[TOC]
https://blog.csdn.net/chenxy_bwave/article/details/122617178
https://www.jianshu.com/p/bb5a7116d189
1.3 实验
OpenAI的gym库是一个环境仿真库,其中包含了很多现有环境,针对不同的控制场景,可以选择不同的环境
- 离散控制场景:输出动作是可数的,一般用雅达利环境评估
- 连续控制场景:输出动作是不可数的,一般用MuJoCo环境评估
Gym Retro是对gym库的进一步扩展,包含更多游戏
1
2
3
| pip install gym==0.25.2
若能引入gym库,则安装成功
|
gym中的强化学习框架
以Cart-Pole为例
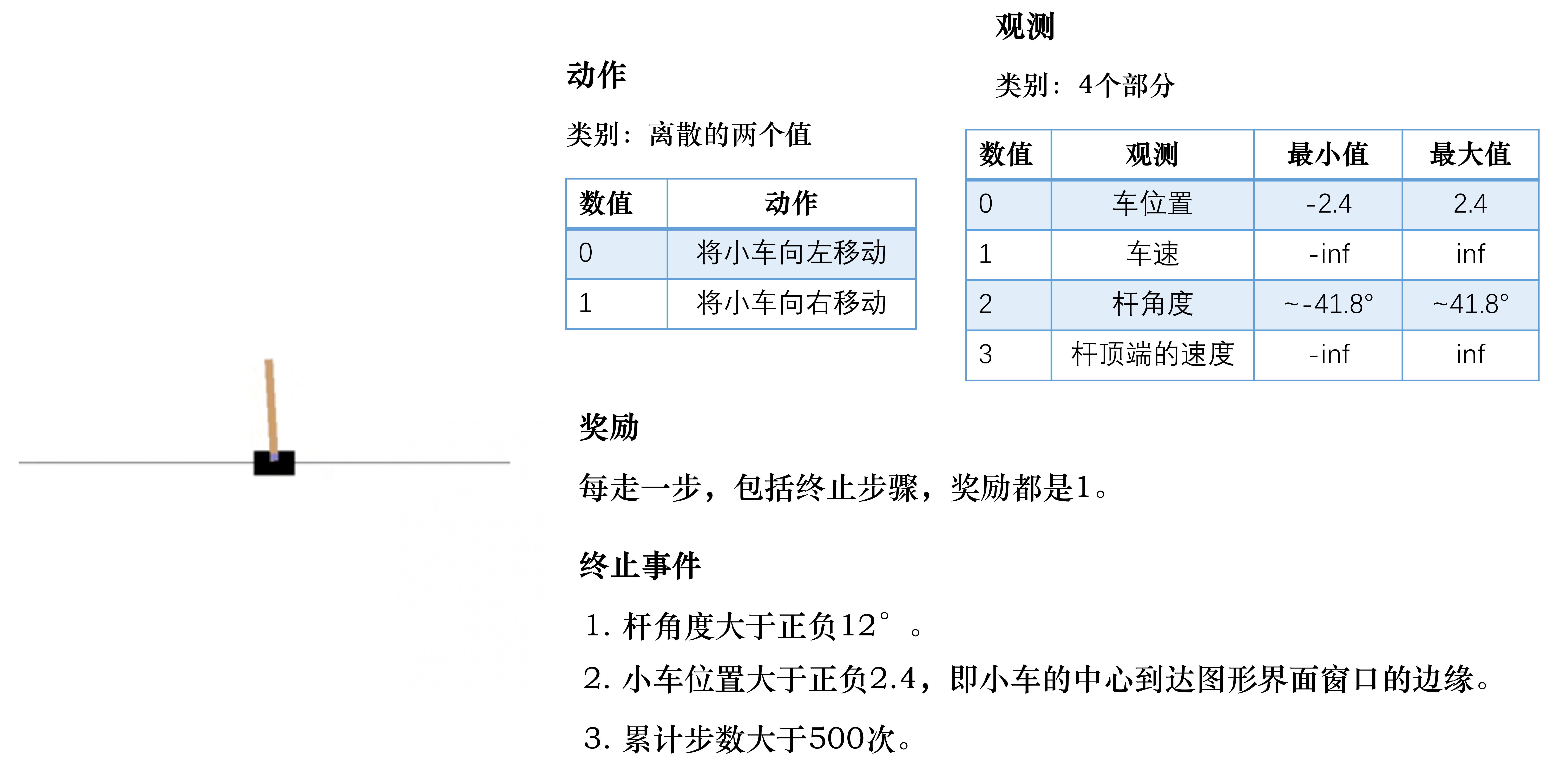
动作空间:离散,向左、向右
结束标志:
- 任务失败:杆的角度大于某个角度(未保持平衡),小车的中心到达图形界面窗口边缘
- 任务成功:累计步数大于200(成功)
目标:尽可能存活更多回合,即智能体的目的是控制杆,使其尽可能保持平衡以及尽可能保持在环境的中央
观测:小车当前位置,小车移动速度,杆的角度,杆的最高点的速度
奖励:多走一步,奖励加1
1
2
3
4
5
6
7
8
9
| import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
env.close()
|
env.action_space.sample() :在该游戏的动作空间中随机选择一个作为输出
env.step() :返回 $$
observation:状态信息,在游戏中观测到的屏幕像素值或者当前帧的状态描述信息
reward:奖励值,动作提交后能获得的奖励值,对成功完成游戏有帮助的动作得到较高的奖励值
done:表示游戏是否已经完成,若完成,则需要重置游戏并开始新的回合
info:原始的调试信息
env.step() 完成了一个完整的 $State\xrightarrow{Action} Reward\rightarrow S’$ 过程
智能体得到某个观测后,会生成下一个动作,这个动作被环境执行进入下一个状态,返回新的观测、奖励及回合结束标志
gym中的env
1
2
3
4
| from gym import envs
env_spaces = envs.registry.all()
envs_ids=[env_spec.id for env_spec in env_specs]
|
每个环境都定义了自己的观测空间和动作空间。
环境env的观测空间用 env.observation_space 表示,动作空间用 env.action_space 表示
离散空间用 gym.spaces.Discrete 表示,连续空间用 gym.spaces.Box 类表示
Box(2,) 表示观测可用2个 float 值表示
Box类实例的成员 low,high 表示每个浮点数的取值范围
Discrete(n) 表示动作取值 $0,\cdots,n-1$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
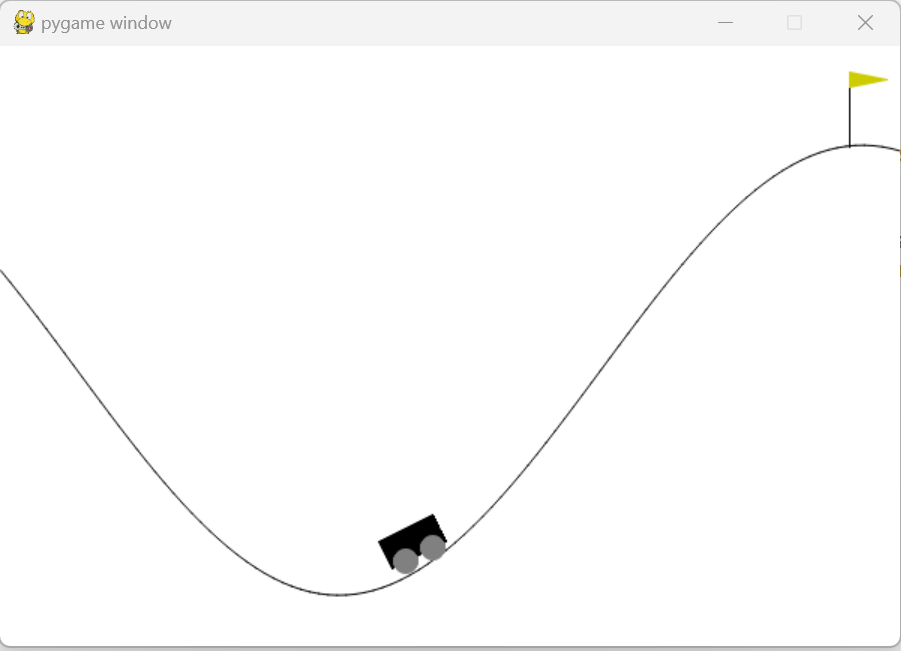
| import gym
env = gym.make('MountainCar-v0')
