[TOC]
4.1 Ceph服务管理 4.1.1 sysinit 使用sysinit运行Ceph 在 RedHat 以及一些旧版的Debian/Ubuntu发行版中,sysinit是一个传统的但被推荐用于管理Ceph守护进程的方法
1 /etc/init.d/ceph [options] [command] [dameons]
[options]
1 2 3 --verbose(-v) : 用于记录详细日志 --allhosts(-a) : 在Ceph.conf提及的所有节点上执行命令,否则只在本节点上运行 --conf(-c) : 使用可选的配置文件
[command]
1 2 3 4 5 status : 显示守护进程状态 start : 启动守护进程 stop : 停止守护进程 restart : 重启守护进程 forcestop : 强制进程关闭 类似与kill -9
[dameons]
1 2 3 4 5 mon mgr osd mds ceph-radosgw
根据类型启动守护进程 若要在本机启动monitor进程
1 /etc/init.d/ceph start mon
若在本地及远程主机上启动所有的monitor进程,添加 -a 选项
1 /etc/init.d/ceph -a start mon
其他类型的进程同理
1 2 3 4 /etc/init.d/ceph -a start osd /etc/init.d/ceph -a start mgr /etc/init.d/ceph -a start mds /etc/init.d/ceph -a start radosgw
根据类型停止守护进程 1 2 3 4 5 /etc/init.d/ceph -a stop mon /etc/init.d/ceph -a stop osd /etc/init.d/ceph -a stop mgr /etc/init.d/ceph -a stop mds /etc/init.d/ceph -a stop radosgw
启动及停止所有守护进程 1 2 /etc/init.d/ceph -a start /etc/init.d/ceph -a stop
启动停止指定进程 1 2 3 4 5 /etc/init.d/ceph -a start osd.0 /etc/init.d/ceph -a status osd.0 /etc/init.d/ceph -a stop osd.0
把Ceph作为服务运行 1 service ceph [options] [command] [dameons]
[options]
1 2 3 --verbose(-v) : 用于记录详细日志 --allhosts(-a) : 在Ceph.conf提及的所有节点上执行命令,否则只在本年级上运行 --conf(-c) : 使用可选的配置文件
[command]
1 2 3 4 5 status : 显示守护进程状态 start : 启动守护进程 stop : 停止守护进程 restart : 重启守护进程 forcestop : 强制进程关闭 类似与kill -9
[dameons]
1 2 3 4 5 mon mgr osd mds ceph-radosgw
4.1.2 systemctl 开启、关闭、重启所有ceph服务
1 systemctl { start | stop | restart} ceph.target
根据 进程 类型 开启、关闭 和 重启 ceph 服务
1 2 3 4 5 6 7 8 9 10 # mon 进程 systemctl { start | stop | restart} ceph-mon.target # mgr 进程 systemctl { start | stop | restart} ceph-mgr.target # osd 进程 systemctl { start | stop | restart} ceph-osd.target # rgw 进程 systemctl { start | stop | restart} ceph-radosgw.target # mds进程 systemctl { start | stop | restart} ceph-mds.target
根据 进程 实例 开启、关闭 和 重启 所有 ceph 服务
1 2 3 4 5 6 7 8 9 10 # mon 实例 systemctl { start | stop | restart} ceph-mon@{mon_instance}.service # mgr 实例 systemctl { start | stop | restart} ceph-mgr@{hostname}.service # osd 实例 systemctl start ceph-osd@${osd_id}.service # rgw 实例 systemctl { start | stop | restart} ceph-radosgw@rgw.{hostname}.service # mds 实例 systemctl { start | stop | restart} ceph-mds@{hostname}.service
4.2 各服务的操作操作 mon 1 2 3 4 5 6 7 ceph mon remove node1 # 删除一个mon 节点 ceph-deploy mon destory {hostname [hostname ...]} 添加mon注意先改配置目录配置文件,再推送到所有节点 ceph mon add node1 node1_ip #添加一个mon节点 ceph-deploy mon create {host-name [host-name]...} ceph-deploy --overwrite-conf config push node1 node2 node3
OSD 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ceph osd stat #查看osd状态 ceph osd dump #osd的映射信息 ceph osd tree#查看osd目录树 ceph osd down 0 #down掉osd.0节点 ceph osd rm 0#集群删除一个osd硬盘 ceph osd crush remove osd.4#删除标记 ceph osd getmaxosd#查看最大osd个数 ceph osd setmaxosd 10#设置osd的个数 ceph osd out osd.3#把一个osd节点逐出集群 ceph osd in osd.3#把逐出的osd加入集群 ceph osd pause#暂停osd (暂停后整个集群不再接收数据) ceph osd unpause#再次开启osd (开启后再次接收数据) ceph osd df # 查看osd的使用信息 # 要定位对象,只需要对象名和存储池名字即可,例如: ceph osd map {poolname} {object-name}
PG相关 查看PG组的映射信息
1 2 3 4 5 6 7 8 # 查看pg状态 ceph pg stat # 查看pg组的映射信息 ceph pg dump # 或者 ceph pg ls
查看一个PG的map
获取pg的详细信息
显示一个集群中的所有的pg统计
1 ceph pg dump --format plain
mds 1 2 3 4 5 6 7 8 9 10 ceph mds stat #查看msd状态 ceph mds dump #msd的映射信息 ceph mds rm 0 mds.node1#删除一个mds节点 ceph-deploy mds create {host-name}[:{daemon-name}] [{host-name}[:{daemon-name}] ...] # 查看连接 ceph tell mds.0 client ls
多MDS变成单MDS的方法:https://www.cnblogs.com/bandaoyu/p/16752154.html#ceph%20mds
更多MDS运维命令:https://www.jianshu.com/p/fa96b66f2949
rbd https://www.cnblogs.com/bandaoyu/p/16752154.html#%E5%9D%97%E8%AE%BE%E5%A4%87%7Crbd%E7%9A%84%E4%B8%80%E4%BA%9B%E5%91%BD%E4%BB%A4
4.3 集群管理 4.3.1 池操作 rados集群池查看 1 2 3 4 5 6 7 8 9 $ ceph -s # 输出中,“pgmap” 属性包含池数量和一些对象信息 $ rados lspools data rbd metadata $ rados -p metada metadata ls
查看ceph集群中的pool数量 1 2 3 4 5 6 7 8 9 ceph osd lspools # 查看集群中的存储池名称 ceph osd pool ls # 查看池的的详细信息 ceph osd pool ls detail # 查看池的IO情况 ceph osd pool stats
