[TOC]
install&configuration
mgr_module_path :mgr 模块的文件系统路径
mgr_initial_modules :首次启动群集时要启用的管理器模块列表
- 当集群在安装后首次启动时,监视器会读取此模块名称列表,以填充已启用的管理器模块列表。后续更新是使用“mgr module [enable|disable]”命令完成的。列表可以是逗号或空格分隔的。
mgr_disabled_modules :永远不会加载的管理器模块列表
- 以逗号分隔的模块名称列表。此列表在启动时由经理读取。默认情况下,管理器会加载指定“mgr_module_path”中的所有模块,并按照指示启动已启用的模块。此列表中的模块将完全不会加载
mgr_standby_modules :在 standby 状态的 mgr 上启动的模块,以待机(重定向)模式启动模块
默认情况下,备用模块将通过 HTTP 重定向到活动的管理器来响应传入请求,允许用户将浏览器指向任何 mgr 节点并找到指向活动管理器的方式。
但是,在使用负载均衡器时,此模式存在问题,因为 (1) 重定向位置通常是专用 IP,并且 (2) 负载均衡器无法确定哪个 mgr 是将流量发送到的正确 mgr。如果正在使用负载均衡器,请将其设置为 false。
mgr_data :加载守护进程数据的路径(例如密钥环)
mgr_tick_period :要监视的信标消息的时间段(以秒为单位)
- mgr 信标与监视器之间有多少秒,以及其他定期检查。
mon_mgr_beacon_grace :从最后一个信标到将管理器守护程序标记为失败的监视器的时间段(以秒为单位)
- mgr 心跳的宽限时长
- 从最后一个信标到监视器将管理器守护进程标记为失败的时间段(以秒为单位)
mgr_ttl_cache_expire_seconds :将生存时间设置为以秒为单位 - 设置为 0 以禁用缓存
enable module
log_level-54 个
1 | url: https://docs.ceph.com/en/quincy/mgr/modules/#logging |
This is developer documentation, describing Ceph internals that are only relevant to people writing ceph-mgr modules.
- 开发人员文档,描述与 ceph-mgr 模块相关的 Ceph 内部结构
- 只有与 Ceph-mgr 模块开发相关的开发人员才需要调整这些参数
其中 <module-name> 是开发人员待调试的 Ceph管理模块,每个模块都支持 log_level 选项,用于指定模块当前的 Python 日志记录级别。模块启动时使用的日志记录级别由 MGR 守护进程的当前日志级别决定,可以使用 config set 对 log_level 进行指定
默认的 MGR 日志级别映射到模块的 Python 日志记录级别为 :
<= 0 is CRITICAL;<= 1 is WARNING;<= 4 is INFO;<= +inf is DEBUG
1 | 通过config get/set 查看或修改当前日志记录等级 |
mgr/<module-name>/log_level 类型的参数有 27 个,取值是枚举类型
mgr/<module-name>/log_to_cluster_level 完全一致
balancer
平衡器可以优化 OSD 之间的归置组 (PG) 分配,以实现平衡分配。平衡器可以自动运行或以受监督的方式运行。
要检查平衡器的当前状态,请运行以下命令:
1 | ceph balancer status |
自动平衡
当平衡器处于upmap模式时,默认启用自动平衡功能。若要禁用,则采用以下指令
1 | ceph balancer off |
平衡器模式可以从upmap模式更改为crush-compat模式。crush-compat 模式向后兼容旧客户端。在压缩兼容模式下,平衡器会自动对数据分布进行微小更改,以确保平等地利用 OSD。
平衡计划
如果集群降级(即,如果某个 OSD 发生故障并且系统尚未自行修复),则平衡器不会对 PG 分配进行任何调整。当集群健康时,平衡器将逐步移动一小部分不平衡的 PG,以改善分布。该比例不会超过某个阈值(默认为 5% 的)。要调整此 target_max_misplaced_ratio 阈值设置,请运行以下命令:
1 | ceph config set mgr target_max_misplaced_ratio .07 # 7% |
平衡器在运行之间休眠。要设置此睡眠间隔的秒数,请运行以下命令:
1 | ceph config set mgr mgr/balancer/sleep_interval 60 |
要设置自动平衡开始的时间(采用 HHMM 格式),请运行以下命令:
平衡算法模式
https://docs.ceph.com/en/quincy/rados/operations/balancer/#modes
监督优化
- 制定计划
- 评估数据分布的质量,无论是当前的 PG 分布还是执行计划后产生的 PG 分布
- 执行计划
