[TOC]
原理
全概率公式
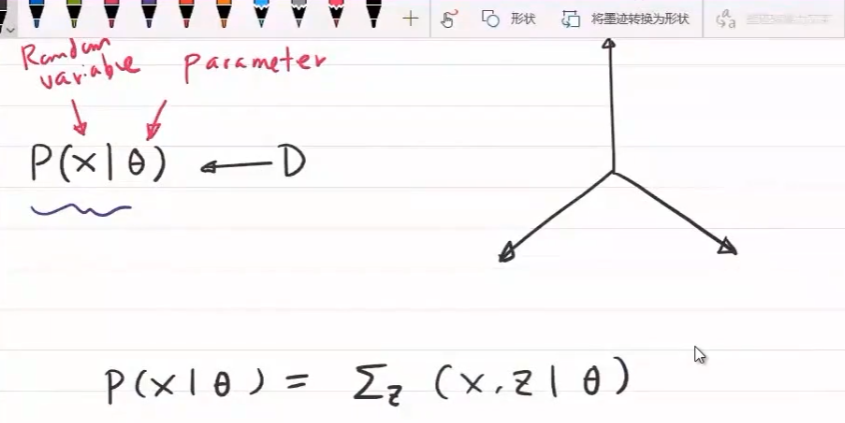
全概率公式:假设事件的发生受某一隐含变量的影响,可通过贝叶斯推断建立模型
若推测 $X$ 与 $Z$ 之间存在隐含关系,则存在似然概率 $P(X\vert Z)$
假设 $Z$ 服从某种先验分布,则可以通过关闭数据用和初始参数推断出先验概率 $P(Z)$
贝叶斯
频率派:从统计意义上,表示事件发生的可能性
贝叶斯派:概率为通过经验对时间的不确定性进行度量,表示对事件的信任程度
即使一个事件的先验概率很大,若似然概率很小,则后验概率也可能很小
对于数据集 $D\{(X_1,y_1),(X_2,y_2),\cdots,(X_N,y_N)\}$ ,且满足$f(X_i)\rightarrow y_i$,估计后验概率 $P(y\vert X)$
- 似然概率 $L(\mu;\sigma)=\prod\limits_{i=1}^N P(X_i\vert \mu,\sigma)\Rightarrow \sum\limits_{i=1}^N \log P(X_i\vert \mu,\sigma)$
则有,
通过贝叶斯推断隐变量与概率分布的关系
二项分布
$\theta$ 表示正面为1的概率大小
多次投掷硬币为N重伯努利实验
N重伯努利实验结果
混合伯努利模型
假设结果与某一隐变量有关,每次结果出现两种输出 $Z=\{0,1\}$
参数模型:
z为控制y发生的隐变量
由于:
上述为二模态混合模型,每次实验常数权重 $\pi$ 选择实验结果的概密
对于多模态混合模型,每次实验都有各自的权重/概密
对于每一次的结果,需要了解由哪部分概密得出,才可以对三个参数进行估计
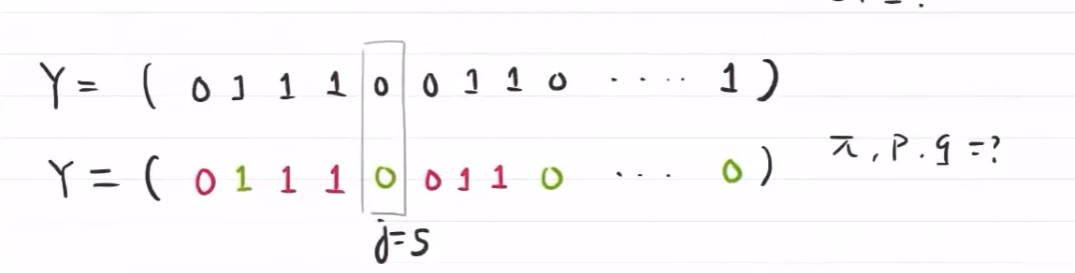

E step
对每个隐含状态,估计每种结果来源概密的权重
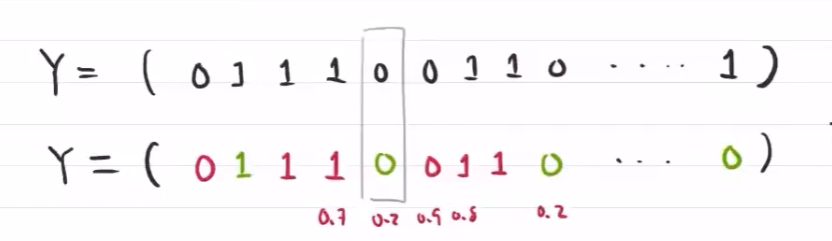
用参数 $\mu$ 估计每个数据的来源概密 $Q(z_i)=P(z_i\vert x_i,\theta)$
表示第j个数据,多大概率由 $Q(z_i)$ 概密得出
M step
在给定权重的条件下,求参数的极大似然值
对参数 $\pi$ 估计
随机给定初始值 $(\pi_0,p_0,q_0)$ ,再根据初始值计算 $\mu_j$ ,根据来源密度估计 $p,q$
$P=\frac{P概密中1的结果份数}{P概密中的所有结果份数}$
二项伯努利混合模型
给参数赋随机值
E step:求在给定隐含变量值前提下的,事件发生的期望,根据初始值估计来源概密
