[TOC]
updated1: 2024-03-19 16:22:59
2. 线性模型
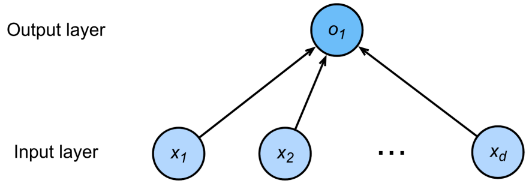
线性模型可以看做单层神经网络
torch中创建的向量为行向量,所以后续基于行向量进行原理推导
对于 线性模型,$d$ 维行输入向量 $\mathbf{x}=[x^{(1)},x^{(2)},\cdots,x^{(d)}]\in \mathbb{R}^{1\times d}$ ,输出 $\hat{y}$ 是输入的加权和
$\mathbf{w}=[w_1,w_2,\cdots,w_d]\in \mathbb{R}^{1\times d}$
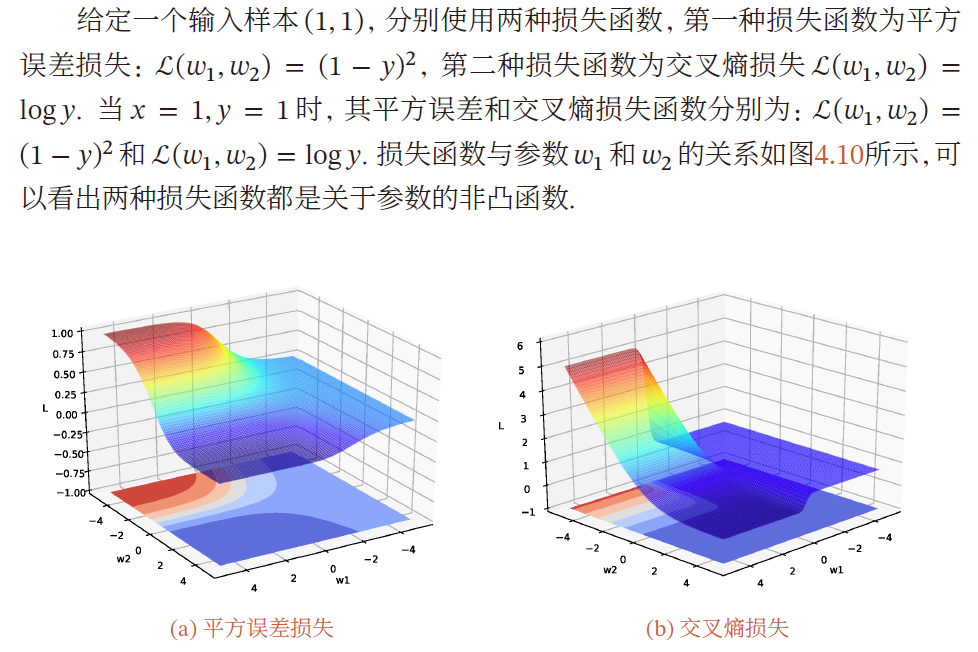
衡量预测质量:比较真实值和预测值,假设 $y$ 是真实值,$\hat{y}$ 是预测值,可以使用平方损失衡量预测质量
对于参数的取值,需要收集一些数据点来决定,称为训练数据,通常越多越好。假设有 $n$ 个样本,数据集为
定义损失函数:将模型对数据的预测结果与真实结果误差作为损失函数,希望这个损失越小越好
所以目标函数为:最小化损失函数来学习参数
使用训练数据进行 参数学习 :通过梯度下降法更新参数使损失函数的最小
为简化过程,将偏差加入权重,$\mathbf{w}=[w_1,w_2,\cdots,w_d,b]$ ,对数据进行1扩充,$\mathbf{x}_i=[x_i^{(1)},x^{(2)}_i,\cdots,x^{(d)}_i,1]$
则有,
损失函数为
对参数求梯度
由于该函数是凸函数,最优解为
2.1 线性回归实现
2.1.1 生成数据
1 | %matplotlib inline #在jupyter notebook中显示图像 |
2.1.2 生成批量
1 | batch_size = 10 |
2.1.3 初始化模型
模型定义
1 | def linreg(X, w, b): #@save |
随机初始化参数
1 | #随机初始化参数 |
更新这些参数,直到这些参数足够拟合训练数据。每次更新都需要计算损失函数关于模型参数的梯度,requires_grad=True 对这个参数引入自动微分计算梯度
2.1.4 定义损失函数
1 | def squared_loss(y_hat, y): #@save |
2.1.5 定义优化算法
若损失函数计算的是整个样本集上的损失
其梯度为
若采用小批量随机梯度下降法,用 $\vert \mathcal{B}\vert$ 个样本的小批量样本集 $\mathcal{B}$
沿着负梯度方向更新参数,每步更新的步长由学习率 lr 决定
1 | def sgd(params, lr, batch_size): #@save |
若一个节点(叶子变量:自己创建的tensor)requires_grad被设置为True,那么所有依赖它的节点requires_grad都为True
当requires_grad设置为False时,反向传播时就不会自动求导了,因此大大节约了显存或内存
with torch.no_grad起到了截断自动微分的作用,对不需要计算微分的部分进行截断
2.1.6 训练过程
1 | '''1.生成数据''' |
2.2 基于pytorch实现线性回归
2.2.1 生成数据
1 | import numpy as np |
2.2.2 数据迭代器(理解)
1 | def load_array(data_arrays, batch_size, is_train=True): #@save |
在 data.DataLoader() 创建的迭代器对象中,封装了数据元组
将整个数据集按批量大小划分为多个批量,并返回划分后的 可迭代对象
可迭代对象可视为一个列表,列表的每一项封装了一个批量(元组),对一个项操作,相当于对一个批量的操作
- 遍历可迭代对象,相当于逐批量获取数据
为查看迭代器内容,需要使用 iter() 构造器将 Pytorch迭代器转换为 Python迭代器,然后使用 next(itr) 获取第一项
1 | next(iter(data_iter)) |
2.2.3 初始化模型
模型定义
对于标准深度学习模型,我们可以使用框架预定义好的层。每一层都可以理解为带有输入和输出的模型
使用框架之后,我们只需关注使用哪些层来构造模型,而不必关注层的实现细节。
- 这种情况类似于为自己的博客从零开始编写网页。也能使用博客框架,博客框架环境配置好后,只需要关注博客内容即可
