide_interval- 到时间后调用assert,OSD进程crush
对应的处理函数为:
1 | bool HeartbeatMap::_check(const heartbeat_handle_d *h, const char *who, time_t now) |
当前仅有RGW添加了worker的perfcounter,所以也只有RGW可以通过perf dump查看total/unhealthy的worker信息:
1 | [root@ yangguanjun]# ceph daemon /var/run/ceph/ceph-client.rgw.rgwdaemon.asok perf dump | grep worker |
配置建议:
*_thread_timeout:这个值配置越小越能及时发现处理慢的请求,所以不建议配置很大;特别是针对速度快的设备,建议调小该值;*_thread_suicide_timeout:这个值配置小了会导致超时后的OSD crush,所以建议调大;特别是在对应的throttle调大后,更应该调大该值;
bluestore
osd_op_num_shards
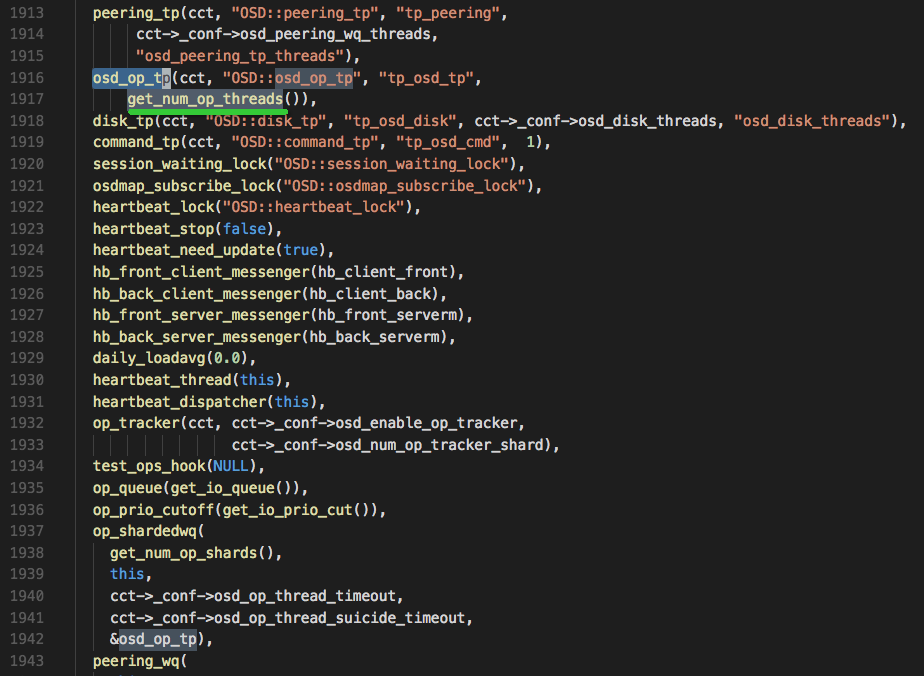
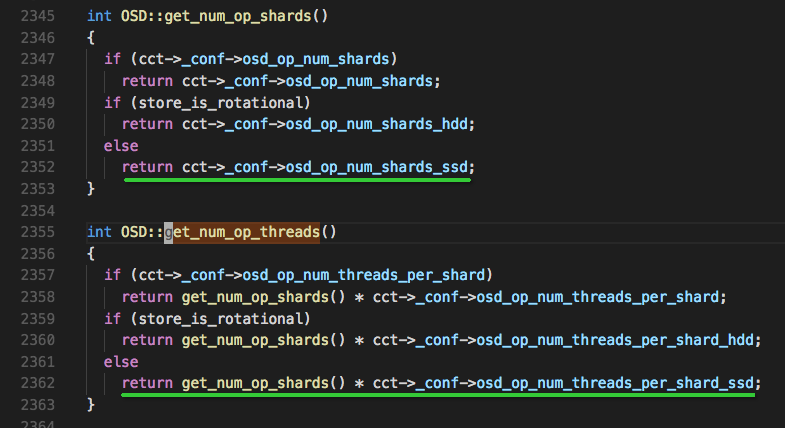
get_num_op_shards() 获取OSD::op_shardedwq中存储操作的队列个数
- 当osd_op_num_shards为true时,返回osd_op_num_shards的值
- 否则就看返回osd_op_num_shards_hdd或osd_op_num_shards_ssd的值
- store_is_rotational是bool类型,表示设备属性(默认是true也即是hdd)
get_num_op_threads(),获取OSD::op_shardedwq中每个队列的操作分发线程数
总线程数=队列数*每个队列线程数
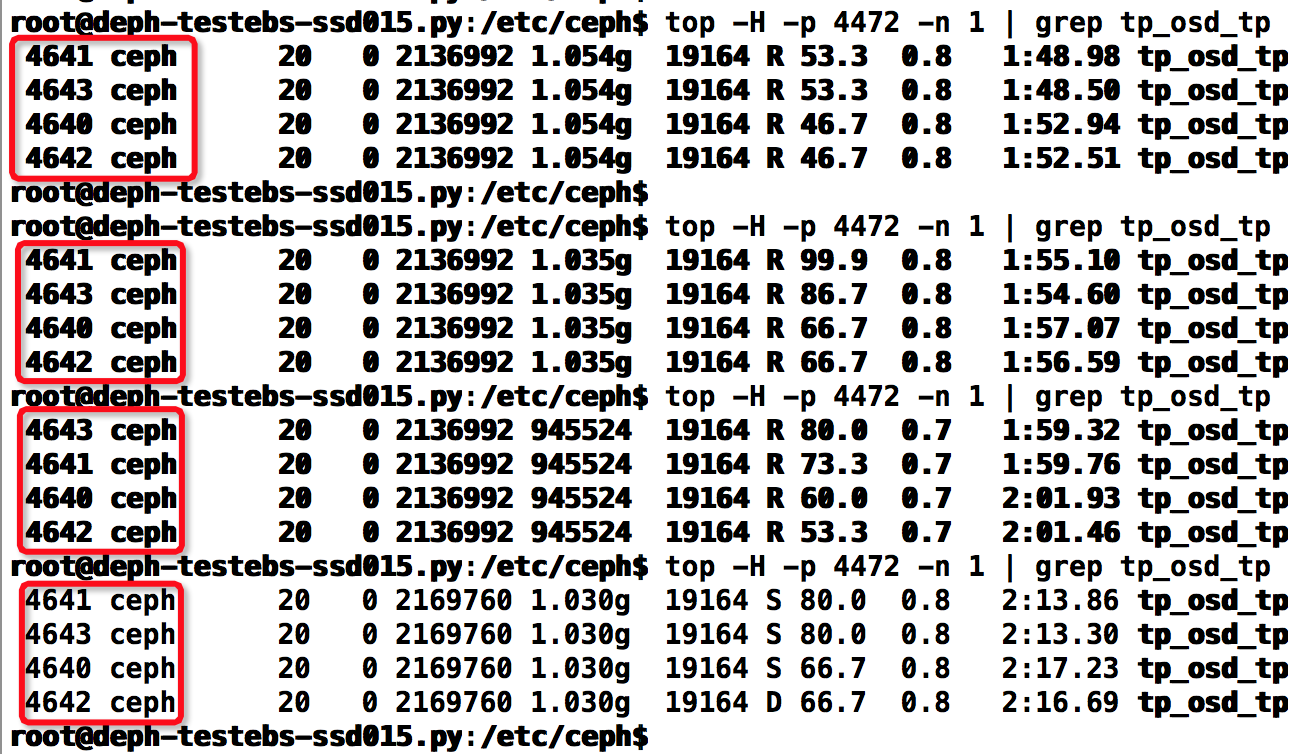
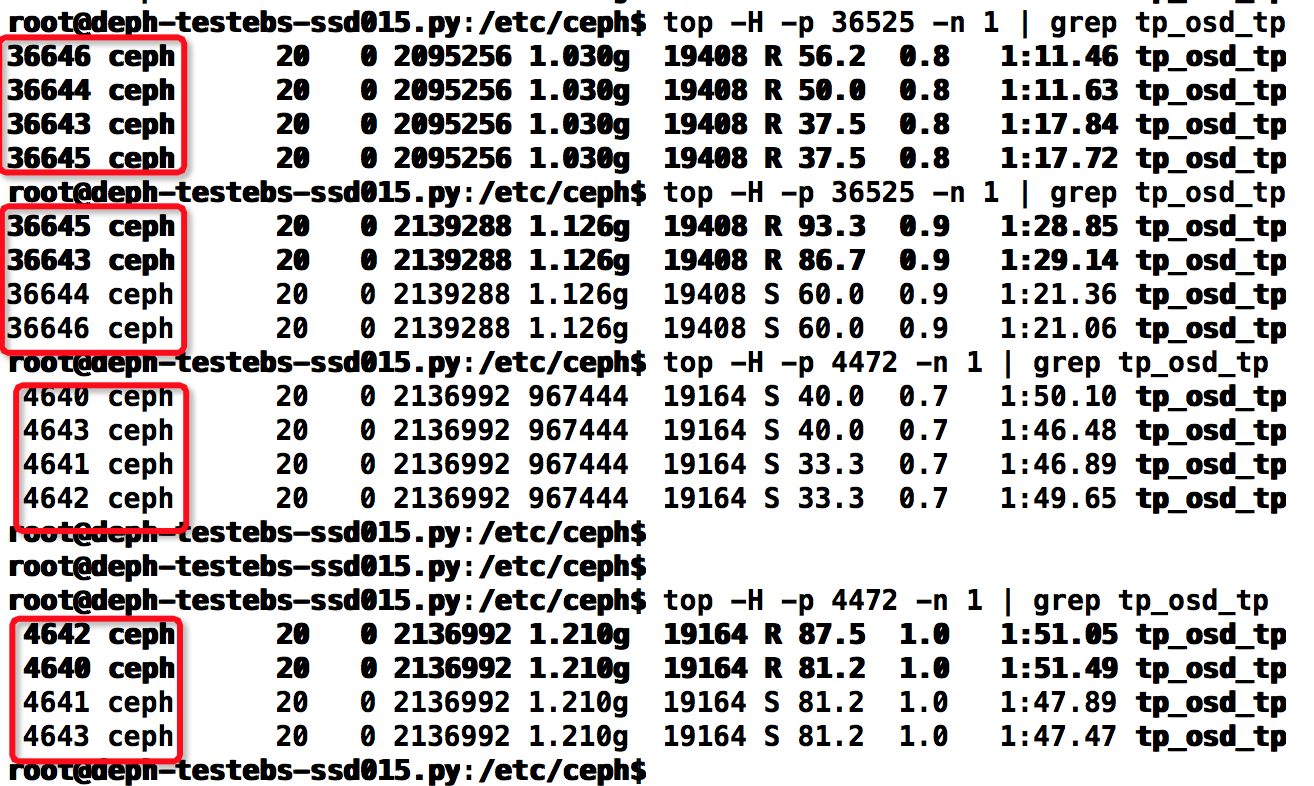
总线程数=osd_op_num_shards_ssd*osd_op_num_threads_per_shard_ssd=2*2=4
在客户端运行fio的4k-randwrite操作,同时在服务端多次运行 top -H -p $pid -n 1 | grep tp_osd_tp ,计算有多少个线程,看得出一直都是4个线程

filestore
filestore merge/split
1 | filestore_merge_threshold = -1 默认值 10 |
这两个参数是管理filestore的目录分裂/合并的,filestore的每个目录允许的最大文件数为:filestore_split_multiple * abs(filestore_merge_threshold) * 16
