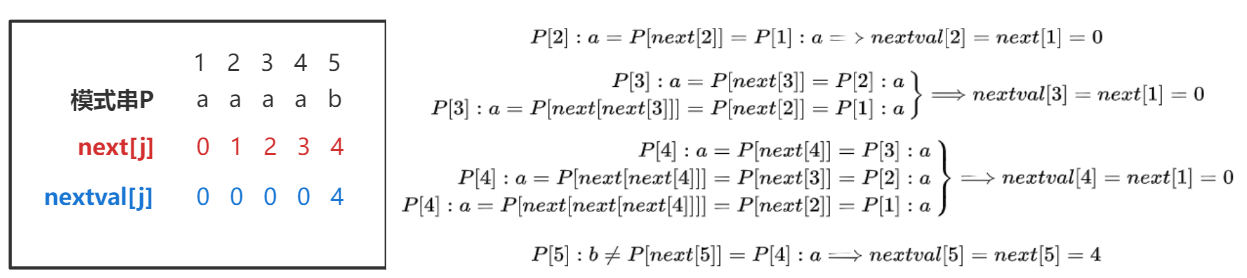线性表是一种逻辑结构
本文总结的应用部分代码来源于王道数据结构相应部分课后题
2.1 基本概念 线性表 :具有相同数据类型的 n ($n\ge0$)个数据元素的有限序列
$n=0$ 为 空表
表示为:
L = ($a_1,a_2…,a_i,a_{i+1},…,a_n$)
(1)存在唯一一个被称为 “第一个” 的数据元素—— $a_1$:表头元素
(2)存在唯一一个被称为 “最后一个” 的数据元素—— $a_n$:表尾元素
(3)除第一个之外,集合中的每个数据元素只有一个 直接前驱
(4)除最后一个外,集合中每个数据元素只有一个 直接后继
2.1.1 特点 数据元素个数有限
元素间有逻辑上的顺序性
表中元素都是 数据元素
元素具有抽象性:只讨论元素间的逻辑关系,不考虑具体表示什么
表中元素 数据类型相同
单个元素占用的存储空间相同
当数据元素由若干数据项组成:
2.1.2 线性表是一种逻辑结构 表示元素之间一对一的相邻关系
实现线性表的两种存储结构
线性表基本操作的实现
2.1.3 基本操作 InitList(&L);初始化线性表 Length(L);获取线性表中元素个数 LocateElem(L,e);获取元素e在线性表中的位置 GetElem(L,i);获取第i个元素 ListInsert(&L,i,e);将e插入到第i个位置 PrintList(L);输出线性表中元素 DetoryList(&L);销毁线性表
2.2 线性表的存储 2.2.1 线性表的顺序存储——顺序表 位序与下标的区别
位序:$1\le i \le length$ 下标:$0\le i \le length-1$ 动态分配
动态分配属于 顺序存储 结构,分配 $n$ 个空间时仍需要 $n$ 个连续存储空间 1. 特点 2. 结点定义 1 2 3 4 5 6 7 8 9 10 11 12 # define MaxSize 20 typedef struct { ElemType data[MaxSize]; int length; }SqList; # define INITSIZE 10 # define INCREMENT 10 typedef struct { ElemType *elem; int length; int listSize; }SqList;
3. 基本操作实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 Status ListInit_sq (SqList &L) { L.elem = (ElemType *)malloc (INITSIZE*sizeof (ElemType)); if (!L.elem) return OVERFLOW; L.length = 0 ; L.listSize = INITSIZE; return OK; } Status ListInsert_Sq (SqList &L, int i, ElemType x) { if (i < 1 || i > L.length + 1 ) return ERROR; if (L.length >= L.listSize){ ElemType* newbase = (ElemType *)realloc (L.elem,(L.listSize+INCREMENT)*sizeof (ElemType)); if (!newbase) exit (OVERFLOW); L.elem = newbase; L.listSize += INCREMENT; } ElemType* p = &(L[i-1 ]); for (ElemType* p = &(L[length-1 ]);p>=q;) *(p+1 ) = *p; *q = x; L.length++; return OK; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Status ListDelete_Sq (SqList &L, int i, ElemType &x) { if (i < 1 || i > L.length) return ERROR; ElemType* p = &(L[i-1 ]); x = L.data[i - 1 ]; while (p<&(L[L.length-1 ])){ *p = *(p+1 ); p++; } L.length--; return OK; }
插入 删除 按值查找 最好 表尾插入,不移动元素 $O(1)$ 表尾删除,不移动元素 $O(1)$ 遍历一次$O(1)$ 最坏 表头插入,移动 $n$ 个元素 $O(n)$ 表头删除,移动 $n-1$ 各元素 $O(n)$ 表尾,$O(n)$ 期望 $\sum_{i=1}^n{p_i(n-i+1)}$ $\sum_{i=1}^nq_i{(n-i)}$ 平均移动次数 $\frac{1}{n+1}\sum_{i=1}^n{(n-i+1)} = \frac{n}{2}$ $\frac{1}{n}\sum_{i=1}^n{(n-i)} = \frac{n-1}{2}$ 平均时间复杂度 $O(n)$ $O(n)$ $O(n)$ 空间复杂度 $O(1)$ $O(1)$
假设对每个元素访问的等概率,即期望中的概率为算数平均数
4. 顺序表应用 辨别 顺序表 和 有序表
顺序表 :线性表的顺序 存储结构 有序表:表中元素按某一关键字递增或递减排序的 线性表 插入 总是发生在 顺序表尾
顺序表的修改操作,一定会涉及遍历元素 两表合并 顺序表合并返回顺序表 思路 :短表的下标为结果表的下标