在Pytorch中,定义一个模型变量 net ,net 是一个 Sequential 类
Sequential将多个层串联在一起。当给定输入数据时,模型变量将数据传入到第一层,第一层的输出作为第二层的输入,以此类推
1 | # nn是神经网络的缩写 |
随机初始化模型参数
1 | #线性模型可以视为单层神经网络,在框架中只有第一层 |
Sequential 实例的 parameters() 函数可以获取当前层的参数,返回的是参数的迭代对象
1 | Parameter containing: |
2.2.4 损失函数
在nn模块中,定义了各种损失函数
均方损失,MSELoss 类
1 | # 损失实例已经包含批量大小信息 |
2.2.5 定义优化函数
PyTorch在优化模块 optim 中实现了随机梯度下降算法(SGD)的许多变种
使用SGD实例时,要指定优化的参数
- 小批量SGD只需要指定学习率
1 | trainer = torch.optim.SGD(net.parameters(), lr=0.03) |
2.2.6 训练过程
1 | import numpy as np |
2.3 softmax回归
回归任务:估计连续值
分类任务:预测一个离散的类别
- 手写数字识别-10类
- ImageNet:1000000张图片的,1000类自然物体分类
- Kaggle上的分类问题:
- 人类蛋白质显微镜图片28类
- 恶意软件分类9类
- WIkipedia评论分为7类
回归任务到分类任务
| 回归任务 | 分类任务 |
|---|---|
| 单连续数值输出 | 多离散输出 |
| 自然区间 $\mathbb{R}$ | 输出 $p(i)$ 是预测为第 $i$ 类的置信度 |
| 与真实值的差作为损失 | |
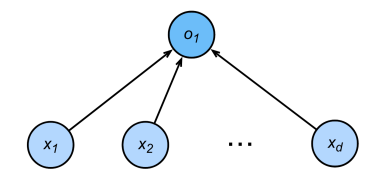 | 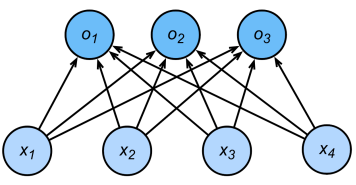 |
对类别编码,若有 $K$ 个类别,使用one-hot向量对真实样本 $(\mathbf{x}_i,y_i)$ 进行编码 $\mathbf{y}_i=[y_i^{(1)},y_i^{(2)},\cdots,y_i^{(K)}]$,令 $\kappa$ 为 $\mathbf{x}_i$ 的真实类别,则 $y_i^{(k)}=\begin{cases}1&,k=\kappa\\0&,k\neq \kappa\end{cases},k=1,\cdots,K$ ,样本 $\mathbf{x}_i$ 的真实类别 $y_i^{(k)}$ 服从一个分布 $p$
$\hat{y}_i^{(k)}=q(\hat{y}_i=k\vert \mathbf{x}_i)=softmax(o_i^{(k)})=\frac{e^{o_i^{(k)}}}{\sum\limits_{k=1}^Ke^{o_i^{(k)}}}=\frac{e^{\mathbf{x}_i\mathbf{w}_k^T}}{\sum\limits_{k=1}^Ke^{\mathbf{x}_i\mathbf{w}_k^T}}$ 表示将样本 $\mathbf{x}_i$ 预测为 $k$ 类的置信度,对样本 $\mathbf{x}_i$ 的类别预测置信度服从分布 $q$
- $o_i^{(k)}=\mathbf{w}^T_k\mathbf{x}_i$ 为经过线性模型 $\mathbf{w}_k^T\mathbf{x}$ 后 $\mathbf{x}_i$ 为第 $k$ 个类别的置信度净输出。
- $\mathbf{o}_i=\left[o_i^{(1)},o_i^{(2)},\cdots,o_i^{(K)}\right]$ 为样本 $\mathbf{x}_i$ 经过线性模型后的置信度净输出向量
- $\hat{\mathbf{y}}_i=softmax(\mathbf{o}_i)=\left[softmax\left(o_i^{(1)}\right),softmax\left(o_i^{(2)}\right),\cdots,softmax\left(o_i^{(k)}\right)\right]=\left[\hat{y}_i^{(1)},\hat{y}_i^{(2)},\cdots,\hat{y}_i^{(K)}\right]$
所以目标函数为
- 目标是预测为正确类别的置信度远远大于其他类别
通过交叉熵可以比较真实分布与预测分布的差异