https://docs.ceph.com/en/quincy/rados/operations/balancer/#supervised-optimization
参数配置
mgr/balancer/active :启动集群自动平衡 PG
mgr/balancer/begin_time :一天中的开始时间自动平衡
mgr/balancer/begin_weekday :将自动平衡限制为一周中的这一天或更晚
mgr/balancer/crush_compat_max_iterations :尝试优化的最大迭代次数
mgr/balancer/min_score :最低分数,低于该分数不尝试优化
mgr/balancer/upmap_max_deviation :偏差,低于该偏差不尝试优化
- 如果 PG 的数量在此计数范围内,则不尝试优化
mgr/balancer/upmap_max_optimizations :每次尝试的upmap的最大优化次数
crash
crash module 收集有关守护进程崩溃转储的信息并将其存储在 Ceph 集群中以供以后分析。
启动crash模块
1 | ceph mgr module enable crash |
崩溃上传密钥是通过以下方式生成的:
1 | ceph auth get-or-create client.crash mon 'profile crash' mgr 'profile crash' |
在每个节点上,您应该将此密钥存储在 /etc/ceph/ceph.client.crash.keyring 中。
自动收集
https://docs.ceph.com/en/quincy/mgr/crash/#automated-collection
守护进程故障转储默认转储到 /var/lib/ceph/crash 中;这可以使用选项“crash dir”进行配置。崩溃目录按时间和日期以及随机生成的 UUID 命名,并包含元数据文件“meta”和最近的日志文件,“crash_id”相同。
使用 ceph-crash.service 可以自动提交这些崩溃并保留在监视器的存储中。它监视崩溃转储目录并使用 ceph 崩溃帖子上传它们。
指令
https://docs.ceph.com/en/quincy/mgr/crash/#commands
参数
mgr/crash/retain_interval :在修剪崩溃报告之前将崩溃保留多长时间
mgr/crash/warn_recent_interval :警告最近崩溃的时间间隔
devicehealth
设备管理允许 Ceph 解决硬件故障。 Ceph 跟踪硬件存储设备(HDD、SSD)以查看哪些设备由哪些守护进程管理。
Ceph 还收集有关这些设备的运行状况指标。通过这样做,Ceph 可以提供预测硬件故障的工具,并可以自动响应硬件故障。
设备跟踪
要查看正在使用的存储设备的列表,请运行以下命令:
1 | ceph device ls |
或者,要按守护程序或按主机列出设备,请运行以下形式之一的命令:
1 | ceph device ls-by-daemon <daemon> |
要查看有关特定设备的位置以及如何使用该设备的信息,请运行以下形式的命令:
1 | ceph device info <devid> |
识别物理设备
为了更轻松地更换故障磁盘且不易出错,您可以(在某些情况下)通过运行以下形式的命令来“闪烁”硬件外壳上的驱动器 LED:
1 | device light on|off <devid> [ident|fault] [--force] |
使用此命令使灯闪烁可能不起作用。它是否有效取决于您的内核版本、SES 固件或 HBA 设置等因素。
参数是设备标识。要检索此信息,请运行以下命令: ceph device ls[ident|fault] 参数决定哪种灯会闪烁。默认情况下,使用识别灯。
仅当启用了 Cephadm 或 Rook Orchestrator 模块时,此命令才有效。要查看启用了哪个 Orchestrator 模块,请运行以下命令:
ceph orch status使驱动器 LED 闪烁的命令是 lsmcli。要自定义此命令,请通过 Jinja2 模板运行以下形式的命令来配置它:
1
2ceph config-key set mgr/cephadm/blink_device_light_cmd "<template>"
ceph config-key set mgr/cephadm/<host>/blink_device_light_cmd "lsmcli local-disk-{{ ident_fault }}-led-{{'on' if on else 'off'}} --path '{{ path or dev }}'"以下参数可用于自定义 Jinja2 模板:
onA boolean value.
ident_faultA string that contains ident or fault.
devA string that contains the device ID: for example, SanDisk_X400_M.2_2280_512GB_162924424784.
pathA string that contains the device path: for example, /dev/sda.