时间复杂度:$O(n)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 bool Merge (SqList A, SqList B, SqList &C) if (A.length + B.length > C.MaxSize + 1 ) return false ; int i = 0 , j = 0 , k = 0 ; while (i < A.length && j < B.length) { if (A.data[i] <= B.data[j]) C.data[k++] = A.data[i++]; else C.data[k++] = B.data[j++]; } while (i < A.length) C.data[k++] = A.data[i++]; while (j < B.length) C.data[k++] = B.data[j++]; C.length = k; return true ; }
快慢指针 有序顺序表去重 思路 :快慢指针,i 为慢指针,即结果表游标
时间复杂度:$O(n)$
空间复杂度:$O(1)$
1 2 3 4 5 6 7 8 9 10 bool DeleteDuplicate (SqList &L) if (L.length == 0 ) return false ; int i, j; for (i = 0 , j = 1 ; j < L.length; ++j) if (L.data[j] != L.data[i]) L.data[++i] = L.data[j]; L.length = i + 1 ; return true ; }
删除指定元素 思路 :k 为慢指针,即结果表游标;i 为快指针,即原表游标
时间复杂度:$O(n)$
1 2 3 4 5 6 7 8 9 10 11 12 void DelX1 (SqList &L,ElemType x) int k = 0 ; int i; for (i = 0 ; i < L.length; ++i) { if (L.data[i] != x) { L.data[k++] = L.data[i]; } } L.length = k; }
i :快指针
cnt_x :记录 x 的个数,将不为 x 的值插入到表尾;
i-k:慢指针
1 2 3 4 5 6 7 8 9 10 11 12 void DelX2 (SqList &L, ElemType x) int cnt_x = 0 ; int i = 0 ; while (i < L.length) { if (L.data[i] == x) cnt_x++; else L.data[i-cnt_x] = L.data[i]; i++; } L.length = L.length - cnt_x; }
删除有序表指定范围元素 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 bool del_s_t (SqList &L,ElemType s,ElemType t) { int i,j; if (s > t || L.length == 0 ) return false ; for (i=0 ;i < L.length && L.data[i] < s;i++); if (i >= L.length) return false ; for (j=i;j < L.length && L.data[j] <=t;j++); if (j >= L.length) return false ; while (j < L.length) L.data[i++] = L.data[j++]; L.length = i; }
删除无序表指定范围元素 i :快指针
cnt_x:记录范围内值的个数,将范围外的值插入表尾
i-cnt_x:慢指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 bool del_s_t (SqList &L,ElemTtpe s,ElemType t) { int i; int cnt_x = 0 ; if (L.length == 0 || s >= t) return false ; for (i = 0 ;i < L.length;++i){ if (L.data[i] >= s && L.data <= t) cnt_x++; else L.data[i-cnt_x] = L.data[i]; } L.length = cnt_x; return true ; }
无序表去重 排序:$O(nlogn)$ 遍历:$O(n)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 int Partition (ElemType a[],int low,int high) { ElemType pivot = a[low]; while (low < high){ while (low < high && a[high] > pivot) --high; a[low] = a[high]; while (low < high && a[low] < pivot) ++low; } a[low] = pivot; return low; } void QuickSort (ElemType a[],int low,int high) { if (low < high){ int pivotpos = Partition(a,low,high); QucikSort(a,low,pivotpos-1 ); QucikSort(a,pivotpos+1 ,high); } } bool Union (SqList &L) { QuickSort(L.data,0 ,L.length-1 ); for (int i = 1 ,j = 0 ;i < L.length;++i){ if (L.data[i] != L.data[j]) L.data[++j] = L.data[i]; } }
遍历 删除最小值 思路 :一次遍历,记录变量