- $H(p,q)=-\sum_k p_k\log q_k\ge 0$ 为交叉熵,当 $p_k=q_k$ 时,即两个分布相同时,交叉熵有最小值0
将其作为损失函数
对参数 $\mathbf{w}_{\kappa}$ 求梯度
分类数据集
MNIST数据集 (LeCun et al., 1998) 是图像分类中广泛使用的数据集之一(手写数字识别数据集),但作为基准数据集过于简单
使用类似但更复杂的Fashion-MNIST数据集
1 | import torch |
下载数据集
通过torchvision内置函数将数据集下载并读取到内存
1 | # 通过ToTensor实例将图像数据从PIL类型转换成pytorch类型,32位浮点数格式, |
- 整个下载包括下载、移动、解压三步
查看数据集
1 | # 数据集中的图片数量 |
可视化数据集
批量查看图片及其标签
1 | # 标签值转为标签文本 |
1 | #imgs为图片集,num_rows,num_cols为图片列表行列数,titles传入imgs相应的标签 |
读取两个样本,显示二者图像列表
1 | X, y = next(iter(data.DataLoader(mnist_train, batch_size=2))) |

实现批量读取
在每次迭代中,数据加载器每次都会[读取一小批量数据,大小为batch_size]
通过内置数据迭代器,可以随机打乱所有样本
1 | batch_size = 256 |
可记录加载一个批量的时间
1 | timer = d2l.Timer() |
封装数据读取
从视觉库的Fashion-MNIST数据集获取训练数据集和测试数据集。
返回:训练集和验证集的数据迭代器
输入:批量大小batch_size;resize图像大小调整
1 | def load_data_fashion_mnist(batch_size, resize=None): #@save |
通过resize参数调整图片大小
1 | train_iter, test_iter = load_data_fashion_mnist(32, resize=64) |
1 | torch.Size([32, 1, 64, 64]) torch.float32 torch.Size([32]) torch.int64 |
2.3.1 Softmax实现
获取数据集批量
1 | import torch |
初始化参数
softmax输入需要是向量,所以需要把所有图像展平,视为一个向量,$1\times 28\times 28=784$ 的列向量 $img_{[1\times28\times 28]}\rightarrow\mathbf{x}_{[784\times 1]}$
- 展平操作会损失很多空间信息,所以卷积神经网络会弥补这一缺陷
一张图像可能得类别有10类,所以输出10维的列向量 $\mathbf{y}_{[10\times 1]}$
1 | num_inputs = 784 |
模型定义
输入,原始数据矩阵:每个样本展平为 $\mathbf{x}_i\in\R^{1\times d}$ 的行向量,批量样本矩阵为 $\mathbf{X}=\begin{bmatrix}\mathbf{x}_1\\\mathbf{x}_2\\\vdots\\\mathbf{x}_n\end{bmatrix}\in \mathbb{R}^{n\times d}$
本例中 $\mathbf{x}_i\in\R^{1\times 784}$ ,批量数据表示为 $\mathbf{X}=\begin{bmatrix}\mathbf{x}_1\\\vdots\\\mathbf{x}_{256}\end{bmatrix}\in\R^{256\times 784}$
参数 $\mathbf{w}_k\in \mathbb{R}^{1\times d},k\in [1,K]$ ,参数矩阵 $\mathbf{W}=\begin{bmatrix}\mathbf{w}_1\\\mathbf{w}_2\\\vdots\\\mathbf{w}_{K}\end{bmatrix}\in \mathbb{R}^{K\times d}$ ,偏置 $\mathbf{b}\in \mathbb{R}^{1\times K}$ 行向量
- 本例中,$\mathbf{w}_k\in \mathbb{R}^{1\times 784},k\in [1,10]$ ,参数矩阵 $\mathbf{W}=\begin{bmatrix}\mathbf{w}_1\\\mathbf{w}_2\\\vdots\\\mathbf{w}_{10}\end{bmatrix}\in \mathbb{R}^{10\times 784}$ ,偏置 $\mathbf{b}\in \mathbb{R}^{1\times 10}$