池副本数 1 2 3 4 5 6 7 # 查看ceph 池副本数 ceph osd dump | grep size # 修改已存在池的副本数 ceph osd pool set <poolname> size|min_size <val> # 修改默认的池副本数 ceph config set global osd_pool_default_size/min_size <val>
在ceph集群中创建一个pool
1 2 3 $ ceph osd pool create [池名] [PG数] [PGP数] # 这里的100指的是PG组: ceph osd pool create <poolname> <num_pg> <num_pgs>
删除池 1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 修改参数配置项允许删除池 ceph config get mon.ceph01 mon_allow_pool_delete ceph config set global mon_allow_pool_delete true $ ceph osd pool delete [池名] [池名] --yes-i-really-really-meant-it # 或 vi /etc/ceph/ceph.conf [mon] mon allow pool delete = true # 重启ceph-mon服务: systemctl restart ceph-mon.target
删除池时会删除所有该池的所有快照。
如果为池手动增加了CRUSH规则集,在删除池后,需要手动删除该CRUSH规则集 如果为池的某个用户创建了一个权限,也需要删除该用户 显示集群中pool的详细信息
1 2 # 显示集群中pool的详细信息 rados df
显示集群中pool的详细信息 1 ceph osd pool get <pool_name> pg_num
池属性查看与修改 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 $ ceph osd pool get [池名] 属性名 $ ceph osd pool set [池名] [属性名] [属性值] # 获取现有PG 和 PGP $ ceph osd pool get data pg_num $ ceph osd pool get data pgp_num # 修改PG和PGP $ ceph osd pool set data pg_num 256 $ ceph osd pool set data pgp_num 256 ceph osd pool set <pool_name> target_max_bytes 100000000000000#设置data池的最大存储空间为100T(默认是1T) ceph osd pool set <pool_name> size 3 #设置data池的副本数是3 ceph osd pool set <pool_name> min_size 2 #设置data池能接受写操作的最小副本为2 ceph osd pool set <pool_name> pg_num 100#设置一个pool的pg数量 ceph osd pool set <pool_name> pgp_num 100#设置一个pool的pgp数量 # 重命名池 $ ceph osd pool rename [池名] [新池名]
4.3.2 rados操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # 查看ceph集群中有多少个pool (只是查看pool) rados lspools # 查看存储池使用情况:多少个pool,每个pool容量及利用情况 rados df # 创建一个pool,名字:test rados mkpool test # testpool 中创建一个对象 testobject rados create testobject -p testpool # 删除(test 存储池的)一个对象object rados rm test-object-1 -p test # 查看存储池test 的对象 rados -p test ls
rados存储池快照 1 2 3 4 5 6 7 8 9 10 rados mkpool testpool rados -p testpool create testobject rados -p testpool ls rados -p testpool ls |more # 存储池快照 rados -p testpool mksnap testpoolsnap # 存储池快照查看 rados -p testpool lssnap # 删除存储池快照 rados -p testpool rmsnap testpoolsnap
rados 上传一个文件到存储池 1 2 3 4 5 6 # ls cfg.txt # rados -p coolpool put cfg cfg.txt # rados -p coolpool ls coolobject cfg
池中对象 1 2 3 4 5 6 # 将指定文件转换为对象,并放入指定池中 $ rados -p [池名] put [对象名] [文件路径] # 从池中移除对象 $ rados -p [池名] rm [对象名] # 查看池中对象 $ rados -p [池名] ls
池快照 1 2 3 4 5 6 7 8 9 10 # 创建快照 $ rados mksnap [快照名] -p [池名] # 查看快照 $ rados lssnap-p [快照名] # 查看指定池的快照中指定对象 $ rados -p [池名] listsnaps [对象名] # 快照回滚 $ rados rollback -p [池名] [对象名] [快照名]
4.3.3 设备管理 设备管理允许 Ceph 解决硬件故障。
设备跟踪 查看正在使用的存储设备的列表
Ceph 跟踪硬件存储设备(HDD、SSD)以查看哪些设备由哪些守护进程管理
1 2 ceph device ls-by-daemon <daemon> ceph device ls-by-host <host>
要检索设备存储的运行状况指标(可以选择特定时间戳),请运行以下形式的命令:
1 ceph device get-health-metrics <devid> [sample-timestamp]
用户认证 https://www.cnblogs.com/bandaoyu/p/16752154.html#%E7%94%A8%E6%88%B7%E5%92%8C%E8%AE%A4%E8%AF%81
ceph-deploy https://www.cnblogs.com/bandaoyu/p/16752154.html#ceph-deploy
4.2 管理CRUSHMAP 4.2.1 CRUSHMAP的管理思路 在 ceph-deploy 部署完Ceph后,生成一个默认的 CRUSH map,生产环境中需要定制 CRUSHMAP
对CRUSHMAP的管理思路:
在任意Monitor上获取集群CRUSHMAP信息 反编译CRUSHMAP 自定义修改 编译CRUSHMAP 将编译完成的CRUSHMAP注入Ceph集群中,CRUSHMAP会实时生效 1 2 3 4 5 6 7 8 # 在任一个monitor节点上提取CRUSHMAP $ ceph osd getcrushmap -o crushmap.txt $ crushtool -d crushmap.txt -o crushmap-decompile $ vim crushmap-decompile $ crushtool -c crushmap-decompile -o crushmap-compiled $ ceph osd setcrushmap -i crushmap-compiled
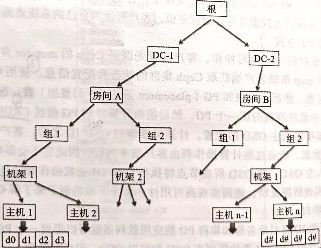
4.2.2 CRUSHMAP定义 CRUSH map:从软件角度表示集群的物理布局
包含:OSD设备定义、Bucket节点定义、bucket实例定义、root节点定义、查找规则
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # begin crush map ... # devices // OSD设备 device 0 osd.0 class hdd ... # bucket //bucket节点情况 ... # bucket instances //bucket实例 ... # rules //可定制的规则 rule replicated_rule # end crush map
设备列表(device) 包含所有的OSD的信息,由Ceph自行管理
在一个Ceph集群中,无论何时新增或移除一个新的OSD,CRUSH map设备列表都会自动更新。 若自行修改,则需要为OSD标注唯一的设备号
1 2 3 4 5 # devices device 0 osd.0 device 1 osd.1 device 2 osd.2 ......