启用设备监控
Ceph 还可以监控与您的设备相关的运行状况指标。例如,SATA 驱动器实施了一项名为 SMART 的标准,该标准提供了有关设备使用情况和健康状况的广泛内部指标(例如:通电时间、电源循环次数、不可恢复的读取错误数量)。其他设备类型(如 SAS 和 NVMe)提供了一组类似的指标(通过略有不同的标准)。所有这些指标都可以通过 Ceph 收集(利用 smartctl工具)。
您可以通过运行以下命令之一来启用或禁用运行状况监控:
1 | ceph device monitoring on |
抓取指标
如果启用监控,设备指标将定期自动抓取。要配置该间隔,请运行以下形式的命令:
1 | ceph config set mgr mgr/devicehealth/scrape_frequency <seconds> |
默认情况下,设备指标每 24 小时抓取一次。
要手动抓取所有设备,请运行以下命令:
1 | ceph device scrape-health-metrics |
要抓取单个设备,请运行以下形式的命令:
1 | ceph device scrape-health-metrics <device-id> |
要抓取单个守护程序的设备,请运行以下形式的命令:
1 | ceph device scrape-daemon-health-metrics <who> |
要检索设备存储的运行状况指标(可以选择特定时间戳),请运行以下形式的命令:
1 | ceph device get-health-metrics <devid> [sample-timestamp] |
故障预测
Ceph 可以通过分析其收集的运行状况指标来预测驱动器的预期寿命和设备故障。预测模式如下:
- none:禁用设备故障预测。
- local:使用来自 ceph-mgr 守护进程的预训练预测模型。
要配置预测模式,请运行以下形式的命令:
1 | ceph config set global device_failure_prediction_mode <mode> |
在正常情况下,故障预测会在后台定期运行。因此,预期寿命值可能仅在经过相当长的时间后才会填充。所有设备的预期寿命显示在以下命令的输出中:
1 | ceph device ls |
要查看特定设备的元数据,请运行以下形式的命令:
1 | ceph device info <devid> |
要明确强制预测特定设备的预期寿命,请运行以下形式的命令
1 | ceph device predict-life-expectancy <devid> |
除了 Ceph 的内部设备故障预测之外,您可能还有有关设备故障的外部信息源。要告知 Ceph 特定设备的预期寿命,请运行以下形式的命令:
1 | ceph device set-life-expectancy <devid> <from> [<to>] |
预期寿命以时间间隔来表示。这意味着预期寿命的不确定性可以用时间范围的形式来表示,也许是一个很宽的时间范围。间隔的结束时间可以不指定
健康报警
mgr/devicehealth/warn_threshold 配置选项控制预期设备故障的健康检查。如果预计设备将在指定的时间间隔内发生故障,则会发出警报。
要检查所有设备的存储预期寿命并生成任何适当的健康警报,请运行以下命令:
1 | ceph device check-health |
自动迁移
mgr/devicehealth/self_heal 选项(默认情况下启用)会自动将数据从预计很快会发生故障的设备中迁移出来。如果启用此选项,模块会将此类设备标记 out ,以便进行自动迁移。
mon_osd_min_up_ratio 配置选项可以帮助防止此进程级联至完全失败。如果“自我修复(self heal)”模块标记出过多的 OSD,以致超出了 mon_osd_min_up_ratio 的比率值,则集群将引发 DEVICE_HEALTH_TOOMANY 健康检查。
mgr/devicehealth/mark_out_threshold 配置选项指定自动迁移的时间间隔。如果预计设备在指定时间间隔内出现故障,则会自动将其标记为淘汰。
mgr/devicehealth/pool_name 要在其中存储设备运行状况指标的池的名称
mgr/devicehealth/retention_period :设备运行状况指标保留多长时间
mgr/devicehealth/self_heal :抢先修复可能发生故障的设备周围的集群
mgr/devicehealth/sleep_interval :唤醒和检查设备运行状况的频率
orchestrator
In this context, orchestrator refers to some external service that provides the ability to discover devices and create Ceph services. This includes external projects such as Rook.
