[TOC]
4.1 模型选择、欠拟合、过拟合
4.1.1 模型选择
数据集
验证集 :用于选择模型超参数,进行超参数组合的确定与模型结构的调整
训练集与验证集:实际上,开源数据集是在网络上都是能找到的,所以网络上随便的数据集都不能作为验证集
用于验证的数据集在训练过程中不能被使用
验证集与测试集:
参数调优是基于验证集的,若对测试数据集多次使用则也会变为验证集。验证数据集上的性能不等于测试数据集上的泛化性能
测试数据集,只能使用一次,在测试数据集上的表现用于评价为模型的泛化性能
验证方法
简单验证
简单验证: 将原始数据集随机划分成训练集和验证集两部分
- 例,将数据按照7:3的比例分成两部分,70%的样本用于训练模型;30%的样本用于模型验证。
缺点:
- 数据都只被用了一次
- 模型并不是完全训练集上得到的,并没有充分学习训练集
- 验证集上计算出来的评估指标与原始分组有很大关系;
K-折交叉验证

下一折的训练并不是在上一折的基础上训练,即每训练新的一折,都要重新初始化参数进行训练
K折交叉验证只能做验证使用,因此不能根据它的结果做为模型参数的保存判断依据,但可以基于它做超参组合的确定与模型结构的调整,然后再重新初始化模型,进行训练得到较好的模型参数。
对于有时序信息的数据,要看看不同折之间性能表现会不会有明显差距
K的选择
K越大,则K-折平均训练误差接近训练集上的真实误差
- n折交叉验证有多少个数据意味着一轮训练需要计算多少次
K折交叉验证一次,$总训练轮数=每折训练轮数(epochs)\times 总折数(K)$
意味着:K越大,计算代价越大。训练成本会翻K倍
数据规模越大,K可以取越小;数据规模越小,K需要取越大
4.1.2 过拟合、欠拟合
模型容量:表示模型的拟合能力,模型容量越大,可以拟合更复杂的函数
数据:简单数据 / 复杂数据集
根据数据的复杂程度选择模型容量

简单数据、复杂模型:会将训练数据全部拟合,造成模型泛化能力差
复杂数据、简单模型:未能学习到训练数据的全部特征
PLA为例,对于异或学习太简单;改用多层PLA,可以学习数据的更多信息,从而很好拟合数据
模型容量与误差关系
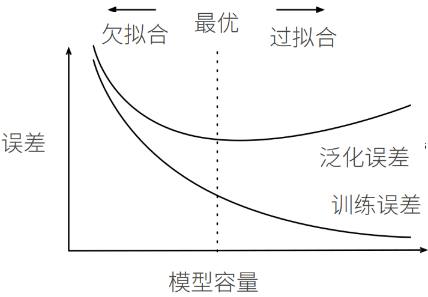
简单模型,模型容量差,拟合能力上限,会造成欠拟合
复杂模型,模型容量高,数据集越小,模型容量越高,越容易造成过拟合
为尽可能降低泛化误差,需要承受一定的过拟合风险
通过各种技巧,控制模型容量,使得泛化误差尽可能降低
实际中,通过训练误差与验证误差的差距来调整模型容量
估计模型容量
对于不同的算法,不同种类的算法比较模型容量很难
- 树模型与神经网络结构上不同,所以很难比较
对于一个确定的学习算法,(如:神经网络),主要有两个主要因素:
参数个数
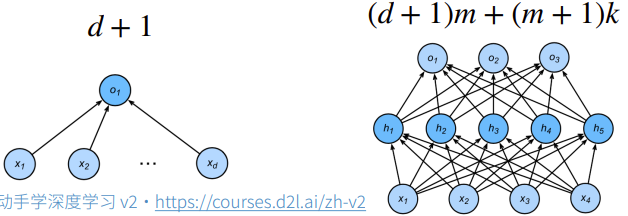
参数取值范围
参数个数越多,参数取值范围越大,则认为模型容量越高
模型理论容量—VC维
对于一个分类模型,VC维等于该模型最大可分类数据集的大小。即对于一个确定的数据集容量,不管数据集中输入特征、输出标签如何变化,该分类模型都存在一个参数组合能将该数据集完美分类,则将这个数据集容量称为VC维
二维输入的PLA,数据有两个维度
参数也有2个维度,其VC维=3