在RGW的小文件应用场景,会很容易达到默认配置的文件数(320),若在写的过程中触发了filestore的分裂,则会非常影响filestore的性能;
每次filestore的目录分裂,会依据如下规则分裂为多层目录,最底层16个子目录:
原始目录下的object会根据规则放到不同的子目录里,object的名称格式为: *__head_xxxxX4C0_*,分裂时候X是几,就放进子目录DIR_X里。比如object:*__head_xxxxA4C0_*, 就放进子目录 DIR_0/DIR_C/DIR_4/DIR_A 里;
解决办法:
- 增大merge/split配置参数的值,使单个目录容纳更多的文件;
filestore_merge_threshold配置为负数;这样会提前触发目录的预分裂,避免目录在某一时间段的集中分裂,详细机制没有调研;- 创建pool时指定
expected-num-objects;这样会依据目录分裂规则,在创建pool的时候就创建分裂的子目录,避免了目录分裂对filestore性能的影响;
filestore fd cache
1 | filestore_fd_cache_shards = 32 默认值 16 // FD number of shardsfilestore_fd_cache_size = 32768 默认值 128 // FD lru size |
filestore的fd cache是加速访问filestore里的file的,在非一次性写入的应用场景,增大配置可以很明显的提升filestore的性能;
filestore sync
1 | # SSD的时候建议关闭, 默认值 true |
filestore_wbthrottle_enable的配置是关于filestore writeback throttle的,即我们说的filestore处理workqueue op_wq的数据量阈值;默认值是true,开启后XFS相关的配置参数有:
1 | OPTION(filestore_wbthrottle_xfs_bytes_start_flusher, OPT_U64, 41943040) |
若使用普通HDD,可以保持其为true;针对SSD,建议将其关闭,不开启writeback throttle;
filestore_min_sync_interval和filestore_max_sync_interval是配置filestore flush outstanding IO到disk的时间间隔的;增大配置可以让系统做尽可能多的IO merge,减少filestore写磁盘的压力,但也会增大page cache占用内存的开销,增大数据丢失的可能性;
filestore_commit_timeout是配置filestore sync entry到disk的超时时间,在filestore压力很大时,调大这个值能尽量避免IO超时导致OSD crush;