M step:求参数最大化,估计参数
迭代,直至参数稳定
EM 算法 期望最大化算法
Jensen不等式
函数的期望与期望的函数大小关系
对于凸函数,函数值小于均值,故期望的函数值比较小,即函数的期望大于期望的函数
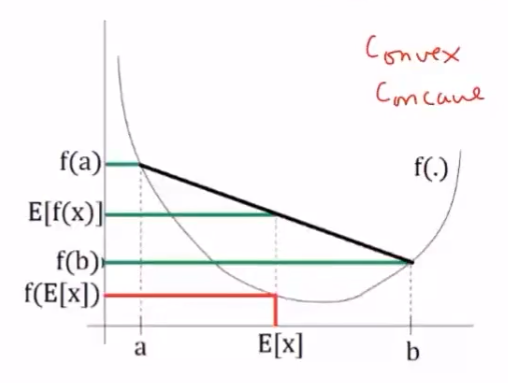
线性函数为期望函数,凸函数为f(x)
对于凹函数,$E[f(x)]\le f(E[X])$
EM算法
- 计算完全数据的对数似然期望
- 最大化期望
目标:在假设参数 $\theta^{(j)}$ 的前提下,使不完全数据发生的期望最大化
在已知 $X$ 与隐变量 $Z$ 相关的前提下
- $X$ :观测数据,不完全数据
- $Z$ :隐变量
- $\theta$ :模型的参数
E step
假设参数初始值 $\theta^{(0)}$ ,不完全数据发生的期望 $\propto$ 完全数据的对数期望
在参数 $\theta^{(j)}$ 与观测数据 $X$ 下,找到隐变量的条件概率 $P(Z\vert X,\theta^{(j)})$
在有结果时,哪个模型得到的概率可计算
得到X,Z联合概率 $P(X,Z\vert \theta^{(j)})$
似然概率与隐变量的关系
由于 $P(Z_i\vert X_i,\theta^{(j)})$ 确定,故似然概率正比于
M step
最大化完全数据的对数期望 $\iff$ 最大化似然概率
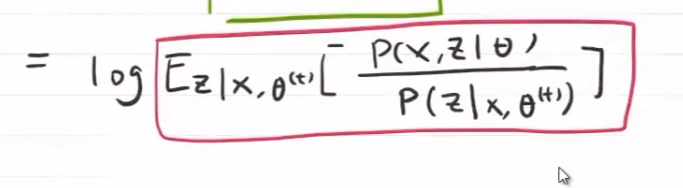
进一步泛化,假设每个数据来源概密的权重 $Z_{i}$ 服从 $Q(Z_{i})$ 分布,$ Q(Z_{i})$ 表示 $Z_{i}$ 服从的概率分布,$\sum_{Z_{i}} Q(Z_{i})f(Z_{i})=E_Z[f(Z_{i})]$ :在给定观测数据 $X$ 与当前参数值 $\theta^{(j)}$ 前提下,对隐变量 $Z$ 的条件概率的期望 $\Rightarrow$ 完全数据的对数期望
完成一次参数迭代 $\theta^{(j)}\rightarrow \theta^{(j+1)}$ ,似然函数会增大或达到局部最大
一些特性
当数据均匀分布时,期望最大
即 $\frac{P(X_1,Z_1\vert \theta^{(j)})}{P(Z_1\vert X_1,\theta^{(j)})}=\frac{P(X_2,Z_2\vert \theta^{(j)})}{P(Z_2\vert X_2,\theta^{(j)})}=\cdots=\frac{P(X_N,Z_N\vert \theta^{(j)})}{P(Z_N\vert X_N,\theta^{(j)})}$