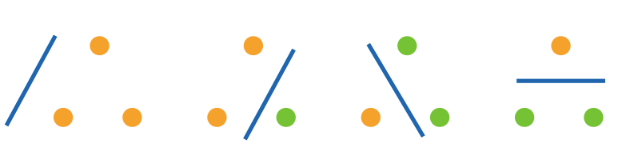
对于异或学习,二维输入的PLA显然不能学习

N维输入的PLA,输入数据有N维,参数也有N个维度,其VC维=N+1
一些MLP的VC维为 $O(N\log_2 N)$
VC维提供了一个模型参数结构好坏的理论评价依据,但深度学习很少用
- 衡量不是很准确,只是模型容量的下界
- 深度学习模型的VC维很难
数据复杂度
- 样本个数
- 每个样本的元素个数
- 样本/元素间的时间、空间结构
- 数据多样性(数据标签个数)
数据复杂度只是直观上的感觉,与先前的训练过的数据集对比,复杂一点,用模型容量高点的模型;数据复杂度简单一点,用模型容量低点的模型
4.1.3 直观理解
构造数据集
生成多项式的随机数据
噪音 $\varepsilon$ 服从均值为0,方差为 $0.1^2$ 的正态分布
- 使用泰勒多项式的好处:$\frac{x^i}{i!}$ 可以避免很大的 $i$ 带来特别大的指数值
1 | import math |
1 | max_degree = 20 # 多项式的最大阶数 |
1 | for i in range(max_degree): |
计算每个项的 $\frac{f_j^i}{i!}$
1 | labels = np.dot(poly_features, true_w) |
1 | labels += np.random.normal(scale=0.1, size=labels.shape) |
1 | # NumPy ndarray转换为tensor |
模型精确度
1 | def evaluate_loss(net, data_iter, loss): #@save |
训练主函数
1 | # 输入:训练数据;测试数据;训练集输出;测试集输出;迭代轮数 |
对比不同训练数据
1 | # 首先看模型容量(5个参数)与真实模型(5个参数)相同的模型训练过程与模型验证结果 |
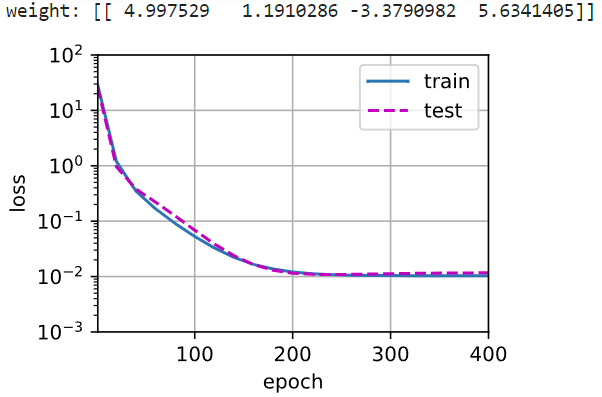
1 | # 再看模型容量(2个参数)小于真实模型(5个参数)相同的模型训练过程与模型训练结果——欠拟合 |
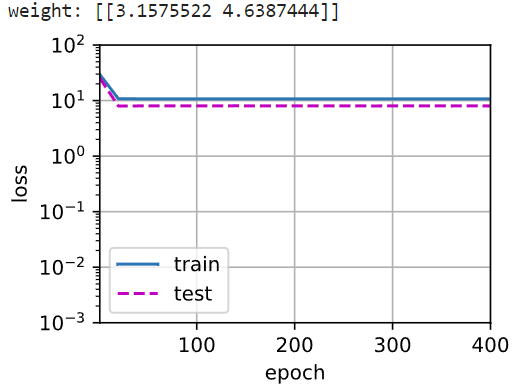
1 | # 最后看模型容量(20个参数)大于真实模型(5个参数)相同的模型训练过程与模型训练结果——存在过拟合风险 |
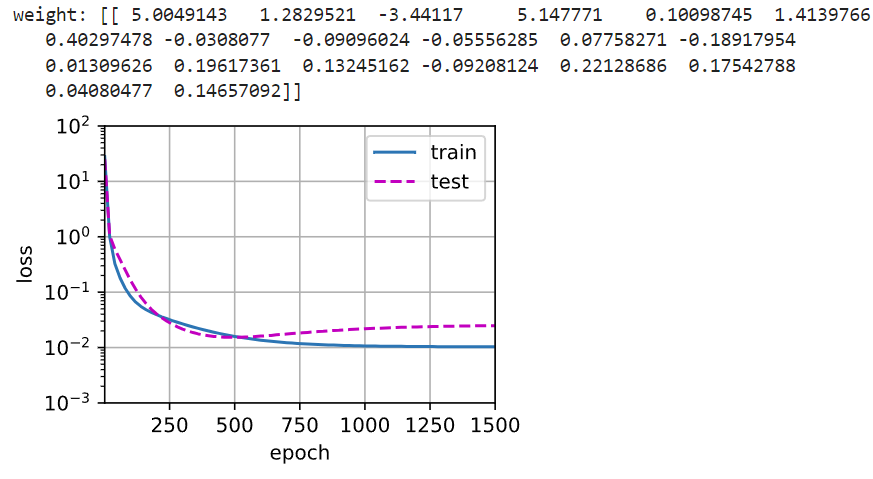
在高维度上学到了噪音信息,所以出现过拟合线性
4.2 处理过拟合的方法
在给出大量样本少量特征时,简单模型通常不会过拟合
简单模型(线性模型)具有较高的泛化性能,即模型的方差很低:在不同的数据集上有相似的表现。但由于 偏差-方差权衡 ,泛化性能好的,偏差会比较高(只能学习到数据集的部分特征)
神经网络学习的是特征之间的关联对结果的影响,而不局限于单个特征对结果的影响。神经网络的模型容量非常大,即偏差小(理论上能学习到数据集的所有特征),方差高(受数据集变化影响大)。所以即使对于有很多特征的数据集,神经网络也很容易过拟合。
一个好的模型需要对输入数据的扰动鲁棒,即模型的方差与偏差尽可能同时小
处理过拟合的思路从两个方面考虑
- 将参数规模变小
- 将参数取值范围变小