print('动作空间= {}'. format(env.action_space))
print('动作数= {}'. format(env.action_space.n))
print('观测空间= {}'. format(env.observation_space))
print('观测范围= {} ~ {}'. format(env.observation_space.low,env.observation_space.high))
动作空间= Discrete(3)
动作数= 3
观测空间= Box(2,)
观测范围= [-1.2 -0.07] ~ [0.6 0.07]
env.reset()
array([-0.5169839, 0. ], dtype=float32)
for _ in range(500):
env.render()
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
print(observation)
env.close()
|
智能体
实现智能体类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| class BespokeAgent:
def __init__(self, env):
pass
def decide(self, observation):
position, velocity = observation
lb = min(-0.09 * (position + 0.25) ** 2 + 0.03,0.3 * (position + 0.9) ** 4 - 0.008)
ub = -0.07 * (position + 0.38) ** 2 + 0.07
if lb < velocity < ub:
action = 2
else:
action = 0
return action
def learn(self, *args):
pass
agent = BespokeAgent(env)
|
智能体与环境交互
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| def play_montecarlo(env, agent, render=False, train=False):
episode_reward = 0.
observation = env.reset()
while True:
if render:
env.render()
action = agent.decide(observation)
next_observation, reward, done, _ = env.step(action)
episode_reward += reward
if train:
agent.learn(observation, action, reward, done)
if done:
break
observation = next_observation
return episode_reward
|
render :在运行过程中是否要图形化显示,为 True 则调用 env.render() 显示图形化,通过 env.close() 关闭train :在运行过程中是否训练智能体- 训练过程中设为
True - 测试过程中设为
False
返回值:episode_reward 返回回合奖励
主函数
1
2