时间复杂度:$O(n^2)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 bool DelMin (SqList &L ,ElemType &e) { if (L.length == 0 ) return false ; e = L.data[0 ]; int pos = 0 ; for (int i = 0 ; i < L.length; ++i) { if (L.data[i] < e) { e = L.data[i]; pos = i; } } L.data[pos] = L.data[L.length - 1 ]; L.length--; return true ; }
无序顺序表去重 思路 :sum 记录表长。逐个遍历,查找结果表中是否存在
时间复杂度:$O(n^2)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 bool Union (SqList &L) if (L.length == 0 ) return false ; int i, j, sum = 1 ; while (j < L.length) { for (i = 0 ; i < sum; ++i) { if (L.data[i] == L.data[j]) break ; } if (i == sum) L.data[sum++] = L.data[j++]; else j++; } L.length = sum; return true ; }
折半查找 折半查找 要求 :有序线性表,查找 x
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void BinarySearch (SqList L, ElemType x) int low, high = L.length - 1 ,mid; while (low <= high) { mid = (low + high) / 2 ; if (L.data[mid] == x) break ; else if (L.data[mid] < x) low = mid + 1 ; else high = mid - 1 ; } if (L.data[mid] == x && mid != L.length - 1 ) { ElemType t = L.data[mid]; L.data[mid] = L.data[mid + 1 ]; L.data[mid + 1 ] = t; } if (low > high) { int i; for (i = n - 1 ; i > high; i--) L.data[i + 1 ] = L.data[i]; L.data[i + 1 ] = x; } }
###### 原地转置——[折半] > 时间复杂度:$O(n)$ 空间复杂度:$O(1)$
1 2 3 4 5 6 7 8 void Reverse (SqList &L) ElemType e; for (int i = 0 ; i < L.length / 2 ; ++i) { e = L.data[i]; L.data[i] = L.data[L.length - 1 - i]; L.data[L.length - 1 - i] = e; } }
**转置应用** > *要求* :`L.data[m+n]` 中存放的元素,将 `L.data` 转置,然后前m个转置,后n个转置 > > $a_1,a_2,a_3...a_n,b_1,b_2...b_m$ ---> $b_m,b_{m-1}...b_1,a_n,a_{n-1}...a_1$ > > ---> $b_1,b_2...b_m,a_1,a_2,a_3...a_n$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 bool ReverseApply (SqList &L, int left, int right) if (left >= right || right >= L.length) return false ; int mid = (left + right) / 2 ; for (int i = 0 ; i <= mid - left; ++i) { ElemType e = L.data[left + i]; L.data[left + i] = L.data[right - i]; L.data[right - i] = e; } } bool Exchange (SqList &L, int m, int n) ReverseApply (L, 0 , m - n + 1 ); ReverseApply (L, 0 , n - 1 ); ReverseApply (L, n, m + n - 1 ); }
2.2.2 线性表的链式存储 用一组未必连续的存储单元保存线性表的数据元素
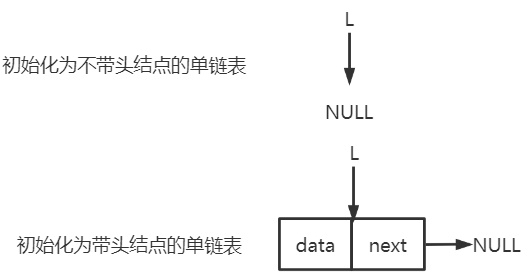
结点:包含数据域和指针域 头指针:指向头结点的位置 头结点:链表的第一个节点之前附设一个结点,称为头结点。 引入头结点原因:
1. 特点 不要求连续存储空间,逻辑上相邻的元素通过 指针 标识 链表同样可反映数据间的逻辑关系 不支持随机存取 2. 单链表 结点定义 1 2 3 4 typedef struct { ElemType data; struct LNode *next; }LNode,*LinkList;
基本操作 单链表的创建 带不带头结点在代码实现中,区别在于对第一个结点的特殊处理
必须将第一个头结点 next 设为 NULL,因为一直向后传递,且没有尾指针
每个结点插入时间为 $O(1)$ ,插入n个结点时间为 $O(n)$
最后一个结点的 next 域为NULL
1. 头插法 多用于原地逆置