权重衰减和丢弃法从不同角度出发最后都是将部分参数取0,从参数数量和参数取值上提供了一种连续的过拟合处理方法
4.2.1 权重衰减
权重衰减是通过限制参数值的取值范围(控制与0的距离)来控制模型容量的方法
应用了权重衰减的神经网络,最终某些权重会变成零,权重为零相当于这个神经元会被抛弃。神经网络中某些权重归零,表示模型的复杂度下降了,多了一个零,少了一个参数
使用二范数作为硬性限制
使得目标函数变为带约束项的目标函数
- 原先训练目标:最小化训练标签上的预测损失
- 调整训练目标:最小化预测损失和惩罚项之和
通常不限制偏移 $b$ ,小的 $\theta$ 意味着更强的正则项
在实现上比较困难
二范数作为柔性限制
对每个 $\theta$ ,都可以找到 $\lambda$ 带约束项的目标函数等价于带正则项的目标函数
超参数 $\lambda$ 控制了正则项的重要程度
- $\lambda=0$ :无作用
- $\lambda\rightarrow \infty\Rightarrow \mathbf{w}^*\rightarrow 0$
若想使模型复杂度低,可以通过增大 $\lambda$ 来实现需求
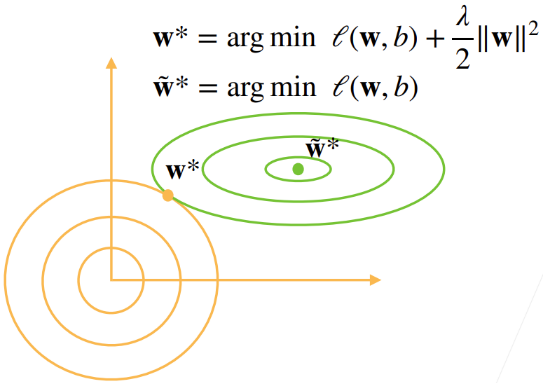
当 $\lambda\neq 0$ 时, 正则项对最小化目标函数的产生影响,使得最优的参数取值发生偏移 $\tilde{\mathbf{w}}^\neq \mathbf{w}^$
随着 $\lambda$ 的增大,正则项对参数取值的影响越大
正则项会使参数的2范数会靠近0点,权重整体会变小;同时,若权重继续衰减,则 $\ell$ 的增加项会抵消 $\Vert \mathbf{w}\Vert^2$ 的减小项。所以会在 $\tilde{\mathbf{w}}^*$ 形成平衡点
因此,正则项的引入会使模型整体的复杂度降低
参数更新法则
带正则项的损失函数梯度
在梯度下降算法中
通常,$\eta\lambda<1$ ,即在每次更新参数前,参数 $\mathbf{w}$ 都会先变小,所以称为权重衰减
一般情况下,我们会根据估计值与观测值之间的平均差异来调整参数结构、参数取值,为了控制模型容量尽量避免过拟合,我们会试图将 $\mathbf{w}$ 的大小缩小到0, 权重衰减提供了一种连续的机制来调整函数的复杂度
通常选择 $1e^{-3}=0.001$
实现
生成数据
1 | import torch |
参数初始化
1 | def init_params(): |
正则项
1 | def l2_penalty(w): |
训练
1 | def train(lambd): |
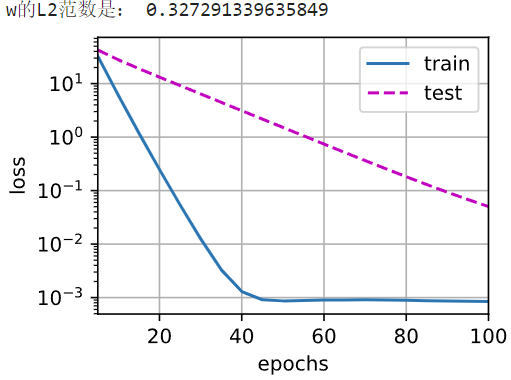
不加正则项,很明显的过拟合,训练误差与测试误差的差距非常大
1 | train(lambd=0) |
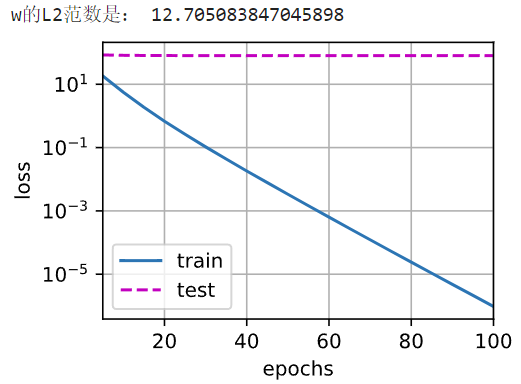
使用权重衰减
仍有过拟合,但两个误差的差距小了很多
增大正则项
增加训练epoch:本例中,测试误差仍在下降,所以可以增加训练轮次
1 | train(lambd=3) |
torch实现
在实例化优化器时直接通过weight_decay指定weight decay超参数
默认情况下,PyTorch同时衰减权重和偏移。 这里我们只为权重设置了weight_decay,所以偏置参数 $b$ 不会衰减。