净输出,净输出矩阵:每个样本的净输出向量为 $\mathbf{o}_i\in \mathbb{R}^{1\times K}$ 的行向量,批量样本净输出矩阵表示为 $\mathbf{O}=\begin{bmatrix}\mathbf{o}_1\\\mathbf{o}_2\\\vdots\\\mathbf{o}_{n}\end{bmatrix}\in \mathbb{R}^{n\times K}$
- 本例中,净输出 $\mathbf{o}_i\in \mathbb{R}^{1\times 10}$ ,批量净输出矩阵表示为 $\mathbf{O}=\begin{bmatrix}\mathbf{o}_1\\\mathbf{o}_2\\\vdots\\\mathbf{o}_{256}\end{bmatrix}\in \mathbb{R}^{256\times 10}$
1 | def net(X): |
所以一次softmax有三个操作
- 对每个项求幂
exp() - 对每一行求和(在一个批量中,一行为一个样本)
- 将每一行除以其规范化常数,确保结果的和为1
输入:净输出矩阵
输出:softmax后的置信度矩阵 / 归一化后的置信度矩阵 $\hat{\mathbf{Y}}=\begin{bmatrix}\hat{\mathbf{y}}_1\\\hat{\mathbf{y}}_2\\\vdots\\\hat{\mathbf{y}}_{n}\end{bmatrix}=\begin{bmatrix}\hat{\mathbf{y}}_1\\\hat{\mathbf{y}}_2\\\vdots\\\hat{\mathbf{y}}_{256}\end{bmatrix}$
1 | def softmax(O): |
交叉熵损失函数
对于每个样本,其交叉熵损失为
所以只需要关注真实分类对应的softmax值即可,pytorch有简便方法,根据索引列表依次从每个列表取出相应列表项,即从 $\hat{\mathbf{Y}}=\begin{bmatrix}\hat{\mathbf{y}}_1\\\hat{\mathbf{y}}_2\\\vdots\\\hat{\mathbf{y}}_{256}\end{bmatrix}$ 中,取出 $\begin{bmatrix}\hat{y}_1^{(\kappa_1)},\hat{y}_2^{(\kappa_2)},\cdots,\hat{y}_{256}^{(\kappa_{256})}\end{bmatrix}$
1 | y = torch.tensor([0, 2]) |
实现交叉熵损失函数
1 | def cross_entropy(y_hat, y): |
精确度计算函数
1 | def accuracy(y_hat, y): #@save |
逐批量计算数据集的精确度
1 | class Accumulator: #@save |
1 | evaluate_accuracy(net, test_iter) |
训练
参数迭代器
updater 是模型参数的优化函数,它接受批量大小作为参数。 它可以是d2l.sgd 函数,也可以是框架的内置优化函数
1 | lr = 0.1 |
模型的一次迭代
1 | def train_epoch_ch3(net, train_iter, loss, updater): #@save |
多轮迭代
1 | def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save |
1 | num_epochs = 10 |
预测
1 | def predict_ch3(net, test_iter, n=6): #@save |
整合
1 | import torch |
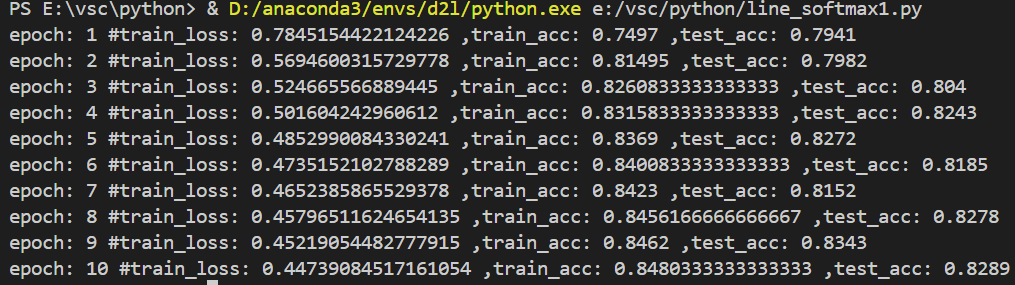
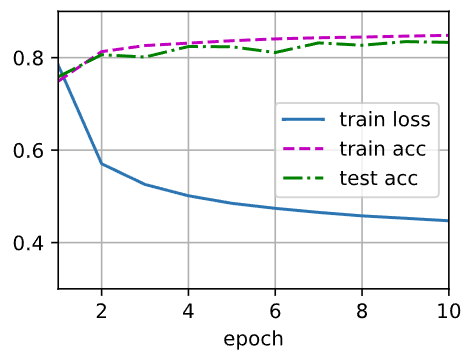
可视化预测结果
1 | # 输入:模型;测试集;可视化测试结果 |
2.3.2 基于Pytorch实现Softmax
1 | import torch |
2.3.3 关于损失函数的处理