带头结点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void HeadInsert (LinkList &L,int n) if (n < 0 ) return ERROR; L = (LinkList)malloc (sizeof (LNode)); if (!L) exit (OVERFLOW); L->next = NULL ; L.length = 0 ; while (L.length < n){ LNode *p = (LNode *)malloc (sizeof (LNode)); if (!p) exit (OVERFLOW); scanf_s ("%d" , &p->data); p->next = L->next; L->next = p; L.length++; } }
不带头结点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 LinkList HeadInsert2 (LinkList &L,int n) { if (n < 0 ) return ERROR; LNode *p; L.length = 0 ; while (L.length < n){ p = (LNode *)malloc (sizeof (LNode)); if (!p) exit (OVERFLOW); scanf ("%d" , &p->data); p->next = i==0 ? NULL : L-next; L = p; L.length++; } return L; }
2. 尾插法
带头结点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 LinkList TailInsert (LinkList &L,int n) { L = (LinkList)malloc (sizeof (LNode)); if (!L) exit (OVERFLOW); LNode *r = NULL ,*p = NULL ; L.length = 0 ; while (L.length < n) { p = (LNode *)malloc (sizeof (LNode)); if (!p) exit (-1 ); scanf ("%d" ,&p->data); p->next = NULL ; r->next = p; r = p; } return L; }
不带头结点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 LinkList TailInsert (LinkList &L,int n) { LNode *r = NULL ,*p = NULL ; L.length = 0 ; while (L.length < n) { p = (LNode *)malloc (sizeof (LNode)); if (!p) exit (OVERFLOW); scanf ("%d" ,&p->data); p->next = NULL ; if (!r){ L = p; }else { r->next = p; } r = p; } return L; }
查找 1. 按序号查找
当第 i 个元素存在是,将钙元素的值赋给 e 并返回 OK,否则返回 ERROR
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Status GetElem_L (LinkList &L,int i,ElemType &e) { LNode *p = L->next; int k = 1 ; while (p && k < i){ p = p->next; k++; } if (!p || k > i) return ERROR; e = p->data; return OK; }
2. 按值查找
1 2 3 4 5 6 7 8 LNode *LocateElem (LinkList L, ElemType e) { LNode *p = L->next; while (p != NULL && p->data != e) p = p->next; return p; }
插入 对第 i 个结点前插 $\iff$ 对第 i-1 个结点后插
1. 插入到第 i 个位置
只知道插入位序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Status ListInsert_L (LinkList &L,int i, ElemType e) { LNode *p = L->next; k = 0 ; while (p && k < i-1 ){ p = p->next; k++; } if (!p || k > i-1 ) return ERROR; LNode *s = (LNode *)malloc (sizeof (LNode)); if (!s) return OVERFLOW; s->data = e; s->next = p->next; return OK; }
2. 后插&交换
当已知插入结点p时
1 2 3 4 5 6 7 8 9 10 11 12 bool InsBefore2 (LinkList &L, LNode *p, LNode *s) s->next = p->next; p->next = s; ElemType tmp = s->data; s->data = p->data; p->data = tmp; return true ; }
删除 1. 已知索引删除
从链表头开始顺序查找到 p 的前驱结点,执行删除操作
时间复杂度为 $O(n)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Status LinkListDelete_L (LinkList &L, int i, ElemType &e) { if (i < 1 || i > Length (L)) return ERROR; int j = 0 ; LNode *s, *p = L; while (p && j < i - 1 ) { p = p->next; j++; } if (p && p->next) { s = p->next; p->next = s->next; e = s->data; free (s); return OK; } }