1 | def train_concise(wd): |
4.2.2 dropout法
为增强模型的鲁棒性,缩小训练性能与测试性能的差距,模型越简单越好
简单性一方面是特征的维度小,参数的范数代表了一种简单性度量;另一方面是平滑性,指函数不应该对数据的微小扰动敏感
- 使用有噪音的数据等价于 Tikhonov 正则
Hinton将该想法引入神经网络的隐藏层:在层之间加噪音 ——dropout法
前提是无偏丢弃,固定其他层时,每一层的期望值相当于没有噪音时的值
对输入 $\mathbf{x}$ 通过dropout法加噪音得到 $\mathbf{x}’$ ,使得 $E[\mathbf{x}’]=\mathbf{x}$
以一定概率丢弃某些神经元,隐藏层每个神经元的活性值 $\mathbf{h}$ 以一定概率 $p$ 被随机变量$\mathbf{h}’$ 替换
- $E[h’]=p\times 0+(1-p)\frac{h}{1-p}=h$ ,即有 $1-p$ 的概率这个活性值会变大
将dropout应用于隐藏层

在训练过程中,每次都采样到这个隐藏层的部分神经元(子隐藏层),多轮训练,这些子隐藏层训练的平均会有不错的结果。
从实验上,dropout法和正则项都会将某些特征的参数变为0
预测中不适用dropout
正则项只在训练中使用:影响模型参数的更新
在验证与测试中,dropout直接返回输入
dropout技巧
技巧:将神经网络隐藏层稍微放大一些,然后用droupout正则化
比不用dropout直接对模型参数结构进行调整效果好一些
实现
1 | import torch |
```python
def dropout_layer(X, dropout):assert 0 <= dropout <= 1 # 在本情况中,所有元素都被丢弃 if dropout == 1: return torch.zeros_like(X) # 在本情况中,所有元素都被保留 if dropout == 0: return X #功能:每个神经元以dropout的概率被随机丢弃,若固定某几个神经元,相当于直接将隐藏层变小 # 0*该神经元值=0即被丢弃,CPU和GPU中,做乘法比选择元素来得快 # 生成(0,1)间的均匀分布,取随机数参数 # 若X[i]>dropout,则X[i]=1;否则X[i]=0 mask = (torch.rand(X.shape) > dropout).float() return mask * X / (1.0 - dropout)class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2, is_training = True): super(Net, self).