在 softmax 前,净输出 $o_i^{(k)}$ 是一个未归一化的值,可能非常大,则 $e^{o_i^{(k)}}$ 可能会大于数据类型允许的最大数字——上溢 ,上溢会使得分母或分子无穷大,从而得到 0 、inf 、nan 的 $\hat{y}_i^{(k)}$
为避免上溢,在softmax 之前先让所有的 $o_i^{(k)}$ 减去 $\max(o^{(k)})$ ,即
在减法规范化后,可能有些 $o_i^{(k)}-\max(o_i^{(k)})$ 是比较大的负值,由于精度受限,$e^{o_i^{(k)}-\max(o_i^{(k)})}$ 会接近0——下溢 。这些值四舍五入后,使得 $\hat{\mathbf{y}}_i$ 为零,$\log(\hat{\mathbf{y}}_i)$ 会 -inf ,反向传播后会出现 nan
尽管 softmax 计算的是指数函数,但之后交叉熵损失函数是指数函数,二者结合在一起可以避免反向传播过程中的数值稳定性问题。
因此,可在交叉熵损失函数中直接使用未规范化的净输出作为损失函数
3. 前馈神经网络
3.1 多层感知机
3.1.1 线性感知机PLA
感知机解决的是二分类问题
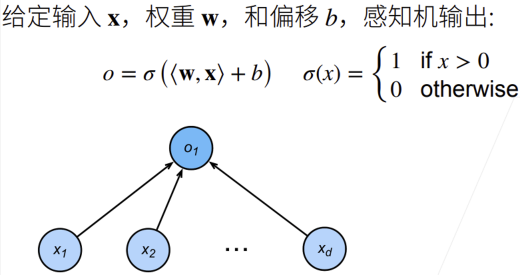

损失函数的梯度 $\frac{\partial \ell(y,\mathbf{x},\mathbf{w})}{\partial \mathbf{w}}=-y\mathbf{x}$ ,$\frac{\partial \ell(y,\mathbf{x},\mathbf{w})}{\partial b}=-y$
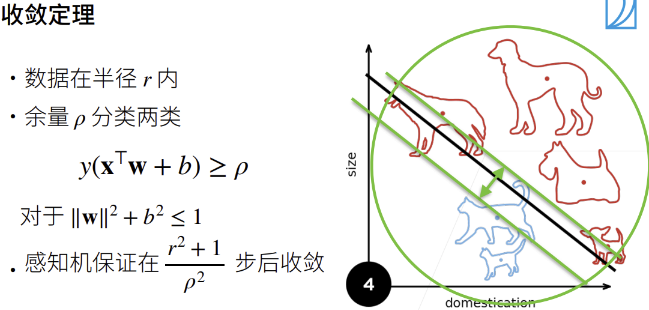
- 收敛步数影响因素:数据规模(越大收敛越慢)、分界余量(越大收敛越快)
缺陷:不能拟合XOR函数,因为单层感知机只能产生线性分割面
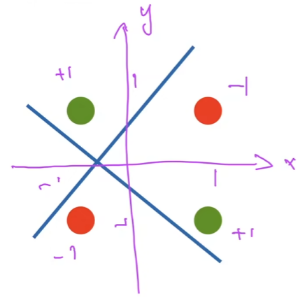
- $1\oplus1=1$,$-1\oplus-1=1$ ;$-1\oplus1=-1,1\oplus -1=-1$
3.1.2 多层感知机MLP
multi-layer perceptrons
XOR学习到单隐藏层感知机
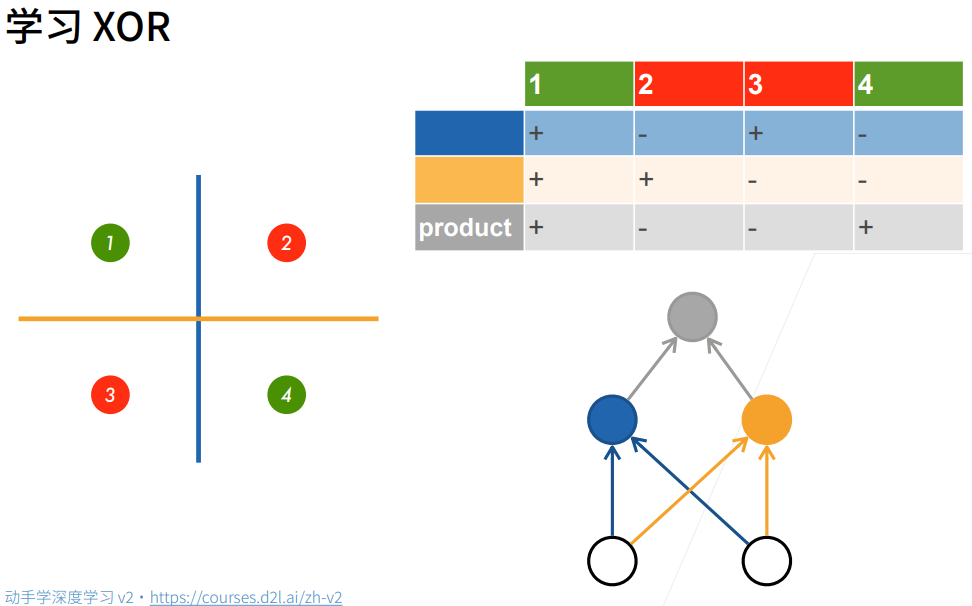
先训练蓝色感知机,将1,3分为+类,将2,4分为-类
再训练黄色感知机,将1,2分为+类,将3,4分为-类
最后训练灰色感知机,将两个+类或两个-类分为+类,将一个+类和一个-类分为-类
单隐藏层MLP
输入 $\mathbf{x}\in \mathbb{R}^{1\times d}$
隐藏层 $\mathbf{W}_1\in \mathbb{R}^{M_1\times d}$ ,$\mathbf{b}_{1}\in \mathbb{R}^{1\times M_1}$
- 隐藏层输出=输出层输入:$\mathbf{h}_1=\sigma(\mathbf{x}\mathbf{W}_1^T+\mathbf{b}_1)\in \mathbb{R}^{1\times M_1}$
- $\sigma(\cdot)$ 为按元素非线性激活函数
输出层 $\mathbf{w}_2\in \mathbb{R}^{1\times M_1}$ ,$b_2\in \mathbb{R}$
- $\hat{o}=\mathbf{h}_1\mathbf{w}_2^T+b_2\in\R$
激活函数非线性
非线性激活函数是为了避免层数塌陷
若激活函数为线性函数,经过隐藏层后输出等价于
即多层嵌套后仍然是一个线性感知器,这样的学习效果不好
激活函数类型
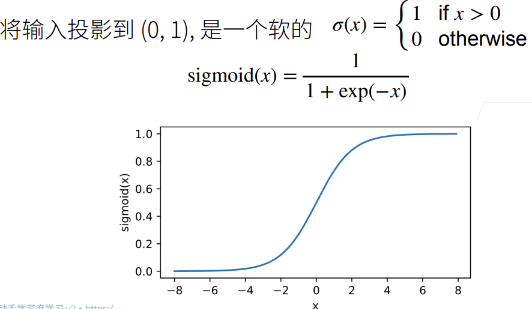
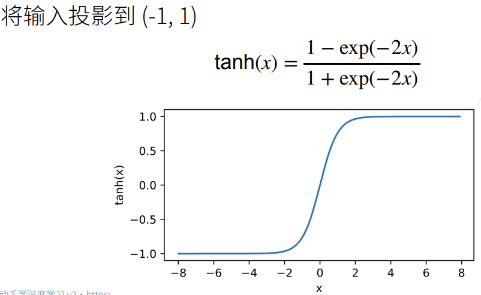
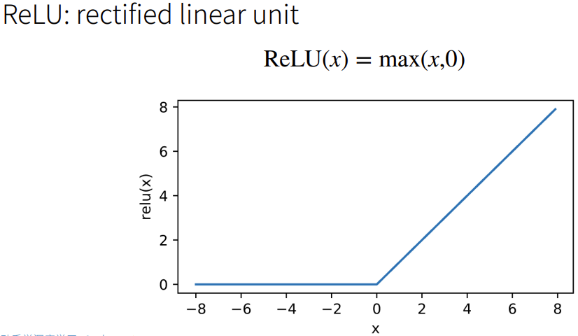
ReLU(x):节省资源,不需要计算指数函数
softmax与单隐藏层多分类MLP
输入 $\mathbf{x}\in \mathbb{R}^{1\times d}$
隐藏层 $\mathbf{W}_1\in \mathbb{R}^{M_1\times d}$ ,$\mathbf{b}_{1}\in \mathbb{R}^{1\times M_1}$
- 隐藏层输出=输出层输入:$\mathbf{h}_1=\sigma(\mathbf{x}\mathbf{W}_1^T+\mathbf{b}_1)\in \mathbb{R}^{1\times M_1}$