- 在这种情况下,orchestrator 指的是一些提供发现设备和创建 Ceph 服务能力的外部服务。包括 Rook 等外部项目。
pg_autoscaler
mgr/pg_autoscaler/threshold :“新PG_NUM”在被接受之前必须与当前“PG_NUM”不同的因素。不能小于 1.0
progress
进度模块用于通知用户受以下事件影响的 PG(放置组)的恢复进度:
(1) OSD 被标记入或标记出以及 (2) pg_autoscaler 尝试匹配目标 PG 编号。
ceph -s 命令返回“Global Recovery Progress(全局恢复进度)”,它报告 PG 的整体恢复进度,并且基于处于 active+clean 状态的 PG 数量。
启用
进度模块默认启用,但可以通过运行以下命令手动启用:
1 | ceph progress on |
指令
显示所有正在进行和已完成的事件及其持续时间的摘要:
1 | ceph progress |
以 JSON 格式显示正在进行和已完成的事件的摘要
1 | ceph progress json |
清除所有正在进行和已完成的事件:
1 | ceph progress clear |
PG恢复事件
受恢复事件影响的每个 PG 的事件都可以在 ceph progress 中显示。这是完全可选的,并且考虑到 CPU 负载而默认禁用:
1 | ceph config set mgr mgr/progress/allow_pg_recovery_event true |
mgr/progress/max_completed_events :要记住的过去已完成事件的数量
mgr/progress/sleep_interval :模块将休眠多长时间
rbd_support
mgr/rbd_support/max_concurrent_snap_create :
status
完成
telemetry
遥测模块将有关集群的匿名数据发送回 Ceph 开发人员,以帮助了解 Ceph 的使用方式以及用户可能遇到的问题。这些数据在公共仪表板上可视化,使社区能够快速查看有关正在报告的集群数量、总容量和 OSD 计数以及版本分布趋势的摘要统计信息。
通道
遥测报告分为多个“通道”,每个通道都有不同类型的信息。假设遥测已启用,则可以打开和关闭各个通道。 (如果遥测关闭,则每通道设置无效。)
- basic(默认:on):集群的基本信息
- 集群容量
- 监视器、管理器、OSD、MDS、对象网关或其他守护程序的数量
- 当前使用的软件版本
- RADOS 池和 CephFS 文件系统的数量和类型
- 已更改默认配置选项的名称(但不更改其值)
- crash(默认:on):有关守护进程崩溃的信息,包括
- 守护进程类型
- 守护进程的版本
- 操作系统(操作系统发行版、内核版本)
- 堆栈跟踪可识别 Ceph 代码中发生崩溃的位置
- device(默认:on):有关设备指标的信息,包括
- 匿名 SMART 指标
- ident(默认值:关闭):用户提供的有关集群的标识信息
- 集群描述
- 联系电子邮件地址
- perf(默认:off):集群的各种性能指标,可用于
- 揭示集群的整体健康状况
- 确定工作负载模式
- 解决延迟、限制、内存管理等问题。
- 通过守护进程监控集群性能
报告的数据不包含任何敏感数据,例如池名称、对象名称、对象内容、主机名或设备序列号。
它包含有关集群如何部署、Ceph 版本、主机分布和其他参数的计数器和统计信息,帮助项目更好地了解 Ceph 的使用方式
数据安全发送到 https://telemetry.ceph.com。
可以通过以下方式启用或禁用各个通道:
1 | ceph telemetry enable channel basic |
1 | ceph telemetry enable channel basic crash device ident perf |
可以通过以下方式一次性启用或禁用所有通道:
1 | ceph telemetry enable channel all |
请注意,遥测必须打开才能使这些命令生效。
列出所有频道:
1 | ceph telemetry channel ls |
启用遥测
1 | ceph telemetry on |
https://docs.ceph.com/en/latest/mgr/telemetry/#enabling-telemetry
报告样本
您可以随时使用以下命令查看报告的数据:
1 | ceph telemetry show |
如果遥测关闭,您可以通过以下方式预览示例报告:
1 | ceph telemetry preview |
在大型集群(具有数百个或更多 OSD 的集群)中,生成示例报告可能需要一些时间。
为了保护您的隐私,设备报告是单独生成的,并且主机名和设备序列号等数据是匿名的。设备遥测数据被发送到不同的端点,并且不会将设备数据与特定集群关联。要查看设备报告的预览,请使用以下命令
1 | ceph telemetry show-device |