2. 已知结点删除
删除结点 p 的后继结点实现
1 2 3 4 5 6 7 8 9 10 bool Del2 (LinkList &L, LNode *p) LNode *q = p->next; p->data = p->next->data; p->next = q->next; free (q); return true ; }
求长度 对不带头结点的单链表,表为空时,要单独处理
不带头结点
1 2 3 4 5 6 7 8 9 10 11 12 13 int Length2 (LinkList L) if (L == NULL ) { return 0 ; } int n = 0 ; LNode *p = L; while (p) { n++; p = p->next; } return n; }
带头结点
1 2 3 4 5 6 7 8 9 int Length (LinkList L) { int n = 0 ; LNode *p = L->next; while (p) { n++; p = p->next; } return n; }
公共序列 找公共 结点 两个链表有公共结点,即从第一个公共结点开始,它们的 next 域都指向同一个结点。从第一个公共结点开始,之后它们的所有结点都是重合的,不可能出现分叉。即只能是 $Y$,不可能是 $X$。
1. 暴力
空间复杂度:$O(len1*len2)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 LNode *Search (LinkList L1,LinkList2) { LNode *pa = L1->next,*pb = L2->next; while (pa != NULL ){ pb = L2->next; while (pb != NULL ){ if (pa->data == pb->data) break ; pb = pb->next; } if (pb == NULL ) pa = pa->next; } return pa; }
2. 最优
由于从公共结点开始到最后一个结点是相同的,所以从最后一个结点回溯,可以找到第一个公共结点。若截取长链表多出来部分,并不影响公共部分。
时间复杂度:$O(len1+len2)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 LNode *Search (LinkList L1,LinkList L2) { LinkList longList,shortList; int dist; if (L1.length > L2.length){ longList = L1.length; shortList = L2.length; dist = L1.length-L2.length; }else { shortList = L1.length; longList = L2.length; dist = L2.length-L1.length; } while (dis--) longList = longList->next; while (!longList){ if (longList == shortList) return longList; else { longList = longList->next; shortList = shortList->next; } } return NULL ; }
找公共 序列 实质上是模式匹配,A为主串,B为模式串
1. 暴力法
时间复杂度:$O(len1*len2)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int pattern (LinkList A,LinkList B) { LNode *p = A->next,*q = B->next; LNode *pre = p; while (p && q){ if (p->data==q->data){ p = p->next; q = q->next; }else { pre = pre->next; p = pre; q = B->next; } } if (q == NULL ) return 1 ; return 0 ; }
2. KMP算法
合并 实质是链表的遍历
归并 两个递增链表,合并为一个递减链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 void Merge (LinkList &La,LinkList &Lb) { LNode *pa = La->next,*pb = Lb->next; LNode *q; La->next = NULL ; while (pa && pb){ if (pa->data <= pb->data){ q = pa->next; pa->next = La->next; La->next = pa; pa = q; }else { q = Lb->next; pb->next = La->next; La->next = pb; pb = q; } free (q); } if (pa) pb = pa; while (pb){ q = pb->next; pb->next = La->next; La->next = pb; pb = q; free (q); } free (Lb); }
求两链表交集 只有同时出现在两链表中的元素才链接到新表
将 L1 作为新表,L2 释放