3
4
5
6
7
8
9
| env.seed(0)
episode_reward = play_montecarlo(env, agent, render=True)
print('回合奖励= {}'. format(episode_reward))
episode_rewards = [play_montecarlo(env, agent) for _ in range(100)]
print('回合奖励= {}'. format(np.mean(episode_rewards))
env.close()
|
悬崖寻路实验
问题描述
智能体由48个状态,动作空间有4个动作(上下左右),每移动一步得到-1的奖励。起点和终点之间是一段悬崖,编号为37~46。有以下四点限制:
- 智能体不能移出网格,如果智能体选择的下一动作将移出网格,则不执行动作,但仍会得到 -1 的奖励
- 若智能体“掉入悬崖”,会立即回到起点位置,并得到-100的奖励
- 当智能体移动到终点,该回合结束,该回合总奖励为各步奖励之和
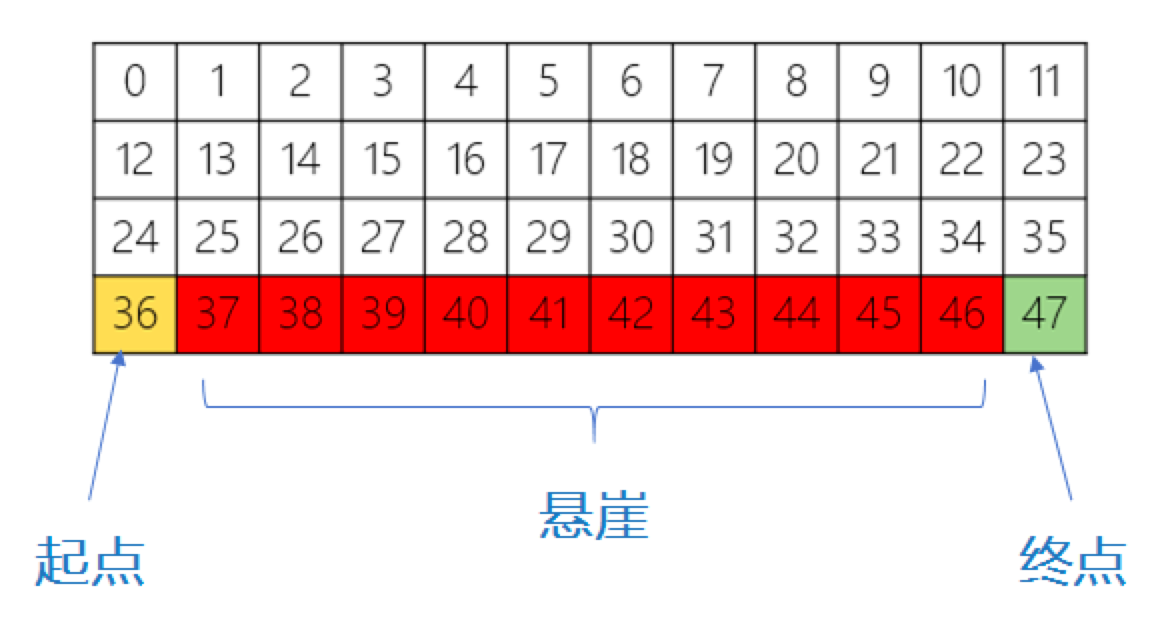
目标:以最小的移动步数到终点。
1
2
3
4
5
6
7
8
9
10
11
| import gym
from envs.gridworld_env import CliffWalkingWapper
env = gym.make('CliffWalking-v0')
env = CliffWalkingWapper(env)
n_states = env.observation_space.n
n_actions = env.action_space.n
print(f"状态数:{n_states},动作数:{n_actions}")
state = env.reset()
print(f"初始状态:{state}")
|
框架
- 初始化环境和智能体
- 对于每个回合
- 智能体选择动作
- 环境接收动作并反馈下一状态和奖励
- 智能体进行策略更新(学习)
- 多个回合收敛后,保存模型并进行后续的分析、画图等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| env = gym.make('CliffWalking-v0')
env = CliffWalkingWapper(env)
env.seed(1)
n_states = env.observation_space.n
n_actions = env.action_space.n
agent = QLearning(n_states,n_actions,cfg)
for i_ep in range(cfg.train_eps):
ep_reward = 0
state = env.reset()
while True:
action = agent.choose_action(state)
next_state, reward, done, _ = env.step(action)
agent.update(state, action, reward, next_state, done)
state = next_state
ep_reward += reward
if done:
break
|
通常需要记录与分析奖励变化情况,所以会在框架基础上增加一些变量以记录每回合奖励。此外,由于强化学习训练过程中得到的奖励可能产生振荡,所以使用一个滑动平均的量来反映奖励变化的趋势
