https://www.cnblogs.com/bandaoyu/p/16752154.html
https://www.bunian.cn/5180.html
https://lihaijing.gitbooks.io/ceph-handbook/content/
查看信息
状态查看
1 | 查看ceph版本 |
认证信息查看
1 | 查看ceph集群中的认证用户及相关的key |
查看集群映射信息ceph dump
Ceph 客户端和 OSD 需要确认 集群拓扑 。由5个map表示 集群拓扑 ,统称 集群映射
mon 映射
Ceph 监控器(Mon)守护进程维护集群映射的主副本。Ceph MON 集群在监控器守护进程出现故障时确保高可用性
ceph mon dump 显示mon集群信息
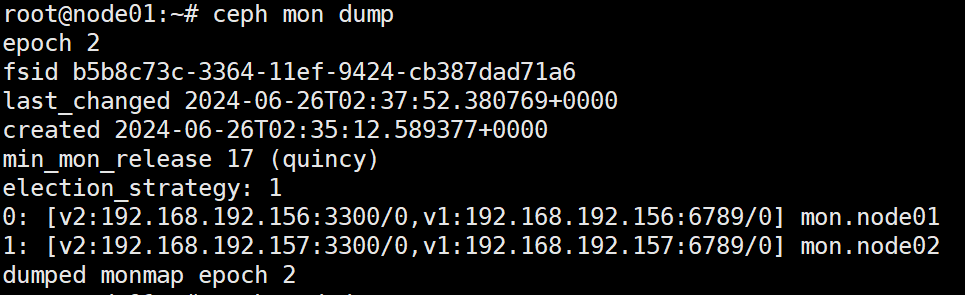
集群 fsid、各个监控器的位置、名称、地址和端口,以及映射时间戳
- epoch:监视器映射的时代编号。
- fsid:Ceph集群的唯一标识符。
- last_changed:修改监视器映射的时间。
- created:创建监视器映射的时间。
- min_mon_release:与监视器映射兼容的最小Ceph版本。
- election_strategy:监视器用于选举领导者的策略。Ceph监视器的选举策略有两种:
- classic:这是默认的选举策略,在此策略下,监视器具有相同的投票权,并根据周期性心跳和消息传递进行通信。如果监视器检测到其他监视器离线,则它们将在一段时间后进入新的领导者选举过程。
- quorum:该策略要求至少三个监视器在线,并从中选择领导者,而不是所有在线监视器都拥有相同的投票权。采用此策略时,如果没有足够的监视器参与选举,则集群将无法正常工作或处于只读状态,直到更多的监视器加入并恢复其大多数选举能力。
- 0、1、2:集群中每个监视器的排名和IP地址,以及它们的主机名。
- dumped:表示已成功转储指定epoch的监视器映射。
mgr映射
ceph mgr dump :显示mgr集群信息
1 | { |
osd 映射
ceph osd dump 查看osd集群信息
1 | epoch 357 # 版本号 |
PG映射
1 | ceph pg dump |
1 | PG_STAT OBJECTS MISSING_ON_PRIMARY DEGRADED MISPLACED UNFOUND BYTES OMAP_BYTES* OMAP_KEYS* LOG DISK_LOG STATE STATE_STAMP VERSION REPORTED UP UP_PRIMARY ACTING ACTING_PRIMARY LAST_SCRUB SCRUB_STAMP LAST_DEEP_SCRUB DEEP_SCRUB_STAMP SNAPTRIMQ_LEN |
PG_STAT: PG 的状态,表示 PG 在当前时间点内的活动情况和健康状况。
第一部分是十六进制的 OSD 编号,第二部分是十六进制的 epoch 号
OBJECTS: PG 中对象数量。
MISSING_ON_PRIMARY: 在 primary OSD 上缺少的对象数量。
DEGRADED: 在副本 OSD 上损坏或不可用的对象数量。
MISPLACED: 在非预期 OSD 上的对象数量。
UNFOUND: 未找到的对象数量。
BYTES: PG 中对象的总字节数。
OMAP_BYTES: PG 中对象元数据的总字节数。
OMAP_KEYS: PG 中对象元数据键值对的总数。
LOG: 最近操作日志的序列号范围。
DISK_LOG: 存储在磁盘上的日志序列号范围。
STATE: PG 的状态,例如“active+clean”。
STATE_STAMP: PG 最后转换到当前状态的时间戳。
VERSION: PG 的版本。
REPORTED: 汇报 PG 状态的 OSD 的编号。
UP: 处于活动状态的 OSD 编号列表。
UP_PRIMARY: 作为主 OSD 进行同步的 OSD 编号。
ACTING: 负责读写请求的 OSD 编号列表。