- $\sigma(\cdot)$ 为按元素非线性激活函数
输出层 $\mathbf{W}_2\in \mathbb{R}^{K\times M_1}$ ,$\mathbf{b}_2\in \mathbb{R}^{1\times K}$
- $\hat{\mathbf{o}}=\mathbf{h}_1\mathbf{W}_2^T+\mathbf{b}_2\in\R^{1\times K}$
- $\hat{\mathbf{y}}=softmax(\hat{\mathbf{o}})$
多隐藏层
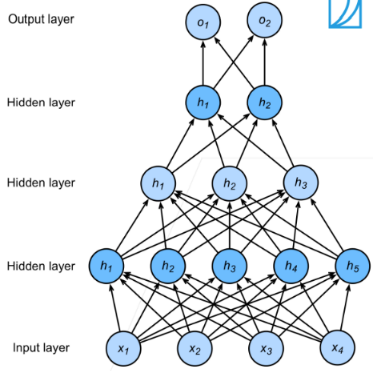
输入 $\mathbf{x}\in \mathbb{R}^{1\times d}$
第一隐藏层 $\mathbf{W}_1\in \mathbb{R}^{M_1\times d}$ ,$\mathbf{b}_{1}\in \mathbb{R}^{1\times M_1}$
- 第一隐藏层输出=第二隐藏层输入:$\mathbf{h}_1=\sigma(\mathbf{x}\mathbf{W}_1^T+\mathbf{b}_1)\in \mathbb{R}^{1\times M_1}$
- $\sigma(\cdot)$ 为按元素非线性激活函数
第二隐藏层 $\mathbf{W}_2\in \mathbb{R}^{M_2\times M_1}$ ,$b_2\in \mathbb{R}^{1\times M_2}$
- 第二隐藏层输出=第三隐藏层输入:$\mathbf{h}_2=\sigma(\mathbf{h}_1\mathbf{W}_2^T+\mathbf{b}_2)\in \mathbb{R}^{1\times M_2}$
第三隐藏层 $\mathbf{W}_3\in \mathbb{R}^{M_3\times M_2}$ ,$b_3\in \mathbb{R}^{1\times M_3}$
- 第三隐藏层输出=输出层输入:$\mathbf{h}_3=\sigma(\mathbf{h}_2\mathbf{W}_3^T+\mathbf{b}_3)\in \mathbb{R}^{1\times M_3}$
输出层 $\mathbf{w}_4\in \mathbb{R}^{K\times M_3}$ ,$\mathbf{b}_4\in \mathbb{R}^{1\times K}$
- $\hat{\mathbf{o}}=\mathbf{h}_3\mathbf{W}_4^T+\mathbf{b}_4\in\R^{1\times K}$
- $\hat{\mathbf{y}}=softmax(\hat{\mathbf{o}})$
超参数设置
- 隐藏层数
- 每个隐藏层大小:每层隐藏层神经元个数
超参数的设置需要根据经验,越复杂的输入,参数越复杂
- 模型越复杂,$K_1$ 越大
数据比较难:
- 单隐藏层,$K_1$ 设置大一些
- 网络层数深一些,相对单隐藏层的 $K_1$ ,多隐藏层的 $K_1$ 会小一些,$K_1>K_2>K_3$
数据复杂时,输入规模是比较大的,输出相对小,从输入到输出可以理解为一个压缩过程,这个压缩过程应该是逐渐变小的,这样损失的信息才最小
第一隐藏层可以选择较大的神经元,也可以对输入进行扩充,但一般不会在非第一隐藏层之后进行扩充,信息压缩后再复原是比较难得
3.1.3 MLP实现
将Fashion-mnist数据集用MLP训练
1 | import torch |
同样训练10轮,损失降了,但精确度没降
3.1.4 基于Pytorch的MLP实现
1 | import torch |
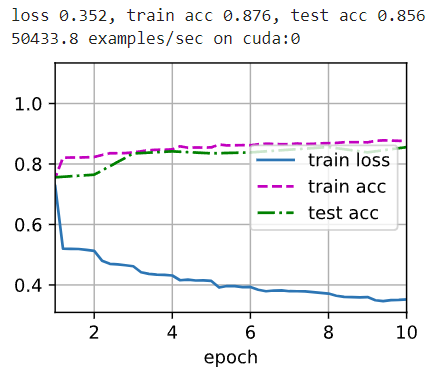
过程中还是有一定的过拟合
3.2 全连接前馈神经网络
前馈神经网络(Feedforward Neural Network,FNN)也称为多层感知器(实际上前馈神经网络由多层softmax回归模型组成)
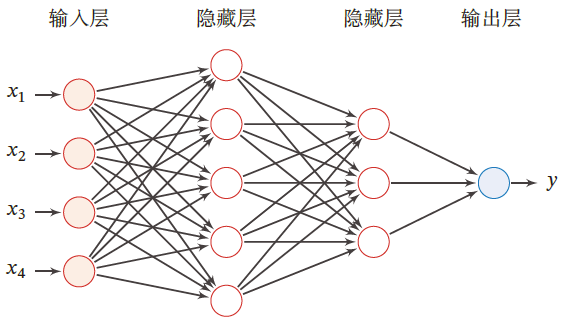
前馈神经网络中,各个神经元属于不同的层
每层神经元接收前一层神经元的信号,并输出到下一层
- 输入层:第0层
- 输出层:最后一层
- 隐藏层:其他中间层
整个网络中无反馈,信号从输入层向输出层单向传播,可用一个有向无环图表示
3.2.1 符号说明
超参数
| 符号 | 含义 |
|---|---|
| $L$ | 神经网络层数 |