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 LinkList Union (LinkList L1,LinkList L2) { LNode *pa = L1->next,*pb = L2->next; LNode *r; LinkList pc = (LinkList)malloc (sizeof (LNode)); pc = pa; while (pa && pb){ if (pa->data == pb->data){ pc->next = pa; pc = pa; pa = pa->next; r = pb; pb = pb->next; free (r); }else if (pa->data < pb->data){ r = pa; pa = pa->next; free (r); }else (pa->data > pb->data){ r = pb; pb = pb->next; free (r); } } while (pa){ r = pa; pa = pa->next; free (r); } while (pb){ r = pb; pb = pb->next; free (r); } pc->next = NULL ; free (L2); return L1; }
有序表找公共元素 要求不破坏原链表
值不等,则将值小的指针后移;值相等,创建一个新结点,尾插法到新表尾。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 LinkList getCommon (LinkList L1,LinkList2) { LNode *pa = L1->next,*pb = L2->next; LinkList L3 = (LinkList)malloc (sizeof (LNode)); if (!L3) exit (OVERFLOW); LNode *r = L3; while (pa != NULL && pb != NULL ){ if (pa->data < pb->data) pa = pa->next; else if (pb->data < pa->data) pb = pb->next; else { LNode *s = (LNode *)malloc (sizeof (LNode)); s->data = p->data; r-next = s; r = s; pa = pa->next; pb = pb->next; } } r->next = NULL ; }
相关思路 头插法 1. 逆序输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void RPrint (LinkList L) { LinkList A = (LinkList)malloc (sizeof (LNode)); A->next = NULL ; LNode *p = L->next; while (!p){ LNode *q = (LNode *)malloc (sizeof (LNode)); q->data = p->data; q->next = A->next; A->next = q; p = p->next; } p = A->next; while (!p) print(p->data); }
2. 就地逆置
1 2 3 4 5 6 7 8 9 10 11 void Reverse (LinkList &L) { LNode *p,*q; p = L->next; L->next = NULL ; while (!p){ q = p->next; p->next = L->next; L->next = p; } }
尾插法 1. 删除指定值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void DelX (LinkList &L,ElemType e) { LNode *p = L->next; LNode *r = L; LNode *q; while (!p){ if (p->data!=e){ r->next = p; r = p; p = p->next; }else { q = p; p = p->next; free (p); } } r->next = NULL ; }
2. 删除最小值
遍历:一趟简单选择排序
时间复杂度:$O(n)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void DelMin (LinkList &L) { LNode *pre = L,*p = pre->next; LNode *minpre = pre,*minp = p; while (!p){ if (p->data < minp->data){ minp = p; minpre = pre; } pre = p; p = p->next; } minpre->next = minp->next; free (minp); }
3. 有序表去重
有序表,则前后结点数据不相等,则不重复
若为无序表,则遍历有序表后才可判断是否重复,时间复杂度为 $O(n^2)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void DelDuplicate (LinkList &L) { LNode *p = L->next,*ra = p; LNode *r; p = p->next; while (p != NULL ){ if (p->data != ra->data){ ra->next = p; ra = p; p = p->next; }else { r = p; p = p->next; free (r); } } }
快慢指针 去重
1. 删除指定值
p :快指针
pre:慢指针
时间复杂度:$O(n)$
空间复杂度:$O(1)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void DelX (LinkList &L,ElemType e) { LNode *q; LNode *p = L->next, *pre = L; while (!p){ if (p->data == e){ q = p; p = p->next; pre->next = p; free (q); }else { pre = p; p = p->next; } } }