请注意:为了生成设备报告,我们使用 Smartmontools 7.0 及更高版本,它支持 JSON 输出。
如果您希望一个输出同时有两个报告,并且遥测已打开,请使用:
1 | ceph telemetry show-all |
按通道的报告示例
当遥测开启时,您可以通过以下方式查看通道报告的数据:
1 | ceph telemetry show <channel_name> |
请注意:如果遥测已打开,并且
1 | ceph telemetry preview <channel_name> |
collection
集合代表我们在渠道内收集的数据的不同方面。
1 | ceph telemetry collection ls |
NAME:集合名称; prefix 表示集合所属的频道。
status:表示是否报告集合指标;这取决于集合所属频道的状态(启用/禁用)以及集合的注册状态(用户是否选择加入此集合)。
DESC:集合的一般描述。
查看您注册的集合与新的可用集合之间的差异:
1 | ceph telemetry diff |
INTERVAL
默认情况下,模块每 24 小时编译并发送一份新报告。您可以通过以下方式调整此间隔:
1 | ceph config set mgr mgr/telemetry/interval 72 # report every three days |
手动发送遥测数据
1 | ceph telemetry send |
如果未启用遥测(“ceph telemetry on”),您需要将“—licensesharing-1-0”添加到“ceph telemetry send”命令中。
STATUS
查看当前配置:
1 | ceph telemetry status |
通过代理发送遥测数据
如果集群无法直接连接到配置的遥测端点(默认 telemetry.ceph.com),您可以使用以下命令配置 HTTP/HTTPS 代理服务器:
1 | ceph config set mgr mgr/telemetry/proxy https://10.0.0.1:8080 |
如果需要,您还可以包含 user:pass:
1 | ceph config set mgr mgr/telemetry/proxy https://ceph:telemetry@10.0.0.1:8080 |
agent
mgr/telemetry/last_opt_revision :
mgr/cephadm/agent_down_multiplier :通过与代理刷新率相乘,来计算代理在被标记为不可用之前必须多久没有上报
volumes
mgr/volumes/max_concurrent_clones :异步克隆程序线程数
mgr/volumes/snapshot_clone_delay :将克隆开始操作延迟 snapshot_clone_delay 秒
cephadm
mgr/cephadm/agent_down_multiplier :与代理刷新率(agent_refresh_rate)相乘,计算代理在被标记之前不得报告的时间
mgr/cephadm/agent_refresh_rate :每个主机上的代理尝试收集和发送元数据的频率
mgr/cephadm/agent_starting_port :代理将尝试绑定到的第一个端口(如果被阻止,还将尝试下一个 1000 个后续端口)
mgr/cephadm/allow_ptrace :允许在 Ceph 容器上启用SYS_PTRACE功能
- 需要SYS_PTRACE功能才能附加到具有 gdb 或 strace 的进程。启用此选项可以允许调试在运行时遇到问题的守护程序。
mgr/cephadm/cgroups_split :当 cephadm 创建容器时传递 —cgroups=split(目前仅限 podman)
mgr/cephadm/config_checks_enabled :启用或禁用 cephadm 配置分析
mgr/cephadm/default_cephadm_command_timeout :应用于 cephadm 命令的默认超时直接在主机上运行(以秒为单位)
mgr/cephadm/device_cache_timeout :缓存设备清单的秒数
mgr/cephadm/device_enhanced_scan :在设备扫描期间使用 libstoragemgmt
mgr/cephadm/facts_cache_timeout :缓存主机事实数据的秒数
mgr/cephadm/host_check_interval :执行主机检查的频率
mgr/cephadm/inventory_list_all :ceph-volume 清单是否应该报告更多设备(主要是映射器(LV、mpaths)、分区……
mgr/cephadm/log_refresh_metadata :记录所有刷新元数据。包括定期收集的守护程序、设备和主机信息。仅当日志记录在调试级别时才有效
mgr/cephadm/log_to_cluster :
mgr/cephadm/manage_etc_ceph_ceph_conf :在主机上管理和拥有 /etc/ceph/ceph.conf。