filestore throttle
1 | # Expected filestore throughput in B/s |
在jewel版本里,引入了dynamic throttle,来平滑普通throttle带来的长尾效应问题;
一般在使用普通磁盘时,之前的throttle机制即可很好的工作,所以这里默认filestore_queue_high_delay_multiple和filestore_queue_max_delay_multiple都为0;
针对高速磁盘,需要在部署之前,通过小工具ceph_smalliobenchfs来测试下,获取合适的配置参数;
1 | BackoffThrottle的介绍如下: |
参考:
http://docs.ceph.com/docs/jewel/dev/osd_internals/osd_throttles/
http://blog.wjin.org/posts/ceph-dynamic-throttle.html
https://github.com/ceph/ceph/blob/master/src/doc/dynamic-throttle.txt
Ceph BackoffThrottle分析
filestore finisher threads
1 | filestore_ondisk_finisher_threads = 2 默认值 1 |
这两个参数定义filestore commit/apply的finisher处理线程数,默认都为1,任何IO commit/apply完成后,都需要经过对应的ondisk/apply finisher thread处理;
在使用普通HDD时,磁盘性能是瓶颈,单个finisher thread就能处理好;
但在使用高速磁盘的时候,IO完成比较快,单个finisher thread不能处理这么多的IO commit/apply reply,它会成为瓶颈;所以在jewel版本里引入了finisher thread pool的配置,这里一般配置为2即可;
journal
1 | journal_max_write_bytes=1048576000 默认值 10M |
journal_max_write_bytes和journal_max_write_entries是journal一次write的数据量和entries限制;
针对SSD分区做journal的情况,这两个值要增大,这样能增大journal的吞吐量;
journal_throttle_high_multiple和journal_throttle_max_multiple是JournalThrottle的配置参数,JournalThrottle是BackoffThrottle的封装类,所以JournalThrottle与我们在filestore throttle介绍的dynamic throttle工作原理一样;
rbd cache
1 | [client] |