2. 删除无序链表指定范围值
1 2 3 4 5 6 7 8 9 10 11 12 13 void RangeDel (LinkList &L,ElemType min,ElemType max) { LNode *pre = L,*p = pre->next; while (!p){ if (p->data > min && p->data < max){ pre->next = p->next; p = p->next; free (p); }else { pre = p; p = p->next; } } }
3. 有序表去重
时间复杂度:$O(n)$
空间复杂度:$O(1)$
1 2 3 4 5 6 7 8 9 10 11 12 13 void DelDulplicate (LinkList &L) { LNode *p = L->next,LNode *q; if (p == NULL ) return ; while (p->next != NULL ){ q = p->next; if (p->data == q->data){ p->next = q->next; free (q); }else p = p->next; } }
快慢指针实现指针反转 1. 就地逆置
pre:指向慢指针指向的前一个结点
q:慢指针,初始指向头结点
p:快指针,初始指向头结点的下一个结点
1 2 3 4 5 6 7 8 9 10 11 12 void Reverse (LinkList &L) { LNode *pre, *q = L->next,*p = q->next; q->next = NULL ; while (!p){ pre = q; q = p; p = p->next; q->next = pre; } }
1. 排序
基于 直接插入排序 思想,此时前后指针是为了不断链
时间复杂度:$O(n^2)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void sort (LinkList &L) { LNode *p = L->next,*pre; LNode *r = p->next; p->next = NULL ; p = r; while (!p){ r = p->next; pre = L; while (pre->next != NULL && pre->data < p->data) pre = pre->next; p->next = pre->next; pre->next = p; p = r; } }
2. 递增输出
简单选择排序思想,若不影响原链表,则需要进行复制:$O(n^2)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void AscPrint (LinkList L) { LNode *r; while (L->next){ LNode *pre = L; LNode *p = pre->next; while (p){ if (p->next->data < pre->next-data) pre = p; p = p->next; } print(p->next-data); r = pre->next; pre->next = r->next; free (r); } free (L); }
3. 拆分
指针赋值,会使他们指向同一个存储单元。对两个指针的操作会修改同一个结点的属性
奇数位结点元素 A 尾,偶数位结点元素 B 尾 ,结果表中元素相对位置不变
时间复杂度:$O(n)$ 空间复杂度:$O(1)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 LinkList DisCreate (LinkList &A) { int cnt = 0 ; B = (LinkList)malloc (sizeof (LNode)); if (!B) exit (OVERFLOW); LNode *ra = A,*rb = B; LNode *p = ra; A->next = NULL ; while (p){ cnt++; if (cnt%2 ==0 ){ rb->next = p; rb = p; }else { ra->next = p; ra = p; } p = p->next; } ra->next = NULL ; rb->next = NULL ; return B; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 LinkList DisCreate (LinkList &A) { B = (LinkList)malloc (sizeof (LNode)); if (!B) exit (OVERFLOW); LNode *p = A; A->next = NULL ; B->next = NULL ; LNode *ra = A,*rb = B; while (p){ ra->next = p; ra = p; p = p->next; if (p != NULL ){ rb->next = p; rb = p; p = p->next; } } ra->next = NULL ; rb->next = NULL ; return B; }
奇数位结点元素入 A 尾,偶数位结点元素入 B 头
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 LinkList DisCreate (LinkList &A) { LinkList B = (LinkList)malloc (sizeof (LNode)); B->next = NULL ; LNode *p = A->next,q; LNode *ra = A; while (p != NULL ){ ra->next = p; ra = p; p = p->next; if (p != NULL ) q = p->next; p->next = B->next; B->next = p; p = q; } ra->next = NULL ; return B; }