__init__() self.num_inputs = num_inputs self.training = is_training self.lin1 = nn.Linear(num_inputs, num_hiddens1) self.lin2 = nn.Linear(num_hiddens1, num_hiddens2) self.lin3 = nn.Linear(num_hiddens2, num_outputs) self.relu = nn.ReLU() def forward(self, X): H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs)))) # 只有在训练模型时才使用dropout if self.training == True: # 在第一个全连接层之后添加一个dropout层 H1 = dropout_layer(H1, dropout1) H2 = self.relu(self.lin2(H1)) if self.training == True: # 在第二个全连接层之后添加一个dropout层 H2 = dropout_layer(H2, dropout2) out = self.lin3(H2) return outnet = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- ```python
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 10))
def init_weights(m):
# 仅线性层有参数需要初始化
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
1 | #定义损失计算器 |
4.3 数值(梯度值)稳定性
4.3.1 梯度爆炸、消失原因
对于有 $L$ 层的神经网络,第 $l$ 层的活性值为 $\mathbf{h}_l$
其中,$\mathbf{h}_{l-1}\in \mathbb{R}^{1\times M_{l-1}}$ ,$\mathbf{W}\in\R^{M_{l}\times M_{l-1}}$ ,$\mathbf{b}_l\in \mathbb{R}^{1\times M_l}$
输出层 $\hat{\mathbf{y}}=f_L\circ f_{L-1}\cdots \circ f_1(\mathbf{X})$ ,损失函数为 $\ell(\mathbf{y},\hat{\mathbf{y}})$ ,损失函数关于第 $l$ 层参数的梯度为
- $\frac{\partial\ell}{\partial\mathbf{W}_l}\in \mathbb{R}^{M_{l}\times M_{l-1}}$ ,$\frac{\partial \ell}{\partial \mathbf{h}_{L}}\in \mathbb{R}^{1\times M_L}$ , $\frac{\partial\mathbf{h}_{l}}{\partial\mathbf{h}_{l-1}}\in\R^{M_{l}\times M_{l-1}}$ ,$\frac{\partial\mathbf{h}_{l}}{\partial\mathbf{W}_l}\in \mathbb{R}^{M_l\times M_{l}\times M_{l-1}}$
由于 $\frac{\partial \mathbf{h_l}}{\partial \mathbf{h}_{l-1}}=\frac{\partial\mathbf{h}_{l}}{\partial \mathbf{o}_l}\frac{\partial \mathbf{o}_l}{\partial \mathbf{h}_{l-1}}$