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| env = gym.make('CliffWalking-v0')
env = CliffWalkingWapper(env)
env.seed(1)
n_states = env.observation_space.n
n_actions = env.action_space.n
agent = QLearning(n_states,n_actions,cfg)
rewards = []
ma_rewards = []
for i_ep in range(cfg.train_eps):
ep_reward = 0
state = env.reset()
while True:
action = agent.choose_action(state)
next_state, reward, done, _ = env.step(action)
agent.update(state, action, reward, next_state, done)
state = next_state
ep_reward += reward
if done:
break
rewards.append(ep_reward)
if ma_rewards:
ma_rewards.append(ma_rewards[-1]*0.9+ep_reward*0.1)
else:
ma_rewards.append(ep_reward)
|
Q-learning
https://my.oschina.net/IDP/blog/10320466
https://zhuanlan.zhihu.com/p/401914744
智能体在整个训练中只做两件事,一是动作选择,二是更新策略
1
2
3
4
5
6
7
8
9
10
|
def choose_action(self, state):
self.sample_count += 1
self.epsilon = self.epsilon_end + (self.epsilon_start - self.epsilon_end) * math.exp(-1. * self.sample_count / self.epsilon_decay)
if np.random.uniform(0, 1) > self.epsilon:
action = np.argmax(self.Q_table[str(state)])
else:
action = np.random.choice(self.action_dim)
return action
|
1
2
3
4
5
6
7
8
|
def update(self, state, action, reward, next_state, done):
Q_predict = self.Q_table[str(state)][action]
if done:
Q_target = reward
else:
Q_target = reward + self.gamma * np.max(self.Q_table[str(next_state)])
self.Q_table[str(state)][action] += self.lr * (Q_target - Q_predict)
|