| $M_l$ | 第 $l$ 层神经元个数 |
| $f_l(\cdot)$ | 第 $l$ 层神经元的激活函数 |
参数
| 符号 | 含义 |
|---|---|
| $\mathbf{W}_{l}\in \mathbb{R}^{M_l\times M_{l-1}}$ | 第 $l-1$ 层到第 $l$ 层的权重矩阵 |
| $\mathbf{b}_{l}\in \mathbb{R}^{1\times M_l}$ | 第 $l-1$ 层到第 $l$ 层的偏置 |
活性值
| 符号 | 含义 |
|---|---|
| $\mathbf{o}_{l}\in\R^{1\times M_l}$ | 第 $l$ 层神经元的净输入(净活性值) |
| $\mathbf{h}_{l}\in \mathbb{R}^{1\times M_{l}}$ | 第 $l$ 层神经元的输出(活性值) |
3.2.2 信息传播公式
神经网络的第 $l$ 层有 $M_l$ 个神经元,相应的有 $M_l$ 个净输入和活性值,所以二者需要由 $\mathbb{R}^{1\times M_l}$ 维向量来表示
第 $l$ 层的输入为第 $l-1$ 层的活性值,相应的为 $\mathbb{R}^{1\times M_{l-1}}$ 向量
故第 $l$ 层神经元的净输入需要经过一个 仿射变换,即
获取活性值 $\mathbf{h}_{l}$ 需要经过一个 非线性变换
进而可知,由输入到网络最后的输出 $\mathbf{h}_{L}$
其中 $\mathbf{W},\mathbf{b}$ 表示网络中所有层的连接权重和偏置
前馈神经网络可以通过逐层的信息传递,整个网络可以看做一个复合函数 $\phi(\mathbf{x};\mathbf{W};\mathbf{b})$
通用近似定理

根据通用近似定理,对于具有 线性输出层 $z^{(l)}$ 和至少一个 具有挤压性质的激活函数 $\phi(\cdot)$ 的隐藏层组成的前馈神经网络,只要隐藏层的神经元数量足够,就可以以任意精度来近似任何一个定义在实数空间中的有界闭函数
3.2.3 应用于分类任务
神经网络可以作为一个万能函数,用于进行复杂的特征转换或逼近一个条件分布
在机器学习中,输入样本的特征对分类器性能的影响很大
若要获得很好的分类效果,需要将样本的原始特征向量 $\mathbf{x}$ 转换到更有效的特征向量 $\phi(x)$ ——特征抽取
多层前馈神经网络恰好可以看做一个非线性函数 $\phi(\cdot)$ ,将输入 $\mathbf{x}\in \mathbb{R}^{1\times d}$ 映射到输出 $\phi(x)\in \mathbb{R}^{K}$ ,因此可将多层前馈神经网络看作一种特殊的特征转换方法,其输出 $\phi(x)$ 作为分类器的输入
- $g(\cdot)$ 为分类器
- $\theta$ 为分类器 $g(\cdot)$ 的参数
- $\hat{\mathbf{y}}$ 为分类器输出
若分类器 $g(\cdot)$ 为 $Logistic回归$ 或 $Softmax回归$ ,则相当于在输出层引入分类器,神经网络直接输出在不同类别的条件概率 $p(\hat{\mathbf{y}}\vert \mathbf{x})$
二分类问题
对于二分类问题 $y\in \{0,1\}$ ,且采用 $Logistic回归$ ,神经网络的输出层只有一个神经元,其激活函数是 $Logistic函数$
多分类问题
对于多分类问题 $y\in \{1,\cdots,K\}$ ,如果使用 $Softmax$ 分类器,网络最后一层设置 $K$ 个神经元,其激活函数为 $Softmax$ ,网络最后一层的输出可以作为每个类的条件概率
其中,$\mathbf{o}_{L}\in \mathbb{R}^{1\times K}$ 为第 $L$ 层神经网络的净输出, $\hat{\mathbf{y}}\in\R^{1\times K}$ 为第 $L$ 层神经网络的活性值,每一维分别表示不同类别标签的预测条件概率
3.2.4 参数学习与误差反向传播
参数学习
对于一个训练样本 $(\mathbf{x},\mathbf{y})$ ,使用有 $L$ 层的神经网络,第 $l$ 层的活性值为 $\mathbf{h}_l$
其中,$\mathbf{h}_{l-1}\in \mathbb{R}^{1\times M_{l-1}}$ ,$\mathbf{W}\in\R^{M_{l}\times M_{l-1}}$ ,$\mathbf{b}_l\in \mathbb{R}^{1\times M_l}$