则 $\frac{\partial \mathbf{h_l}}{\partial \mathbf{h}_{l-1}}=diag\left[\sigma’\left(\mathbf{h}_{l-1}\mathbf{W}_l+\mathbf{b}_l\right)\right]\mathbf{W}_l$
故
梯度爆炸
使用ReLU作为激活函数
此时,$\prod\limits_{i=l}^{L-1}\frac{\partial\mathbf{h}_{i+1}}{\partial\mathbf{h}_{i}}=\prod\limits_{i=l}^{L-1} diag\left[\sigma’\left(\mathbf{h}_{i-1}\mathbf{W}_i+\mathbf{b}_i\right)\right]\mathbf{W}_i$ 的一些元素会来自于 $\prod\limits_{i=l}^{L-1}\mathbf{W}_i$ ,若网络层数很深 $L-l-1$ 很大,则这些值可能非常大
值超出值域:一般采用float16计算,因为计算快于float32,但值域小 $6e^{-5}\sim 6e^4$ ,很容易超出值域
对学习率敏感
- 若学习率太大,则参数值大,进而造成更大的梯度
- 若学习率太小,训练无进展
- 因此在训练过程中需要频繁调整学习率
梯度消失
使用sigmod作为激活函数
此时,$\prod\limits_{i=l}^{L-1}\frac{\partial\mathbf{h}_{i+1}}{\partial\mathbf{h}_{i}}=\prod\limits_{i=l}^{L-1} diag\left[\sigma’\left(\mathbf{h}_{i-1}\mathbf{W}_i+\mathbf{b}_i\right)\right]\mathbf{W}_i$ 的元素值是 $L-l-1$ 个小数值的乘积
在饱和区导数接近于0,这样误差经过每一层传递会不断衰减,当网络层数很深时,梯度就会不断衰减, 甚至消失,这就是梯度消失问题
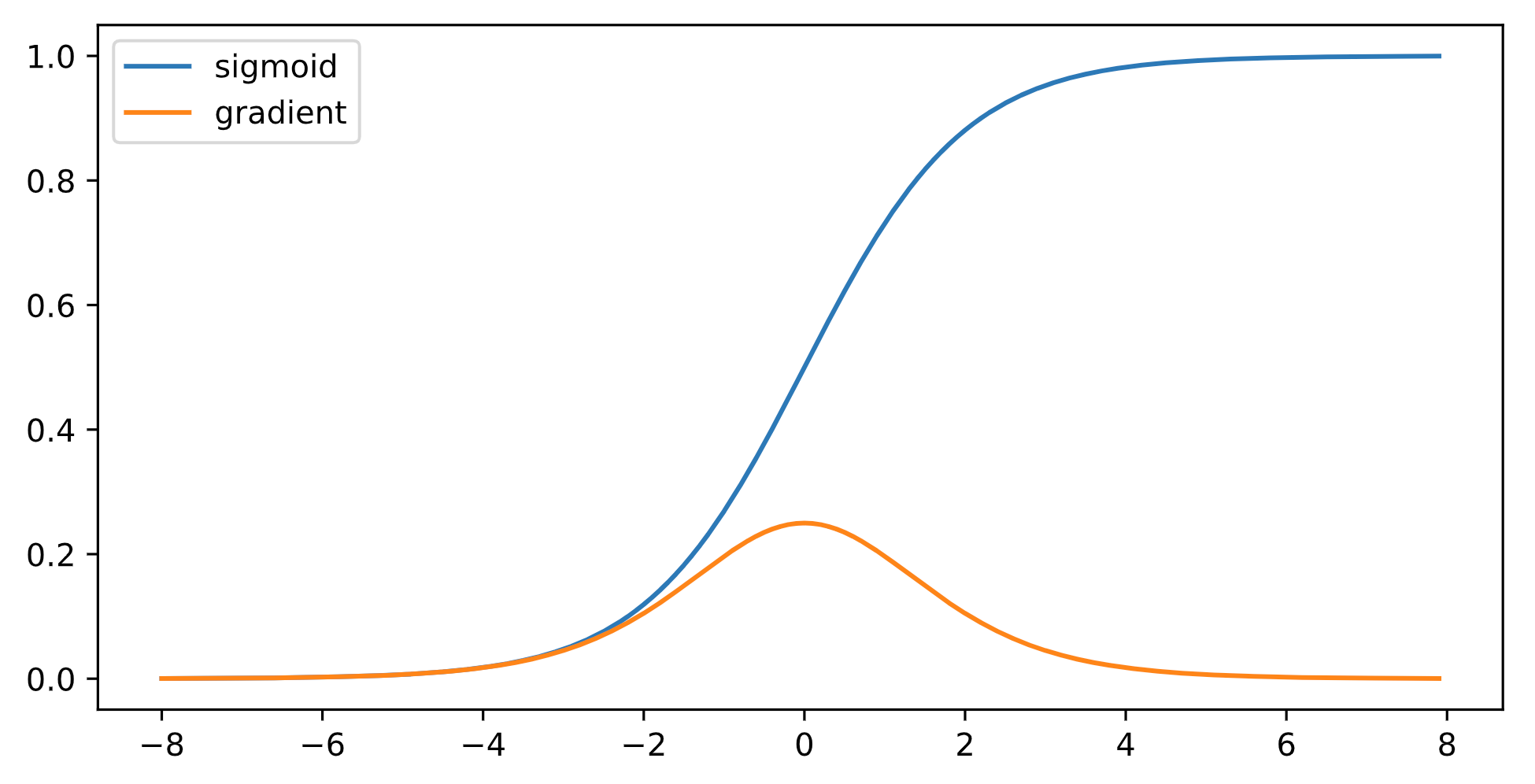
后果:
- 梯度值变为0:对float16严重
- 训练无进展:不管学习率多大
- 对深处的网络层极为严重:仅浅层网络训练好,无法让网络更深
可以采用导数比较大的激活函数,ReLU函数
4.3.2 增加数值稳定性方法
目标:让梯度值在合理范围内
将每层的输出和梯度都看做随机变量,让各层输出和梯度的均值和方差都保持一致
正向:$E[\mathbf{h}_l^{(i)}]=0,var[\mathbf{h}_l^{(i)}]=a$
反向:$E\left[\frac{\partial \ell}{\partial \mathbf{h}_l^{(i)}}\right]=0,var\left[\frac{\partial \ell}{\partial \mathbf{h}_l^{(i)}}\right]=b$
若每层方差都是一个常数,则这样的神经网络的梯度值会稳定
方法:
- 乘法变加法:ResNet、LSTM
- 归一化:梯度归一化、梯度裁剪
- 合理的初始权重和激活函数
4.3.3 权重初始化
参数初始化到合理的取值区间内