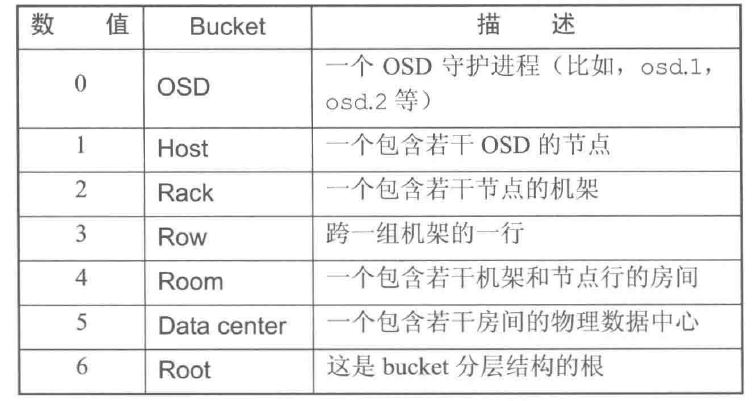
bucket类型(Bucket types) 定义了CURSH map中会用到的bucket类型,表示OSD在CRUSH分层结构中的位置
节点bucket(nodes)表示物理位置,叶子bucket(leaves)表示OSD(ceph-osd+底层物理设备)
Bucket由物理位置(磁盘、节点、机架(rack)、行(row)、开关、电源电路、房间、数据中心)的分层聚合以及它们被分配的权重(weights)组成。
CRUSH map包含很多默认的bucket类型,可以自行添加或删除bucket类型
1 2 3 4 5 6 7 8 9 10 11 12 # types type 0 osd type 1 host #主机 type 2 chassis #机箱 type 3 rack #机架 type 4 row #行 type 5 pdu type 6 pod type 7 room #房间 type 8 datacenter # 数据中心 type 9 region type 10 root #Ceph集群名
bucket实例(Bucket instances) CRUSH map文件的buckets段定义了CRUSH层次结构中的bucket实例。
1 2 3 4 5 6 7 8 9 10 [bucket-type] [bucket-name] { # bucket-type必须在types段定义 # bucket name为唯一的名称字符串 id [CRUSHMAP内一个唯一的负整数] type [bucket类型] weight [相对权重=子节点权重和/与当前bucket总设备容量相关的权重和] alg [bucket算法类型:uniform | list | tree | straw] hash [默认为0,表示使用CURSH默认算法rjenkins1] item [设备名] weight [权重] }
如:
weight :CRUSH算法为每个OSD分配一个权重,OSD权重越大,则物理存储容量越大。权重表示物理设备间的相对差异
alg :
uniform:所有存储设备权重相等。当权重不统一时不能使用。在这种类型的bucket中添加或删除设备时数据都会被重新平衡(reshuffling of data)
List:bucket将内容聚合成链表,新设备以头插法的方式插入。数据迁移最少,但移动存储设备会产生很多的数据移动。
适合很少或从不添加设备的场景,适合小集群,不适合大集群
tree:bucket被组织为带权二叉树,每个根节点都知道左右子树的总权重。提供优异的性能和重组效率
适合大项目,比链表式bucket高效
straw:在列表和树型bucket中选择一个设备时,需要计算一定数量的Hash和相对权重。采用分治法,给一些特定设备赋予更高优先级(列表开头的项目)。这会改善副本放置过程的性能,但在bucket被添加、删除或调整权重时产生重组
straw允许副本公平的放置在所有设备上。
适合:有设备删除但重组性能也很重要的场景
1 2 3 4 5 6 7 8 9 10 11 12 # 原版straw max_x = -1 ; max_item = -1 ; for each item: # x为某节点hash值的后32位,从概率上x是随机的,介于0~65535间 x = random value from 0. .65535 # 权重因子运算中涉及的scaling factor,不但与本节点的权重因子值有关,还与同级其他节点的权重因子值有关 x *= scaling factor if x > max_x: max_x = x max_item = item return item=
straw2 :改进的straw算法,减少了集群发生改变后的数据移动量
在straw2模式下,仅下属子节点的权重值参与运算 ,因此一个OSD的权重变化时对整体的影响有限,权重变化时不会发生大规模数据迁移
1 2 3 4 5 6 7 8 9 10 11 12 # straw2 max_x = -1 ; max_item = -1 ; for each item: # x为某节点hash值的后32位,从概率上x是随机的,介于0~65535间 x = random value from 0. .65535 # 权重因子运算只与当前节点的权重有关,某一OSD权重值的调整仅影响该OSD节点所在的分支,不会影响其他节点 x = (2 ^44 *log2 (x+1 )-0x1000000000000 )/weight if x > max_x: max_x = x max_item = item return item
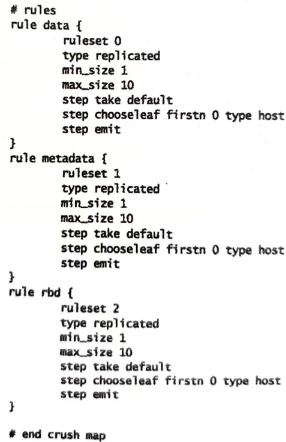
规则集(rules) 定义了如何从池中选择合适的bucket用于数据存放
要为每个池创建对应的CURSH规则集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 rule <rulename>{//规则名称,Pool基于规则名称与规则关联 id <ruleset id> #整数值 # 表示副本策略 type [replicated | erasure] # 多副本策略时,限制副本数量 min_size <min-size> max_size <max-size> # 选择一个bucket节点作为寻址起点,从该节点向下查找,default表示root step take <bucket-type> # 选择故障域模式 # - firstn 0表示按照副本数选择OSD # - type host 表示故障域为host级,同一PG的目标OSD组成员应位于不同故障域 step [choose | chooseleaf] [firstn | indep] <N> <bucket-type> step emit }
step chooseleaf firstn {num} type {bucket-type}
选择 {bucket-type} 类型的一组bucket,并从各bucket的子树里选择一个叶子节点。这个数字通常是存储池的副本数
N为池副本数
num==0,选择N个bucket 0<num<N,选择num个bucket 若num<0,则选择 N-num个bucket num=1,N=3,step choose firstn 1 type row 表示选择一个row类型的bucket
num=0,N=3,step chooseleaf firstn 0 type row 表示选择3个row类型的bucket,从各row的子树中各选一个叶子节点(osd)
4.2.3 向集群导入CRUSHMAP并与池关联 1 2 3 4 5 6 7 # 重新编译新的CRUSH map $ crushtool -c crushmap-decompile -o crushmap-compiled # 将新的CRUSH map应用到Ceph集群中 $ ceph osd setcrushmap -i crushmap-compiled # 将新建的CRUSH rule与指定池关联 ceph osd pool set PoolName crush_rule <rulename>
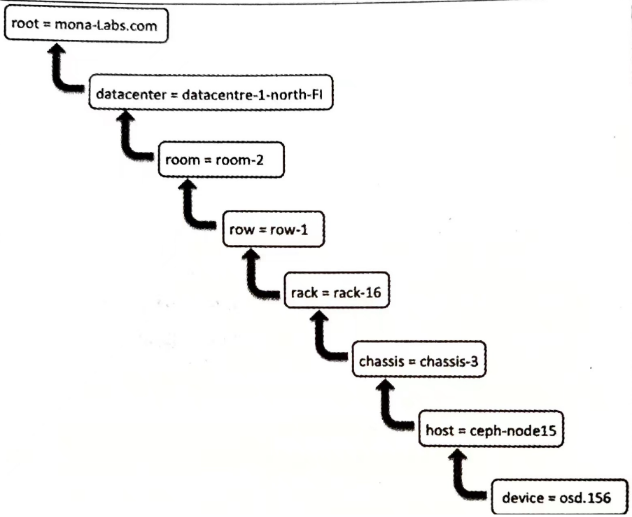
其他 CRUSH定位 CRUSH定位就是确定一个OSD在CRUSH map中的位置
Ceph中的各种map Ceph monitor 负责监控整个集群的健康状态,以及维护集群成员关系状态 (cluster membership state)、对等节点(peer nodes)的状态,和集群的配置信息等。
Ceph monitor通过维护 cluster map 的主复制来实现这些功能。cluster map 是多个 map 的组合,包括monitor map、OSD map、PG map、CRUSH map 以及MDS map 等。这些map统称为 cluster map。