输出层 $\hat{\mathbf{y}}=f_L\circ f_{L-1}\cdots \circ f_1(\mathbf{x})$
若采用交叉熵损失函数,其损失函数为
给定训练集,$\mathcal{D}=\{(\mathbf{x}_i,\mathbf{y}_i)\}_{i=1}^N$ ,将每个样本 $\mathbf{x}_i$ 输入给前馈网络得到 $\hat{\mathbf{y}}_i$ ,其结构化风险函数为
$\lambda$ 为超参数,$\lambda$ 越大,$\mathbf{W}$ 越接近于0
一般用 $Frobenius$ 范数(F范数)作为惩罚项
对于某一层网络参数,可以通过梯度下降的方法学习
可见,参数求解的核心部分为 $\frac{\partial \ell(\mathbf{y}_i,\hat{\mathbf{y}}_i)}{\partial \mathbf{W}_{l}}$ ,标量对矩阵的求导,事实上是对逐个元素求导,即
隐藏层求导
计算 $\frac{\partial \mathbf{o}_l}{\partial \mathbf{W}_l},\frac{\partial \mathbf{o}_l}{\partial \mathbf{b}_l}$ ,其中:
因 $\mathbf{o}_l=\mathbf{h}_{l-1}\mathbf{W}_l^T+\mathbf{b}_l$
计算 $\frac{\partial \mathbf{o}_l}{\partial \mathbf{W}_l}\in \mathbb{R}^{M_l\times 1}$
其中,$i\in [1,M_l],j\in [1,M_{l-1}]$
所以有 $\frac{\partial \mathbf{o}_l}{\partial \mathbf{W}_l}\in \mathbb{R}^{M_l\times M_l\times M_{l-1}}$
计算 $\frac{\partial \mathbf{o}_l}{\partial \mathbf{b}_l}$
其中,$i\in [1,M_l]$
误差项求导
误差项 $\frac{\partial \ell(\mathbf{y}_i,\hat{\mathbf{y}}_i)}{\partial \mathbf{o}_{l}}$ 表示第 $l$ 层神经元对最终损失的影响,也反映了最终损失对第 $l$ 层神经元的敏感程度,不同神经元对网络能力的贡献程度,从而比较好地解决了贡献度分配问题
其中,
$\frac{\partial \mathbf{h}_l}{\partial \mathbf{o}_l}\in \mathbb{R}^{M_l\times M_l}$
由于第 $l+1$ 层输入 $\mathbf{x}_{l+1}$ 为第 $l$ 层活性值 $\mathbf{h}_l$ ,$\mathbf{o}_{l+1}=\mathbf{x}_{l+1}\mathbf{W}_{l+1}^T+\mathbf{b}_{l+1}=\mathbf{h}_{l}\mathbf{W}_{l+1}^T+\mathbf{b}_{l+1}$
则有,
其中,$\odot$ 为哈达姆积,表示每个元素相乘
误差的反向传播
第 $l$ 层的误差项可以通过第 $l+1$ 层的误差项计算得到,这就是 误差的反向传播
卷积层梯度合并
所以,$\begin{bmatrix}\frac{\partial \ell}{\partial \mathbf{W}_{l}}\end{bmatrix}_{i,j}=\delta_l^{(i)}\mathbf{h}_{l-1}^{(j)}$
同理,$\ell$ 关于第 $l$ 层偏置 $\mathbf{b}_l$ 的梯度为
其中,
假设有 $L$ 层神经网络
$\mathcal{I}(\mathbf{y})$ 为 $\mathbf{y}$ 向量中元素值为1的索引
算法过程
在计算出每一层的误差项后,就可以求得本层的梯度,可以用随机梯度下降法来训练前馈神经网络
- 前馈计算每一层的净输入 $z^{(l)}$ 和净激活值 $a^{(l)}$ ,直至最后一层
- 反向传播计算每一层的误差项 $\delta^{(l)}$
- 计算每一层的偏导数,并更新参数

优化问题
神经网络的参数学习比线性模型更加困难
- 非凸优化问题
- 梯度消失问题
非凸优化问题
神经网络的优化问题是一个非凸优化问题