训练开始时更容易数值不稳定
- 远离最优解的地方损失函数可能很复杂
- 最优解附近表面会比较平缓、稳定
使用 $\mathcal{N}(0,0.01)$ 初始参数,对于比较浅的神经网络没问题,但深度神经网络,可能会出现梯度爆炸/消失问题
假设第 $l$ 层的网络参数 $w_l^{(i,j)}$ 是独立同分布的,且 $E[w_l^{(i,j)}]=0,var[w_l^{(i,j)}]=\gamma_l$
第 $l-1$ 层的活性值 $\mathbf{h}_{l-1}$ (第 $l$ 层的输入)独立于第 $l$ 层的参数 $\mathbf{W}_l$ ,即 $h_{l-1}^{(i,j)}$ 独立于 $w_l^{(i,j)}$
正向均值
正向方差
- 若希望各层输入和输出的方差一致,则 $M_{l-1}\gamma_l=1$ 成立
反向均值与反向方差有相同结论
Xavier初始化
实质上很难以同时满足 $M_{l}\gamma_l=1$ 和 $M_{l-1}\gamma_l=1$ ,除非每一层的输入神经元数与输出神经元个数相等 $M_l=M_{l-1}$
做折衷,Xavier初始化令 $\frac{\gamma_l\left(M_l+M_{l-1}\right)}{2}=1\Rightarrow \gamma_t=\frac{2}{M_{l}+M_{l-1}}$
- 若用正态分布初始化参数,$w^{(i,j)}_l\sim \mathcal{N}(0,\sqrt{\frac{2}{M_l+M_{l-1}}})$
- 若使用均匀分布初始化参数,$w^{(i,j)}_l\sim \mathcal{U}(-\sqrt{\frac{6}{M_l+M_{l-1}}},\sqrt{\frac{6}{M_l+M_{l-1}}})$
所以方差需要根据权重形状变换,尤其时 $M_l$
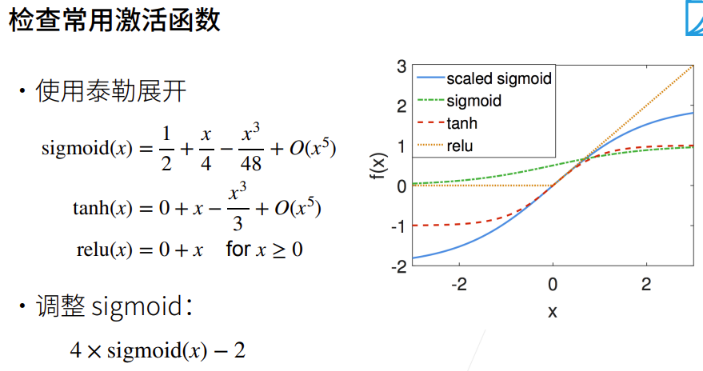
激活函数的选择
假设激活函数是线性的 $\sigma(x)=\alpha x+\beta$ ,$\mathbf{h}_l=\sigma(\mathbf{h}_{l-1}\mathbf{W}_l+\mathbf{b}_l)=\alpha\mathbf{o}_l+\beta$
正向均值,方差
反向均值,方差
若想通过控制其均值与方差的方法,同时让输入输出的梯度值保持在一个区间内,则必须让 $\alpha=1$ ,同时其均值为0,意味着激活函数在零点附近必须是 $f(x)=x$ 且活性值必须尽可能接近0
4.4 整体训练步骤
1. 下载数据集
DATA_HUB 存储数据集信息元组
- 数据集的url、文件完整新验证的 sha-1 密钥
- 键:文件名
- 值:文件路径/文件名,远端文件的sha-1值
1 | import hashlib |
1 | #功能:下载DATA_HUB中指定的文件,将数据集缓存在本地,默认为上层文件夹的data文件夹下 |
1 | # 功能:下载名为name的zip或tar、gz文件并解压 |
下载数据并查看
1 | def download_all(): #@save |
1 | import numpy as np |
1 | train_data = pd.read_csv(download('kaggle_house_train')) |