monitor map 集群ID monitor 节点名称(hostname)、IP地址和端口号等 monitor map 被创建以来的最新版本号(epoch:每种 map 都维护着其历史版本,每个版本被称为一个epoch,epoch是一个单调递增的序列),以及最后修改时间等。 OSD map 集群ID 关于OSD的信息:数目、状态、权重、最近处于clean状态的间隔(last clean interval)及OSD主机等信息 OSD map创建版本和最后一次修改信息 与池相关的信息:池名、池ID、类型、副本级别(replication level)和PG PG map 最新的OSD map版本 PG的版本、时间戳、容量充满比例(禁止客户端读写)以及容量接近充满(集群发出告警)的比例 跟踪每个PG ID(poolname.pgID)、对象数、状态时间戳、OSD的up集(所有副本所在OSD的有序列表,第一个为主OSD)、acting集(所有副本所在OSD的列表) CRUSH map 集群的存储设备信息、故障域层次结构 在故障域中定义如何存储数据的规则 MDS map 集群中MDS的数目以及MDS状态 当前MDS map的版本,创建时间和修改时间 数据和元数据池的ID 4.2 将池放置于不同OSD 实际生产中,需要在多种类型的存储设备上创建存储集群
基于SSD磁盘可以提供快速存储池 对于不需要更好的I/O性能的数据,可以在较慢的磁盘驱动器创建存储池 假设:
ceph-node1有三个SSD,ceph-node2和ceph-node3分别有三个SATA磁盘
现要创建一个ssd池和一个sata池,ssd池的主副本都在ceph-node1上,sata池的主副本交叉存放于ceph-node2和ceph-node3上
4.2.1 获取CURSH map 从任一个monitor节点上提取CRUSH map并反编译
1 2 $ ceph osd getcrushmap -o crushmap-extract $ crushtool -d crushmap-extract -o crushmap-decompiled
4.2.2 编辑CRUSH map 1 $ vim crushmap-decompiled
buckets定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 # buckets host ceph-node1 { id -2 weight 0.030 alg straw hash 0#rienkins1 item osd.0 weight 0.010 item osd.1 weight 0.010 item osd.2 weight 0.010 } host ceph-node2 { id -3 weight 0.030 alg straw hash 0#rjenkins1 item osd.3 weight 0.010 item osd.4 weight 0.010 item osd.5 weight 0.010 } host ceph-node3 { id -4 weight 0.030 alg straw hash 0#rjenkins1 item osd.6 weight 0.010 item osd.7 weight 0.010 item osd.8 weight 0.010 } root ssd{ id -1 alg straw hash 0 item ceph-node1 weight 0.03 } root sata{ id -5 alg straw hash 0 item ceph-node2 weight 0.03 item ceph-node3 weight 0.03 } # end buckets
ruleset
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 # rule data { ruleset 0 type replicated min_size 1 maxsize 10 step take sata #修改,用sata 代替default step chooseleaf firstn 0 type host step emit } rule metadata { ruleset 1 type replicated min_size 1 maxsize 10 step take sata step chooseleaf firstn 0 type host step emit } rule rbd { ruleset 2 type replicated minsize 1 max_size 10 step take sata step chooseleaf firstn 0 type host step emit }
定义规则
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 rule sata{ ruleset 3 type replicated minsize 1 max_size 10 step take sata # step chooseleaf firstn 0 type host step emit } rule ssd{ ruleset 4 type replicated minsize 1 max_size 10 step take ssd # step chooseleaf firstn 0 type host step emit }
4.2.3 应用CRUSH map的修改 1 2 crushtool -c crushmap-decompiled -o crushmap-compiled ceph osd setcrushmap -i crushmap-compiled
一旦将新的CRUSH map注入到Ceph集群,集群将会发生数据调整和数据恢复,并且很快进入 HEALTH_OK 状态
4.2.4 创建池 一旦集群处于健康状态,创建ssd池和sata池
1 2 ceph osd pool create sata 64 64 ceph osd pool create ssd 64 64
为池指定规则
1 2 3 ceph osd pool set sata crush_ruleset 3 ceph osd pool set ssd crush_ruleset 4 ceph osd dump | egrep -i "ssd|sata"
4.2.5 向指定池写入数据 1 2 3 4 5 6 7 8 9 10 11 # 创建数据文件 dd if=/dev/zero of=sata_data bs=1M count=32 conv=fsync dd if=/dev/zero of=ssd_data bs=1M count=32 conv=fsync # 将文件放入Ceph集群上指定的池中 rados -p ssd put ssd_data_object ssd_data rados -p ssd put sata_data_objec sata_data # 在OSD map中检查池中对象的信息 ceph osd map ssd ssd_data_object ceph osd map sata sata_data_object
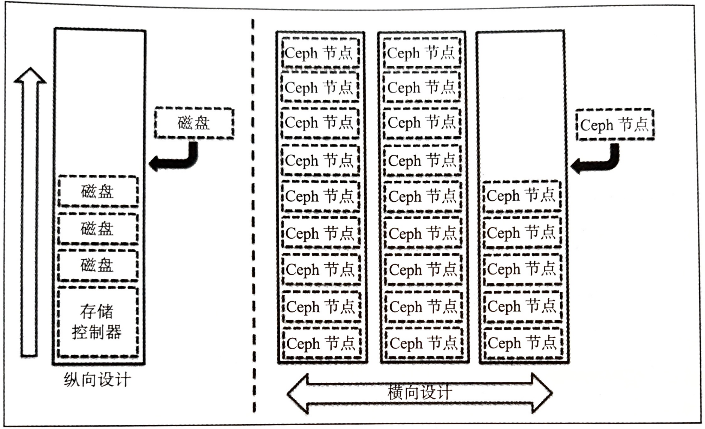
4.3 横向扩展/缩容OSD集群 存储系统纵向扩展的设计方法:
向已有设备中添加磁盘,但到达一定程度后,会成为性能、容量以及可管理性方面的瓶颈 存储系统横向扩展的设计方法:
Ceph是一个无缝可扩展的存储系统,允许在线添加monitor和OSD节点到现有集群中,同时不造成服务下线
4.3.1 向Ceph中添加OSD节点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 查看当前集群osd的详细情况 ceph osd tree # 在客户端client上制造ceph集群上的工作负载,模拟在线扩容 dd if=/dev/zero of=/mnt/ceph-voll/file1 bs=1M count=10240 # 支持在Ceph集群写入时,对集群osd扩展 ceph-deploy disk zap ceph-node4:sdb ceph-node4:sdc ceph-node4:sdd ceph-deploy osd create ceph-node4:sdb ceph-node4:sdc ceph-node4:sdd # 此时可以发现容量在扩充 watch ceph status ceph osd tree - osd的up/down状态 - osd的IN/OUT状态,用1,0表示
4.3.2 从Ceph集群中移除并关闭一个OSD 移除OSD 在移除OSD前,需要确保集群有足够的空余空间存放所移除节点上的数据
1 2 3 4 5 6 7 # 查看当前集群osd的详细情况 ceph osd tree # 在客户端client上制造ceph集群上的工作负载,模拟在线缩容 dd if=/dev/zero of=/mnt/ceph-voll/file1 bs=1M count=10240 ceph osd out osd.9