在已知 $\sum_ZQ_i(Z_i)=1$ 的前提下,可假设Z的分布
E step:对于每个i,
M step:
给定Z时,每个部分的最优值
E-step
M-step:
基于高斯混合模型的EM算法
高斯混合模型
K个高斯 $\mathcal{N}(\mu_1,\sigma^2_1),\mathcal{N}(\mu_2,\sigma^2_2),\cdots,\mathcal{N}(\mu_K,\sigma^2_K)$ ,混合权重为 $\alpha_1,\cdots,\alpha_K$ (表示来源于各高斯模型的样本比例),且 $\sum\alpha_i=1$
若已知 $\alpha_i$ 且样本属于哪个 $\mathcal{N}$ 已知,则可用样本与参数得到模型的参数
实际问题 :只有观测数据 $X_1,\cdots,X_N$ ,$Z$:隐变量,样本归属的高斯混合模型
建模:
其中,$\theta=\{\mu_1,\sigma_1;\mu_2,\sigma_2;\cdots,\mu_N,\sigma_N\}$ ,第 $k$ 个模型的概率密度为 $Q(X)=\frac{1}{\sqrt{2\pi} \sigma_k}e^{-\frac{(X-\mu_k)^2}{2\sigma_k^2}}$
隐变量 $Z_{i1},Z_{i2},\cdots,Z_{iK}$ 控制第 $i$ 个观测数据 $X_i$ 的高斯混合系数
因此,隐变量矩阵
参数为 $\theta=(\alpha_1,\mu_1,\sigma_1;\alpha_2,\mu_2,\sigma_2;\cdots;\alpha_K,\mu_K,\sigma_K)$
联合概率分布
似然概率
对隐变量求期望
$\hat{n}_k=\sum\limits_{j=1}^N\hat{z}_{jk}$
E-step
在已知 $\theta^{(i)}$ 的前提下,对隐变量 $\hat{z}_{jk},\hat{n}_k$ 求期望
找到M-step的目标函数
EM收敛性

t表示迭代
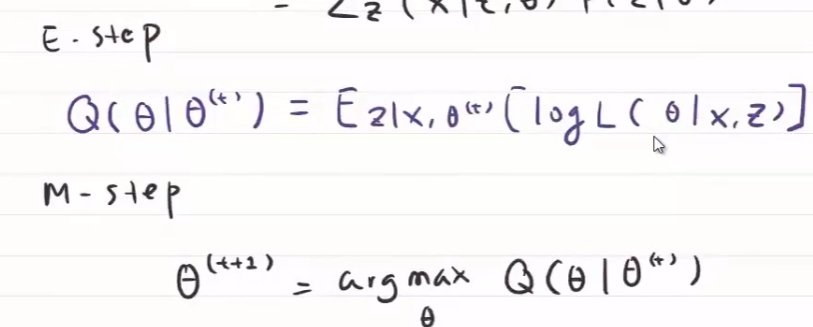
- z服从什么分布时,E最大
不断调整 \theta ,使似然概率最大
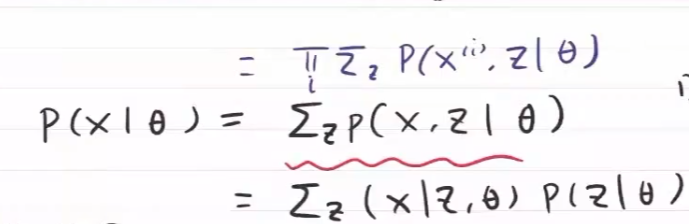


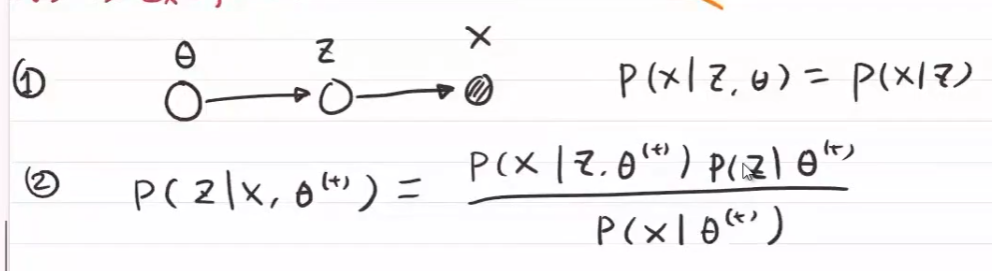

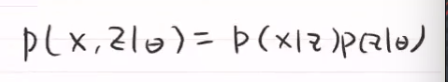