mgr/cephadm/manage_etc_ceph_ceph_conf_hosts :PlacementSpec 描述要在哪些主机上管理 etccephceph.conf
mgr/cephadm/max_count_per_host :每个主机的每个服务的最大守护程序数
mgr/cephadm/max_osd_draining_count :移除 OSD 时将同时排空的最大 OSD 数量
mgr/cephadm/mode :远程执行 CEPHADM 的模式
mgr/cephadm/registry_insecure :注册表将被视为不安全(没有可用的 TLS)。仅用于开发目的
mgr/cephadm/use_agent :在每个主机上使用 cephadm 代理来收集和发送元数据
mgr/cephadm/use_repo_digest :自动将镜像标签转换为镜像摘要。确保所有守护进程都使用相同的镜像
mgr/cephadm/warn_on_failed_host_check :如果主机检查失败,则引发运行状况警告
mgr/cephadm/warn_on_stray_daemons :如果检测到不受 CEPHADM 管理的守护程序,则会引发运行状况警告
mgr/cephadm/warn_on_stray_hosts :如果在不受 CEPHADM 管理的主机上检测到守护程序,则会引发运行状况警告
dashboard
mgr/dashboard/FEATURE_TOGGLE_CEPHFS :控制是否启用 Ceph 文件系统(CephFS)特性的一个功能切换或配置选项
mgr/dashboard/standby_behaviour 与性能无关
If the dashboard is behind a load-balancing proxy like HAProxy you might want to disable redirection to prevent situations in which internal (unresolvable) URLs are published to the frontend client. Use the following command to get the dashboard to respond with an HTTP error (500 by default) instead of redirecting to the active dashboard:
ceph config set mgr mgr/dashboard/standby_behaviour "error"
To reset the setting to default redirection, use the following command:
ceph config set mgr mgr/dashboard/standby_behaviour "redirect"
- 如果您的前端负载均衡器(如HAProxy, 更接近用户)后面有多个Ceph Dashboard副本,您可能希望禁用重定向功能,以避免将内部(不可解析的)URL发布给前端客户端。使用以下命令可以让备用副本的Dashboard返回HTTP错误(默认为500),而不是重定向到活动副本:
iostat
完成
nfs
完成
prometheus
提供 Prometheus exporter 以从 ceph-mgr 中的收集点传递 Ceph 性能计数器。
Ceph-mgr 从所有 MgrClient 进程(例如 mons 和 OSD)接收 MMgrReport messages,其中包含性能计数器架构数据和实际计数器数据,并保留最后 N 个样本的循环缓冲区。该模块创建一个 HTTP 端点(与所有 Prometheus 导出器一样),并在轮询时抓取每个计数器的最新样本(或在 Prometheus 术语中“scraped ”)。
HTTP 路径和查询参数被忽略;所有报告实体的所有现有计数器均以文本说明格式返回。
启动
1 | ceph mgr module enable prometheus |
配置
需要重启 才能应用prometheus manager 模块的参数配置修改
mgr/prometheus/address :模块侦听 HTTP 请求的 IPv4 或 IPv6 地址
server_port :模块侦听 HTTP 请求的端口
mgr/prometheus/cache
restful
RESTful 模块通过 SSL 安全连接提供对集群状态的 REST API 访问
启用
1 | ceph mgr module enable restful |
在 API 端点可用之前,您还需要在下面配置 SSL 证书。默认情况下,模块将接受主机上所有 IPv4 和 IPv6 地址上端口 8003 上的 HTTPS 请求。
安全
所有与 Restful 的连接均通过 SSL 进行保护。您可以使用以下命令生成自签名证书:
1 | ceph restful create-self-signed-cert |