当把集群中的某个OSD标记为out时,属于它的所有PG中的数据都会被迁移至集群,直至集群再次平衡
在再平衡过程中,集群会有一段时间处于不健康状态(性能会下降),但对于客户端的数据访问服务都是正常的
1 2 ceph -s #可以看到集群处于恢复模式,同时开放数服务 ceph -w #可以查看集群的恢复操作
关闭OSD进程 1 2 service ceph stop osd.9 ceph osd tree
一旦osd进程关闭,则OSD的状态是down和out
从CRUSH map中移除OSD 1 ceph osd crush remove osd.9
从CRUSH map中移除OSD后,Ceph集群的状态变为健康状态
这时看到的是osd总数是不变的,但IN和UP状态的OSD是正常的,即OSD数量>IN数量,UP数量
从OSD map中移除OSD密钥 1 2 # 移除osd的验证密钥 ceph auth del osd.9
此时,OSD总数与IN,UP状态的OSD数相等
从CRUSH map移除OSD所在节点信息 为保持集群清洁,执行一些清理操作
1 ceph osd crush remove ceph-node4
4.3.3 替换出故障的磁盘设备 首先检查集群状态ceph -s ,若集群中没有出现故障磁盘,则状态是 HEALTH_OK
一旦OSD下线,则Ceph会将该OSD标记为 down,默认等待时间为300s
1 2 3 4 5 6 ceph osd out osd.0 # 手动模拟磁盘故障 磁盘出现故障后,集群状态会变为非健康状态,会执行恢复与再平衡操作 ceph osd crush rm osd.0 #将故障OSD从CRUSH map中移除 ceph osd del osd.0 # 移除OSD的验证密钥 ceph osd rm osd.0 #从集群中移除OSD
用新磁盘替换Ceph节点中出现故障的磁盘
一旦磁盘加入,标识磁盘在操作系统中的设备号
1 2 3 4 5 6 7 8 # 罗列所有磁盘 ceph-deploy disk list ceph-node1 # 一般而言,新磁盘无分区,也可以执行分区清理工作 ceph-deploy disk zap ceph-node1:sdb # 基于磁盘创建OSD,Ceph会将其添加为osd.0 ceph-deploy --overwrite-conf osd create ceph-node1:sdb
4.6 身份验证和授权 4.6 监控集群 4.6.1 CLI 监控集群 集群健康状态 1 2 3 4 5 6 7 8 9 10 11 12 13 $ ceph -health HEALTH WARN 64 pgs degraded; 1408 pgs stuck unclean; recovery 1/5744 objects degraded (0.017%) - 集群健康状况: HEALTH_OK 健康状态 HEALTH_WARN 告警状态 - PG数量和PG状态 clean unclean - 集群对象情况 表示集群处于 recovery 状态。目前正在处理5744个对象中的一个,整个集群中有0.017%的对象处于degraded状态 $ ceph health detail 返回状态不是active和clea的PG,即unclean ,unconsistent,degrated状态的PG都会输出状态细节
集群事件 1 2 3 4 5 6 7 8 9 $ ceph -w [optionss] 实时指令,CTRL+C退出 [options] --watch-debug:只查看调试事件 --watch-info:只查看信息事件 --watch-sec:只查看安全事件 --watch-warn:只查看警告事件 --watch-error:只查看错误事件
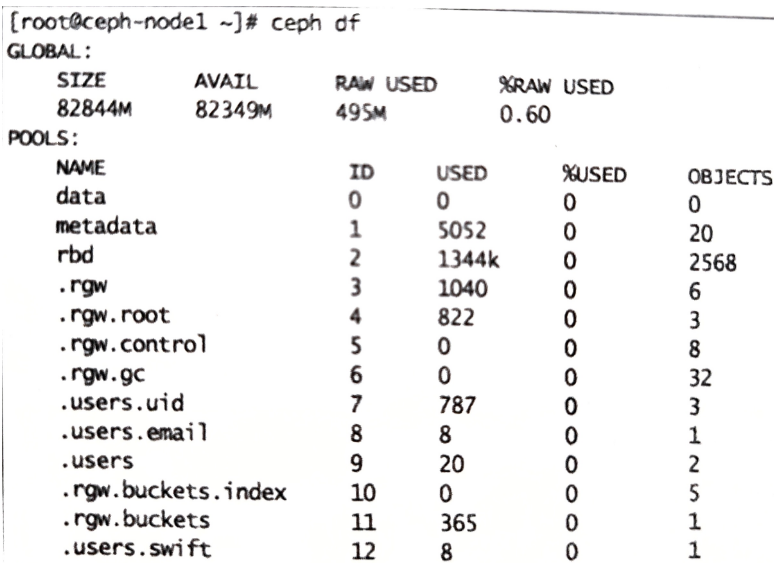
集群利用率 1 2 $ ceph df 集群总容量、可用容量、已用容量和百分比
集群组件状态 1 2 3 4 5 6 7 8 9 10 $ ceph status $ ceph -s cluster:表示Ceph唯一的集群ID health:集群的健康状态 monmap:monitor map的版本、信息、选举信息和mon法定人数 mdsmap:MDS map版本和状态 osdmap:OSD map版本和状态 pgmap:PG map版本,总的PG数,池数和总对象数 同时展示集群利用率信息(集群总容量、可用容量、已用容量和百分比)
检查集群密钥 Ceph工作在一个基于密钥的验证系统上,所有组件之间的交互都经过基于密钥的验证系统
集群映射信息 Ceph 客户端和 OSD 需要确认 集群拓扑 。由5个map表示 集群拓扑 ,统称 集群映射
监控mon Ceph 监控器(Mon)守护进程,维护集群映射的主副本。Ceph MON 集群在监控器守护进程出现故障时确保高可用性
monitor只有达到选举的法定人数才能保证集群功能正常
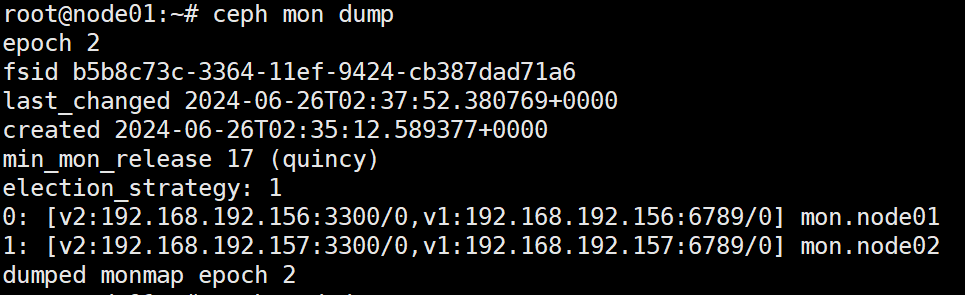
mon状态 1 2 $ ceph mon stat $ ceph mon dump
mon法定人数状态 Ceph集群中应该有超过 $\frac{1}{2}$ 的可用mon
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 $ ceph quorum_status --format json-pretty election_epoch 选举版本号 quorum_leader_name leader主机名 monmap{ 集群的monmap epoch #版本号 fsid #集群ID 集群创建、修改时间 mons:[ { rank: #为集群中的mon分配的等级 name: addr: } ] } $ ceph mon dump
集群 fsid、各个监控器的位置、名称、地址和端口,以及映射时间戳
epoch:监视器映射的时代编号。 fsid:Ceph集群的唯一标识符。 last_changed:修改监视器映射的时间。 created:创建监视器映射的时间。 min_mon_release:与监视器映射兼容的最小Ceph版本。 election_strategy:监视器用于选举领导者的策略。Ceph监视器的选举策略有两种:classic:这是默认的选举策略,在此策略下,监视器具有相同的投票权,并根据周期性心跳和消息传递进行通信。如果监视器检测到其他监视器离线,则它们将在一段时间后进入新的领导者选举过程。 quorum:该策略要求至少三个监视器在线,并从中选择领导者,而不是所有在线监视器都拥有相同的投票权。采用此策略时,如果没有足够的监视器参与选举,则集群将无法正常工作或处于只读状态,直到更多的监视器加入并恢复其大多数选举能力。 0、1、2:集群中每个监视器的排名和IP地址,以及它们的主机名。 dumped:表示已成功转储指定epoch的监视器映射。 监控mgr ceph mgr dump :显示mgr集群信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 { "epoch" : 53 , "active_gid" : 134101 , "active_name" : "node02.owpknt" , "active_addrs" : { "addrvec" : [ { "type" : "v2" , "addr" : "192.168.192.157:6808" , "nonce" : 3716212138 } , { "type" : "v1" , "addr" : "192.168.192.157:6809" , "nonce" : 3716212138 } ] } , "active_addr" : "192.168.192.157:6809/3716212138" , "active_change" : "2024-07-21T06:37:22.629953+0000" , "active_mgr_features" : 4540138320759226367 , "available" : true , "standbys" : [ { "gid" : 134102 , "name" : "node01.ohhfsw" , "mgr_features" : 4540138320759226367 , "available_modules" : [ { "name" : "xxx" , "can_run" : true , "error_string" : "" , "module_options" : { } } , ... { } ] } ] , "modules" : [ "cephadm" , "dashboard" , "iostat" , "nfs" , "prometheus" , "restful" ] , "available_modules" : [ { "name" : "xxx" , "can_run" : true , "error_string" : "" , "module_options" : { "option_name" : { "option_info_key" : option_info_value、 } } } , ] , "services" : { "dashboard" : "https://192.168.192.157:8443/" , "prometheus" : "http://192.168.192.157:9283/" } , "always_on_modules" : { "octopus" : [ xxx ] , , "pacific" : [ xxx ] , "quincy" : [ "balancer" , "crash" , "devicehealth" , "orchestrator" , "pg_autoscaler" , "progress" , "rbd_support" , "status" , "telemetry" , "volumes" ] } , "last_failure_osd_epoch" : 354 , "active_clients" : [ { "name" : "xxx" , "addrvec" : [ { "type" : "v2" , "addr" : "192.168.192.157:0" , "nonce" : 2310029076 } ] } , { } ] }
监控OSD 集群越大,OSD越多,磁盘故障可能性很高
OSD树视图 OSD的树视图用于查看OSD的in、up、out或down等状态时
OSD树视图展示了每个节点的所有OSD以及所在CRUSH map中的位置
展示了Ceph OSD的信息
输出格式会根据CRUSH map进行规则的格式化
OSD统计 输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 epoch 357 # 版本号 fsid b5b8c73c-3364-11ef-9424-cb387dad71a6 #fsid created 2024-06-26T02:35:14.490179+0000 # 创建OSD映射的时间 modified 2024-07-21T06:37:26.309666+0000 # 修改OSD映射的时间 # flags是有关 OSD映射状态的标志位,用于控制Ceph集群中OSD的行为状态、最大程度地提高性能和可靠性 # # # # flags sortbitwise,recovery_deletes,purged_snapdirs,pglog_hardlimit crush_version 20 # crush版本 # 参数配置 full_ratio 0.95 backfillfull_ratio 0.9 nearfull_ratio 0.85 require_min_compat_client luminous min_compat_client jewel require_osd_release quincy stretch_mode_enabled false # 池信息:池ID、池名、池类型(复制、擦除)、CRUSH规则集和PG规则 pool 1 '.mgr' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 350 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr pool 5 'test' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 autoscale_mode on last_change 350 lfor 0/0/279 flags hashpspool stripe_width 0 max_osd 2 # osd信息:ID、状态、权重、OSD健康状态、版本区间 osd.0 up in weight 1 up_from 356 up_thru 356 down_at 355 last_clean_interval [141,350) [v2:192.168.192.156:6800/2298987942,v1:192.168.192.156:6801/2298987942] [v2:10.168.192.156:6802/2298987942,v1:10.168.192.156:6803/2298987942] exists,up 46e1cb35-7472-4389-8d01-2d98ba4897e0 osd.1 up in weight 1 up_from 353 up_thru 356 down_at 352 last_clean_interval [143,350) [v2:192.168.192.157:6800/352260118,v1:192.168.192.157:6801/352260118] [v2:10.168.192.157:6802/352260118,v1:10.168.192.157:6803/352260118] exists,up d6d43523-a098-4cea-bb2d-42df8d102461 # 设备信息 blocklist 192.168.192.157:6809/378083828 expires 2024-07-22T06:37:22.629710+0000 blocklist 192.168.192.157:6808/378083828 expires 2024-07-22T06:37:22.629710+0000 blocklist 192.168.192.156:0/2939350335 expires 2024-07-21T12:24:54.305465+0000 blocklist 192.168.192.156:0/3581074465 expires 2024-07-21T16:49:26.573907+0000 blocklist 192.168.192.157:0/328775035 expires 2024-07-22T06:37:22.629710+0000 blocklist 192.168.192.156:6808/865415237 expires 2024-07-21T16:49:26.573907+0000 blocklist 192.168.192.157:0/1362332659 expires 2024-07-22T06:37:22.629710+0000 blocklist 192.168.192.156:0/2647831566 expires 2024-07-21T12:24:54.305465+0000 blocklist 192.168.192.156:0/1889768730 expires 2024-07-21T16:49:26.573907+0000 blocklist 192.168.192.156:6808/3436067180 expires 2024-07-21T12:24:54.305465+0000 blocklist 192.168.192.156:6809/3436067180 expires 2024-07-21T12:24:54.305465+0000 blocklist 192.168.192.156:0/3199323232 expires 2024-07-21T16:49:26.573907+0000 blocklist 192.168.192.156:0/4148433618 expires 2024-07-21T12:24:54.305465+0000 blocklist 192.168.192.156:6809/865415237 expires 2024-07-21T16:49:26.573907+0000 blocklist 192.168.192.156:0/389666931 expires 2024-07-21T12:24:54.305465+0000 blocklist 192.168.192.157:0/2326070148 expires 2024-07-22T06:37:22.629710+0000 blocklist 192.168.192.156:0/4165816795 expires 2024-07-21T16:49:26.573907+0000 blocklist 192.168.192.157:0/4198367927 expires 2024-07-22T06:37:22.629710+0000