rbd_cache_size:client端每个rbd image的cache size,不需要太大,可以调整为64M,不然会比较占client端内存;
参照默认值,根据rbd_cache_size的大小调整rbd_cache_max_dirty和rbd_cache_target_dirty;
rbd_cache_max_dirty:在writeback模式下cache的最大bytes数,默认是24MB;当该值为0时,表示使用writethrough模式;rbd_cache_target_dirty:在writeback模式下cache向ceph集群写入的bytes阀值,默认16MB;注意该值一定要小于rbd_cache_max_dirty值
rbd_cache_writethrough_until_flush:在内核触发flush cache到ceph集群前rbd cache一直是writethrough模式,直到flush后rbd cache变成writeback模式;rbd_cache_max_dirty_age:标记OSDC端ObjectCacher中entry在cache中的最长时间;
https://my.oschina.net/linuxhunter/blog/541997
ceph rgw
1 | # 默认值 "fastcgi, civetweb port=7480" |
rgw_frontends:rgw的前端配置,一般配置为使用轻量级的civetweb;prot为访问rgw的端口,根据实际情况配置;num_threads为civetweb的线程数;rgw_thread_pool_size:rgw前端web的线程数,与rgw_frontends中的num_threads含义一致,但num_threads 优于rgw_thread_pool_size的配置,两个只需要配置一个即可;rgw_override_bucket_index_max_shards:rgw bucket index object的最大shards数,增大这个值能减少bucket index object的访问时间,但也会加大bucket的ls时间;rgw_max_chunk_size:rgw最大chunk size,针对大文件的对象存储场景可以把这个值调大;rgw_cache_lru_size:rgw的lru cache size,对于读较多的应用场景,调大这个值能加快rgw的响应速度;rgw_bucket_default_quota_max_objects:配合该参数限制一个bucket的最大objects个数;
参考:
http://docs.ceph.com/docs/jewel/install/install-ceph-gateway/
http://ceph-users.ceph.narkive.com/mdB90g7R/rgw-increase-the-first-chunk-size
https://access.redhat.com/solutions/2122231