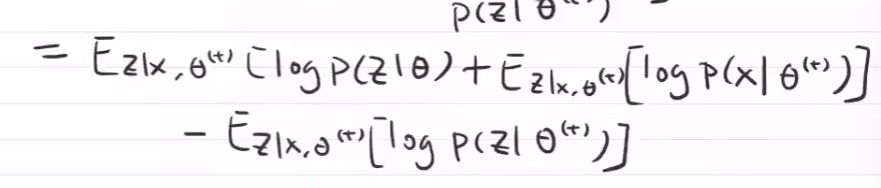
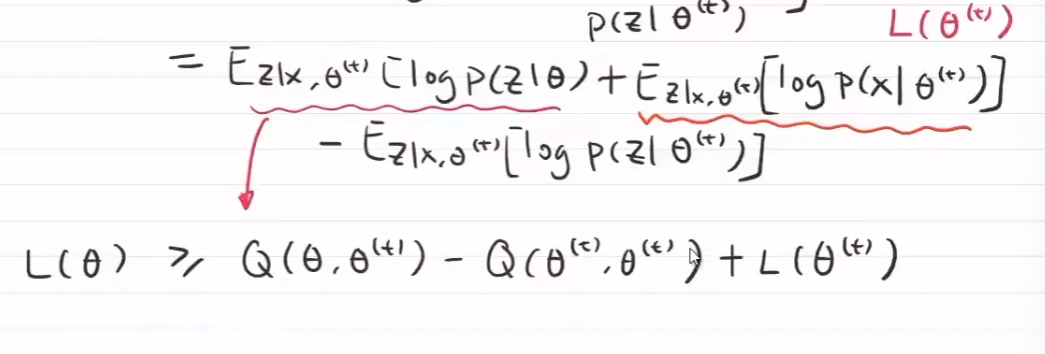
后俩项,在参数给定时是一个常数,$Q(\theta,\theta^{(t)})$ ,\theta可以根据上一时刻的值进行调整,使Q()变大,使L(\theta)上升和提高
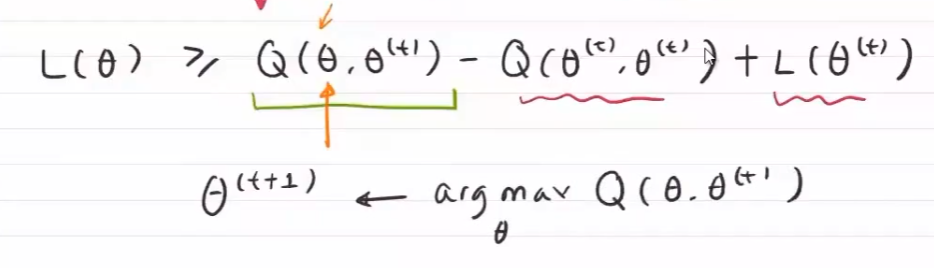
使Q的极大似然值最大时的 $\theta$ 为下一时刻的 $\theta$
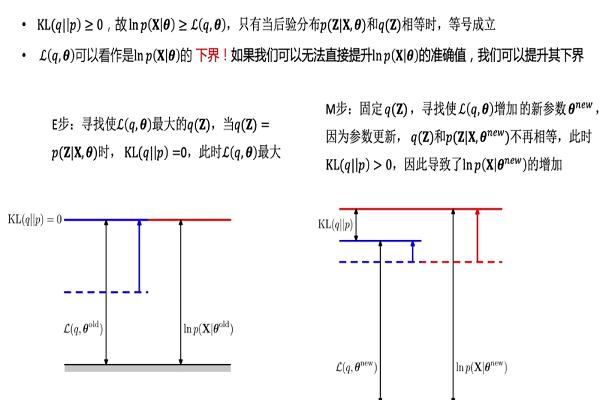
EM算法用来解决观测数据不完全时,对模型的参数估计问题。
目标是在给定参数 $\theta^{old}$ 和观测数据 $X$ 给定下,使非完全数据的对数似然函数 $lnP(X\vert \theta^{old})$ 取最大值
$Q(q,\theta^{old})= E_{Z\vert X,\theta^{old}}[lnP(X,Z\vert \theta^{old})]$ 即完全数据的对数似然函数,关于“隐变量Z的条件概率分布 $P(Z\vert \theta^{old},X)$” 的期望。由 $KL(q||p)\ge 0\Rightarrow lnP(X\vert \theta)\ge Q(q,\theta)$,可用 $Q(q,\theta^{old})$ 作为非完全数据对数似然函数 $lnP(X\vert \theta^{old})$ 的下界
E step
在固定参数 $\theta^{old}$ 和已知观测数据 $X$ 条件下,找出使完全数据对数似然函数的期望 $Q(q,\theta^{old})$ 的最大的隐变量 $Z$ 的条件概率分布 $q(Z)=\mathop{max}\limits_{z}\{P(Z\vert X,\theta^{old})\}$ ,此时 $KL(q||p)=0$
M step
在固定 $q(Z)$ 时,调节参数 $\theta$ ,最大化 $Q(q,\theta^{new})$ ,即完全数据的似然函数,关于 “给定参数 $\theta^{old}$ 和观测数据 $X$ 的条件下,隐变量Z的条件概率分布 $P(Z\vert \theta^{old},X)$ ”的期望最大化。由于参数的更新,$q(Z)$ 与 $P(Z\vert X,\theta^{new})$ 不在相等,即 $KL(q||p)>0$ ,导致了非完全数据对数似然函数 $P(X\vert \theta^{new})$ 增大