请注意,使用自签名证书,大多数客户端将需要一个标志来允许连接和/或抑制警告消息。例如,如果 ceph-mgr 守护进程位于同一主机上:
1 | curl -k https://localhost:8003/ |
为了正确保护部署,应使用由组织的证书颁发机构签名的证书。例如,可以使用类似于以下的命令生成密钥对:
1 | openssl req -new -nodes -x509 \ |
然后,restful.crt 应由您组织的 CA(证书颁发机构)签名。完成后,您可以使用以下命令进行设置:
1 | ceph config-key set mgr/restful/$name/crt -i restful.crt |
其中 $name 是 ceph-mgr 实例的名称(通常是主机名)。如果所有管理器实例要共享相同的证书,您可以省略 $name 部分:
1 | ceph config-key set mgr/restful/crt -i restful.crt |
配置IP和端口
与任何其他 RESTful API 端点一样,Restful 绑定到 IP 和端口。默认情况下,当前活动的 ceph-mgr 守护进程将绑定到端口 8003 以及主机上任何可用的 IPv4 或 IPv6 地址。
由于每个 ceph-mgr 托管自己的 Restful 实例,因此可能还需要单独配置它们。 IP 和端口可以通过配置密钥工具进行更改:
1 | ceph config set mgr mgr/restful/$name/server_addr $IP |
其中 $name 是 ceph-mgr 守护进程的 ID(通常是主机名)。
这些设置也可以在集群范围内配置,而不是特定于管理器。例如,:
1 | ceph config set mgr mgr/restful/server_addr $IP |
如果未配置端口,restful将绑定到端口8003。如果未配置地址,restful将绑定到::,它对应于所有可用的IPv4和IPv6地址。
创建 API 用户
要创建 API 用户,请运行以下命令:
1 | ceph restful create-key <username> |
将 <用户名> 替换为所需的用户名。例如,创建一个名为 api 的用户:
1 | ceph restful create-key api |
从 ceph restful create-key api 生成的 UUID 充当用户的密钥。
要列出您的所有 API 密钥,请运行以下命令:
1 | ceph restful list-keys |
可以使用curl 来使用API 测试您的用户。这是一个例子:
1 | curl -k https://api:52dffd92-a103-4a10-bfce-5b60f48f764e@<ceph-mgr>:<port>/server |
在上面的例子中,我们使用 GET 从服务器端点获取信息。
负载均衡器
请注意,restful 只会在当时处于活动状态的 manager 上启动。查询 Ceph 集群状态以查看哪个 manager 处于活动状态(例如 ceph mgr dump)。
为了使 API 通过一致的 URL 可用,无论哪个 manager 守护进程当前处于活动状态,您可能需要设置一个负载均衡器前端,以将流量定向到任何可用的管理器端点。
支持的访问方式
您可以 navigate to /doc 端点以获取可用端点以及为每个端点实现的 HTTP 方法的完整列表。
例如,如果要使用 /osd/
1 | echo -En '{"up": true}' | curl --request PATCH --data @- --silent --insecure --user <user> 'https://<ceph-mgr>:<port>/osd/1' |
或者你可以使用 python 来执行此操作:
1 | python |
Restful 模块中实现的一些其他端点包括
/config/cluster: GET/config/osd: GET, PATCH/crush/rule: GET/mon: GET/osd: GET/pool: GET, POST/pool/<arg>: DELETE, GET, PATCH/request: DELETE, GET, POST/request/<arg>: DELETE, GET/server: GET
disabled module
localpool
localpool 模块为集群 CRUSH map 的某个子树创建池(故障域级的池)。如,默认情况为集群中的不同 rack 创建一个池
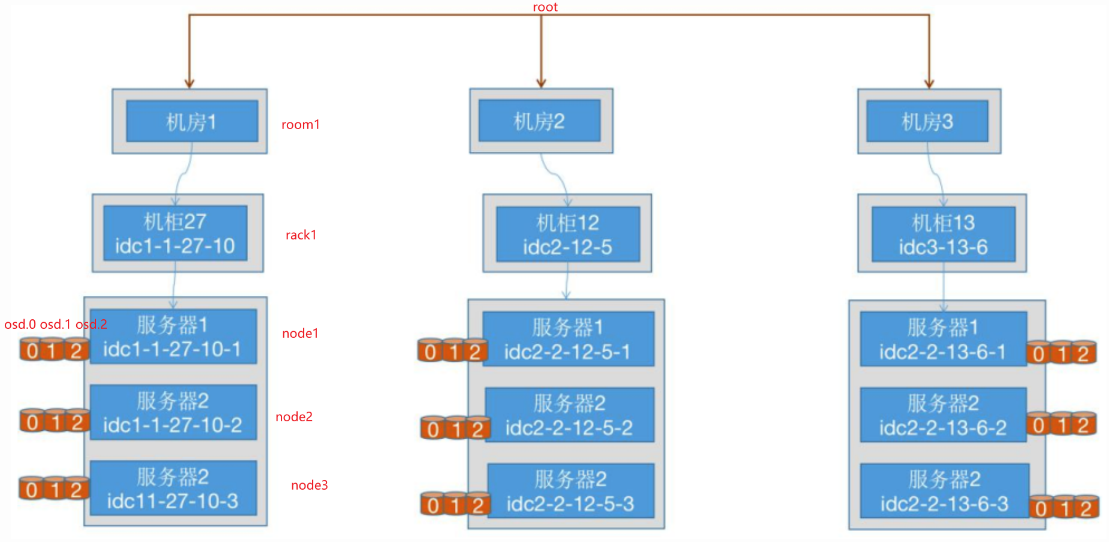
localpool 的使用通常与Ceph的本地存储功能(如 BlueStore)相关,它允许将存储池配置为使用特定节点的本地磁盘,而不是分布在整个集群中的磁盘。可以在需要优化性能或管理不同类型的数据时使用。
一般情况,管理员不使用 localpool 模块自动创建池,且仅与池的创建有关,并不影响集群性能,故裁剪