OSD map版本
OSD ID 状态 权重 每个OSD的健康状态,版本区间等信息 池的细节
池ID 池名 池类型(复制、擦除) CRUSH 规则集和PG CRUSH map 使用CRUSH map命令行工具比手动查看和修改CRUSH map节省时间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 $ ceph osd tree $ ceph osd crush [操作] [被操作组件] [目标组件] # 在集群中添加新机架 $ ceph osd crush add-bucket rack01 rack $ ceph osd crush add-bucket rack02 rack $ ceph osd crush add-bucket rack03 rack # 移动主机到指定机架下 $ ceph osd crush move ceph-node1 rack=rack01 $ ceph osd crush move ceph-node1 rack=rack02 $ ceph osd crush move ceph-node1 rack=rack03 # 移动机架到默认根下 $ ceph osd crush move rack01 root=default $ ceph osd crush move rack02 root=default $ ceph osd crush move rack03 root=default $ ceph osd crush rule list $ ceph osd crush rule dump <crush_rule_name>
OSD 定位指令 当OSD数量多、CRUSH map层级多时,手动的 OSD 定位会很困难,需要借助CRUSH CLI
监控PG OSD 存储PG,PG包含对象
集群整体的健康状态主要取决于PG。只有PG的状态是 active+clean 状态,集群才会保持为 HELATH_OK 状态
PG的状态 分布式存储Ceph之PG状态详解
无故障操作
creating :通常当存储池正在被创建或增加一个存储池的PG数量时会出现这种状态
active :处于active状态的PG,则主PG及其副本中的数据都处于可被客户端正常IO的状态
peering(对齐) :PG的OSD都处在acting集合中。peer操作:由主OSD发起的,存储PG副本的所有OSD,就PG的所有对象和元数据状态一致。完成后,存储PG的所有OSD都彼此确认当前状态,客户端可以读写
splitting(分割中) :PG正在被分割为多个PG。
在一个存储池的PG数增加后呈现
scrubbing(清理中) :PG正在做不一致性校验
PG出错
down(失效) :包含PG必需数据的一个副本失效了,因此PG失效
degraded :PG中部分对象未达到规定副本数,处于degraded状态的PG仍可被客户端IO
OSD处于down状态,Ceph将分配到该OSD上的所有PG状态变为degraded状态
在OSD重新up之后,执行peer操作,使得所有处于degraded状态的PG变为clean
如果OSD持续处于down状态超过300s后,OSD状态变为out
Ceph将会从副本中恢复所有处于degraded状态的PG保持复制级
Ceph认为对象应该存在于某个PG中,但该对象并不可用,此时将该PG状态置为degraded并从其副本中恢复PG
remapped :当PG的acting集合变化时,会触发数据迁移。数据从老的acting集合OSD向新的acting集合OSD转移
在迁移过程中,仍然使用老acting集合中的OSD为客户端提供读写请求 迁移完成,才会启用新acting 集合中的OSD为客户端提供读写请求 inconsistent(不一致) :PG的副本出现了不一致。如:对象大小不正确,recovery后某副本出现了对象丢失
incomplete(不完整) :PG日志缺失一个时间段的数据。当包含PG所需信息的某OSD失效或不可用,会出现这种情况
stable :如果PG acting集合中的主副本OSD未向monitor报告统计结果 或 其他OSD报告主副本OSD状态变为down,则monitor将这些PG处于stable状态。
通常Peering结束前PG处于该状态
repair(修复中) :PG正在被检查,被发现的任何不一致都被尽可能地修复
OSD异常处理
backfilling :新的OSD加入集群时,Ceph通过移动其他OSD上的一些PG到新OSD上保持负载均衡。
在后台平滑地执行backfill,确保集群不会超载 backfill完成,OSD可以参与到客户端的IO操作 backfill-wait :PG正在等待回填操作
recovering :当一个OSD处于 down 状态,其PG中的内容会落后与放置在其他OSD上的PG副本。一旦该OSD处于up状态,Ceph会针对这些PG启动恢复操作,使得该PG中的数据与其他PG副本保持一致
relay(重做) :OSD崩后PG正在等待客户端重新发起请求
clean :主OSD和顺位OSD已经彼此确认;所有PG都在正确位置上,未发生偏移;所有都按副本级复制完成
监控PG 1 2 3 $ ceph pg stat vNNNN: X pgs: Y active+clean; R bytes data, u MB used , F GB/T GB aval
vNNNN:PG map版本号 X:总PG数 Y:当前状态度的PG树 R:当前集群处处的裸数据容量 U:当前集群已经存储的包含副本的真是数据容量 F:剩余容量 T:总容量 1 2 3 4 5 6 $ ceph pg dump PG_STAT OBJECTS MISSING_ON_PRIMARY DEGRADED MISPLACED UNFOUND BYTES OMAP_BYTES* OMAP_KEYS* LOG DISK_LOG STATE STATE_STAMP VERSION REPORTED UP UP_PRIMARY ACTING ACTING_PRIMARY LAST_SCRUB SCRUB_STAMP LAST_DEEP_SCRUB DEEP_SCRUB_STAMP SNAPTRIMQ_LEN 4.19 0 0 0 0 0 0 0 0 0 0 active+clean 2023-04-30T05:50:02.431578+0000 0'0 108:12 [7,2,5] 7 [7,2,5] 7 0'0 2023-04-30T05:50:01.330091+0000 0'0 2023-04-30T05:50:01.330091+0000 0 2.1f 0 0 0 0 0 0 0 0 0 0 active+clean 2023-04-30T05:49:47.320452+0000 0'0 108:17 [0,3,8] 0 [0,3,8] 0 0'0 2023-04-30T05:49:46.202749+0000 0'0 2023-04-30T05:49:46.202749+0000 0 3.1e 0 0 0 0 0 0 0 0 0 0 active+clean 2023-04-30T05:49:49.349973+0000 0'0 108:15 [2,6,3] 2 [2,6,3] 2 0'0 2023-04-30T05:49:48.270032+0000 0'0 2023-04-30T05:49:48.270032+0000 0 4.18 0 0 0 0 0 0 0 0 0 0 active+clean 2023-04-30T05:50:02.449439+0000 0'0 108:12 [3,1,6] 3 [3,1,6] 3 0'0 2023-04-30T05:50:01.330091+0000 0'0 2023-04-30T05:50:01.330091+0000 0
PG_STAT: PG 的状态,表示 PG 在当前时间点内的活动情况和健康状况。
第一部分是十六进制的 OSD 编号,第二部分是十六进制的 epoch 号
OBJECTS: PG 中对象数量。
MISSING_ON_PRIMARY: 在 primary OSD 上缺少的对象数量。
DEGRADED: 在副本 OSD 上损坏或不可用的对象数量。