ACTING_PRIMARY: 正在执行同步操作的 OSD 编号。
LAST_SCRUB: 上次 scrub 的时间戳和结果。
SCRUB_STAMP: 上次 scrub 的结束时间戳。
LAST_DEEP_SCRUB: 上次 deep scrub 的时间戳和结果。
SNAPTRIMQ_LEN: PgSnapTrimq 中等待处理的数量。
DEEP_SCRUB_STAMP: 上次 deep scrub 的结束时间戳。
CRUSH 映射
1 | 需要对crushmap反编译 |
元数据服务器 (MDS) 映射
1 | ceph fs dump |
性能信息
1 | 需要再进程所在主机运行,若使用cephadm安装,需要cephadm shell |
mon
1 | ceph mon stat # 查看mon的状态 |
OSD
osd
1 | ceph osd stat #查看osd状态 |
PG相关
查看PG组的映射信息
1 | 查看pg状态 |
查看一个PG的map
1 | ceph pg map 7.1a |
获取pg的详细信息
1 | ceph pg {pg-id} query |
显示一个集群中的所有的pg统计
1 | ceph pg dump --format plain |
PG状态
池
https://www.cnblogs.com/zengzhihua/p/9884238.html
查看ceph集群中的pool数量
1 | ceph osd lspools |
池副本数
1 | 查看ceph 池副本数 |
在ceph集群中创建一个pool
1 | 这里的100指的是PG组: |
删除池
1 | 修改参数配置项允许删除池 |
显示集群中pool的详细信息
1 | 显示集群中pool的详细信息 |
显示集群中pool的详细信息
1 | ceph osd pool get <pool_name> pg_num |
修改池参数
1 | ceph osd pool set <pool_name> target_max_bytes 100000000000000#设置data池的最大存储空间为100T(默认是1T) |
rados
1 | 查看ceph集群中有多少个pool (只是查看pool) |
rados存储池快照
1 | rados mkpool testpool |
rados 上传一个文件到存储池
1 | ls |
设备管理
设备管理允许 Ceph 解决硬件故障。
设备跟踪
查看正在使用的存储设备的列表
1 | ceph device ls |
Ceph 跟踪硬件存储设备(HDD、SSD)以查看哪些设备由哪些守护进程管理
1 | ceph device ls-by-daemon <daemon> |
要检索设备存储的运行状况指标(可以选择特定时间戳),请运行以下形式的命令:
1 | ceph device get-health-metrics <devid> [sample-timestamp] |
mds
1 | ceph mds stat #查看msd状态 |
多MDS变成单MDS的方法:https://www.cnblogs.com/bandaoyu/p/16752154.html#ceph%20mds
更多MDS运维命令:https://www.jianshu.com/p/fa96b66f2949
rbd
ceph-deploy
https://www.cnblogs.com/bandaoyu/p/16752154.html#ceph-deploy
用户认证
https://www.cnblogs.com/bandaoyu/p/16752154.html#%E7%94%A8%E6%88%B7%E5%92%8C%E8%AE%A4%E8%AF%81
服务管理ceph集群
开启、关闭、重启所有ceph服务
1 | systemctl { start | stop | restart} ceph.target |
根据 进程 类型 开启、关闭 和 重启 ceph 服务
1 | mon 进程 |
根据 进程 实例 开启、关闭 和 重启 所有 ceph 服务
1 | mon 实例 |