删除id :不携带任何用于预测的信息
1 | all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:])) |
2. 数据预处理
公开数据集一般分为训练集和验证集,数据集需要经过预处理才能进入训练
数值类型
- 数据类型复杂:有些是数值类型,浮点数;类别一般是离散类别表示
- 数据缺失:缺失值被简单地标记为NA
先将缺失值替换为相应特征的均值
归一化:将所有值类型特征的值缩放到0均值和单位方差来标准化数据
$E[\frac{x-\mu}{\sigma}] = \frac{\mu - \mu}{\sigma} = 0$
$E[(x-\mu)^2] = (\sigma^2 + \mu^2) - 2\mu^2+\mu^2 = \sigma^2$
1 | # 若无法获得测试数据,则可根据训练数据计算均值和标准差 |
离散值
用 one-hot 编码
- 特征
MSZoning包含两个值RL和Rm,使用 one-hot 编码,如果“MSZoning”的原始值为“RL”, 则:“MSZoning_RL”为1,“MSZoning_RM”为0
1 | # “Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建指示符特征 |
转换为Numpy格式,并转为张量
1 | # 训练数据个数 |
3. 训练
定义模型
1 | in_features = train_features.shape[1] |
采用平方损失函数作为基准模型
1 | loss = nn.MSELoss() |
实际上,我们更多关心的是相对误差,而不是绝对误差,即 $\frac{\mathbf{y}-\hat{\mathbf{y}}}{\mathbf{y}}$ 。使用对数误差来衡量差异
令 $1-\frac{\hat{y}}{y}\le \delta\Rightarrow \frac{\hat{y}}{y}\ge 1-\delta\triangleq\delta\iff \vert \log y-\log\hat{y}\vert\le \delta$ ,因此有均方根误差
1 | def log_rmse(net, features, labels): |
训练
1 | def train(net, train_features, train_labels, test_features, test_labels, |
4. k-折交叉验证
K折交叉验证
1 | # 将数据划分为k折,并将第i折作为训练数据,返回划分后的训练集与验证集 |
5. 模型选择
1 | k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64 |
若一组超参数的训练误差很低,但K折交叉验证的平均误差高,表明模型发生过拟合。整个巡礼那过程都要监控训练误差与验证误差
- 较小的过拟合说明模型效果好
- 较大的过拟合表明需要通过正则化技术来获益
6. 预测
1 | # 传入选择好的超参数,基于测试数据更新模型参数后,对验证集中的数据做一次预测 |
4.5 automl
目前80%的时间都在处理数据,20%的时间调模型
Automl现在能处理一些基础情况,目前能节省10%时间,上限节省20%时间