MISPLACED: 在非预期 OSD 上的对象数量。
UNFOUND: 未找到的对象数量。
BYTES: PG 中对象的总字节数。
OMAP_BYTES: PG 中对象元数据的总字节数。
OMAP_KEYS: PG 中对象元数据键值对的总数。
LOG: 最近操作日志的序列号范围。
DISK_LOG: 存储在磁盘上的日志序列号范围。
STATE: PG 的状态,例如“active+clean”。
STATE_STAMP: PG 最后转换到当前状态的时间戳。
VERSION: PG 的版本。
REPORTED: 汇报 PG 状态的 OSD 的编号。
UP: 处于活动状态的 OSD 编号列表。
UP_PRIMARY: 作为主 OSD 进行同步的 OSD 编号。
ACTING: 负责读写请求的 OSD 编号列表。
ACTING_PRIMARY: 正在执行同步操作的 OSD 编号。
LAST_SCRUB: 上次 scrub 的时间戳和结果。
SCRUB_STAMP: 上次 scrub 的结束时间戳。
LAST_DEEP_SCRUB: 上次 deep scrub 的时间戳和结果。
SNAPTRIMQ_LEN: PgSnapTrimq 中等待处理的数量。
DEEP_SCRUB_STAMP: 上次 deep scrub 的结束时间戳。
1 2 3 $ ceph pg <PG_ID> query $ ceph pg 2.7d query
1 $ ceph pg dump_stuck <PG状态>
监控MDS 1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ ceph mds stat ACTIVE、INACTIVE、UP、DOWN $ ceph msd dump e1 # 当前文件系统的 epoch 号 # 文件系统是否启用了多 MDS 支持并且曾经启用过 enable_multiple, ever_enabled_multiple: 1,1 # 文件系统支持的兼容性特性:compat 表示 CephFS 要求支持的最低版本,而 rocompat 和 incompat 分别表示与只读客户端和不兼容客户端相关的特性。 compat: compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,8=no anchor table,9=file layout v2,10=snaprealm v2} # 指定将 legacy 客户端分配给文件系统的 ID,但当前没有 legacy 客户端连接到该文件系统。 legacy client fscid: -1 No filesystems configured dumped fsmap epoch 1
4.6.2 REST API Ceph自带REST API,允许用户通过编程的方式对集群进行管理,使其可以运行为一个WSGI应用或独立的服务器,默认监听5000端口
提供了一个类似Ceph命令的通过HTTP访问的接口,以HTTP GET和PUT请求的方式提交,结果以 json、XML、txt的格式返回
1 2 3 4 5 6 7 8 9 10 # 1.在Ceph集群中,创建一个用户client.restapi,授予它适当的 mon、osd 和mds权限: ceph auth get-or-create client.restapi mds 'allow' osd 'allow *' mon'allow*' > /etc/ceph/ceph.client.restapi.keyring # 2. 修改ceph.conf文件 [client.restapi] log file=/var/log/ceph/ceph.restapi.log keyring=/etc/ceph/ceph.client.restapi.keyring # 3. 执行以下命令来启动ceph-rest-api,并将它作为一个在后台独立的 Web 服务器来运行 nohup ceph-rest-api > /var/log/ceph-rest-api &> /var/log/cephrest-api-error.log&
也可以不用 nohup来运行 ceph-rest-api,但会抑制后台运行 1 2 3 4 5 # 4. ceph-rest-api将会在 0.0.0.0:5000上监听,也可以用curl访问ceph-rest-api来查询集群的健康状态: curl localhost:5000/api/v0.1/health # 5. 类似地,通过rest-api检查osd和mon的状态 curl localhost:5000/api/v0.1/osd/stat curl localhost:5000/api/v0.1/mon/stat
ceph-rest-api 支持大多数 Ceph CLI。
1 2 # 查看ceph-rest-api的可用命令 curl localhost:5000/api/v0.1
以HTML形式返回,用Web浏览器访问访问更易读
要将它运行在生产环境中,最好部署多个它的实例,每个实例都是一个封装在 Web 服务器中的 WSGI应用,前端再使用一个负载均衡器。
4.6.3 开源管理控制平台 Kraken Python,用来统计信息和监控Cepgh集群
集群数据量 mon状态 OSD状态 PG状态 支持多个mon 变更OSD操作 动态CRUSH map配置 Ceph身份验证 池操作 块设备管理 CPU、内存等系统指标 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 # 1. 安装karen依赖,如python-pip、screen和Firefox yum install python-pip screen firefox # 2. 安装开发库 yum install gcc python-deve1 libxm12-devel.x86_64 libxslt-devel.x86_64 # 3. 为karen新建目录 mkdir /karen # 4. 从github复制karen存储不哭 git clone /karendash/karendash # 5. 使用Python包管理器安装karen所需的包,如Django、python-cephclient、djangorestframework、markdown、humanize cd /karendash pip install -r requirements.txt # 6. 执行api.sh和djanfo.sh,分别调用ceph-rest-api和django python仪表盘 # 这些脚本会在独立的screen环境中执行 # CTRL+D分离当前screen会话并将其转移到后台 cp ../krakendash/contrib/*.sh ./api.sh ./django.sh # 7. 检查screen会话 ps -ef | grep -i screen # 8. 浏览器打开 localhost:8000
Ceph-dash工具 用尽可能简单的方法通过RESTful JSON API及Web GUI来提供监控Ceph集群
python wsgi的应用程序,通过librados直接与集群通信
整体集群状态及详细的问题描述 支持多个mon、支持每个mon的状态 OSD状态包含处于in、out和不健康的OSD数 可视化存储容量图 实时吞吐量,包括读写速度和每秒操作数 可视化PG状态图 集群恢复状态 在拥有wsgi的Web服务器(Apache、nginx)上部署这个应用程序
Ceph-dash访问Ceph集群是只读的,不需要任何写权限,通过Python的RADOS类来使用cepgh status命令,通过REST API或WebGUI导出输出结果
部署 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # Ceph必须安装在有Ceph访问权限的节点上 # 1. 新建目录,从github上复制存储库 mkdir /ceph-dash git clone /Crapworks/ceph-dash.git # 2. 安装python-pip yum install python-pip # 3. 安装jinja2 easy_install Jinja2 # 4. 启动Ceph-dash GUI ./ceph-dash.py # 5. 访问/localhost:5000
Calamari 4.6.4 日志 默认情况下降日志存储在 /var/log/ceph目录下
[企业级]#13故障定位方法$13.1获取集群状态