空间换时间 1. 逆序输出
时间复杂度:$O(n)$
空间复杂度:$O(n)$
1 2 3 4 5 6 7 8 9 10 11 12 void RPrint (LinkList L) { Stack s; LNode * p = L->next; while (!p) Push(s,p->data); while (!EmptyStack(s)){ ElemType e; Pop(s,e); print(e); } }
2. 链表排序
将链表数据复制到数组中,采用 $O(nlonn)$ 的排序算法排序,然后将数组元素插入到链表中
时间复杂度:$O(n)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 void sort (LinkList &L) { LNode *p = L->next; ElemType a[MaxSize]; int i = 0 ; while (!p){ a[i++] = p->data; p = p->next; } QuickSort(a,0 ,L.length-1 ); p = L->next; for (i = 0 ;i < L.length;++i){ p->data = a[i]; p = p->next; } } int Partition (ElemType a[],int low,int high) { ElemType pivot = a[low]; while (low < high){ while (low < high && a[high] > pivot) --high; a[low] = a[high]; while (low < high && a[low] < pivot) ++low; } a[low] = pivot; return low; } void QuickSort (ElemType a[],int low,int high) { if (low < high){ int pivotpos = Partition(a,low,high); QucikSort(a,low,pivotpos-1 ); QucikSort(a,pivotpos+1 ,high); } }
3. 递增输出
将链表中数据复制到数组中,排序后输出
递归 递归 = 出口 + 调用 为保证一致性:递归从第一个有数据的结点开始 1. 删除指定值
时间复杂度:$O(n)$
递归栈深度:$O(n)$
1 2 3 4 5 6 7 8 9 10 11 12 13 void DelX (LinkList &L,ElemType e) { LNode *p = NULL ; if (L==NULL ) return ; if (L->data == e){ p = L; L = L->next; free (p); DelX(L,x); }else DelX(L->next,x); }
2. 逆序输出
1 2 3 4 5 6 7 8 9 10 11 12 void RPrint (LinkList L) { if (!L->next) RPrint(L->next); if (!L) print(L-data); } void IgnoreHead (LinkList) { if (!L) RPrint(L->next); }
3. 双链表 优化:访问前驱结点 —— $O(1)$ 单链表 —> $O(n)$ 结点定义 1 2 3 4 typedef struct DulNode { ElemType data; struct DulNode *prior,*next; }DulNode,*DulLinkList;
基本操作 插入
1 2 3 4 5 s->next = p->next; p->next->prior = s; s->prior = p; p->next = s;
删除
1 2 3 4 p->next = q->next; q->next->prior = p; free (q);
最近最高频访问 双向链表中查找到值为 x 的结点,查找到后,将结点从链表摘下,然后顺着结点的前驱找到该结点的插入位置(频度递减,且排在同频度的第一个。即向前找到第一个比他大的结点,插在该结点位置之后)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 DLinkList Locate (DLinkList &L,ElemType e) { DNode *p = L->next,*pre; while (p && p->data != x) p = p->next; if (!p){ return NULL ; }else { p->freq++; if (p->next != NULL ) p->next->pred = p->pred; p->pred->next = p->next; pre = p->pred; while (pre != L && pre->freq <= p->freq) pre = pre->pred; p->next = pre->next; pre->next->pred = p; p->pred = pre; pre->next = p; } return p; }
4. 循环链表 优化:对表尾操作—— $O(1)$单链表为 $O(n)$单链表删除最后一个元素 需要将最后一个元素空指 —— $O(n)$ 循环单链表 表尾 r->next 指向头指针(判空条件) 插入删除操作 应用
若操作多为在表头和表尾 插入 时,设尾指针
Note
若对 表尾删除 操作,单链表寻找其前驱结点为 $O(n)$
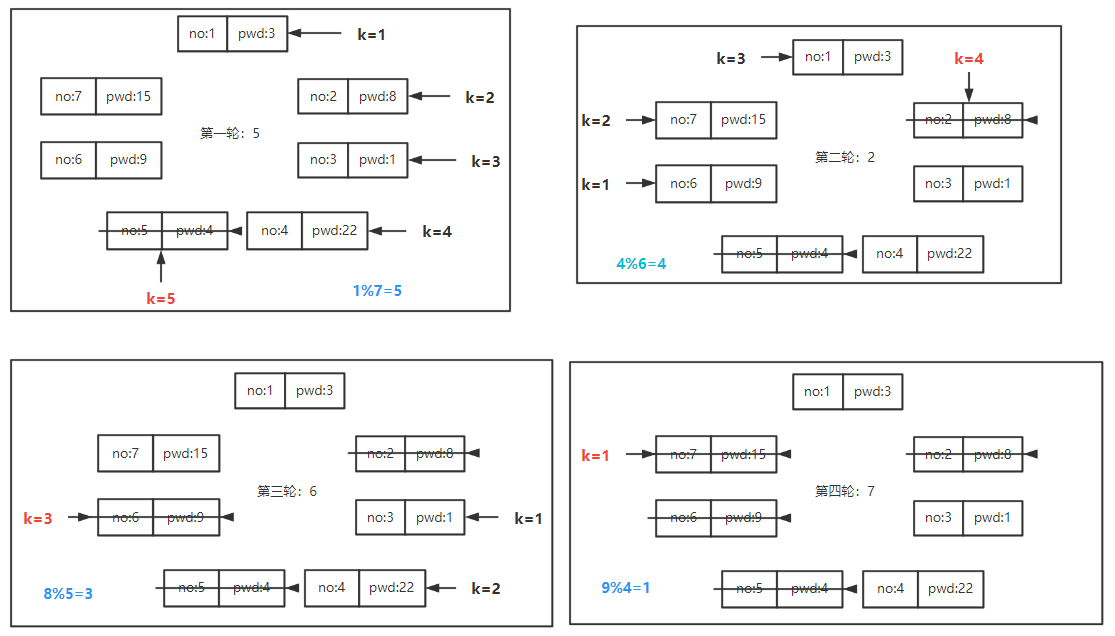
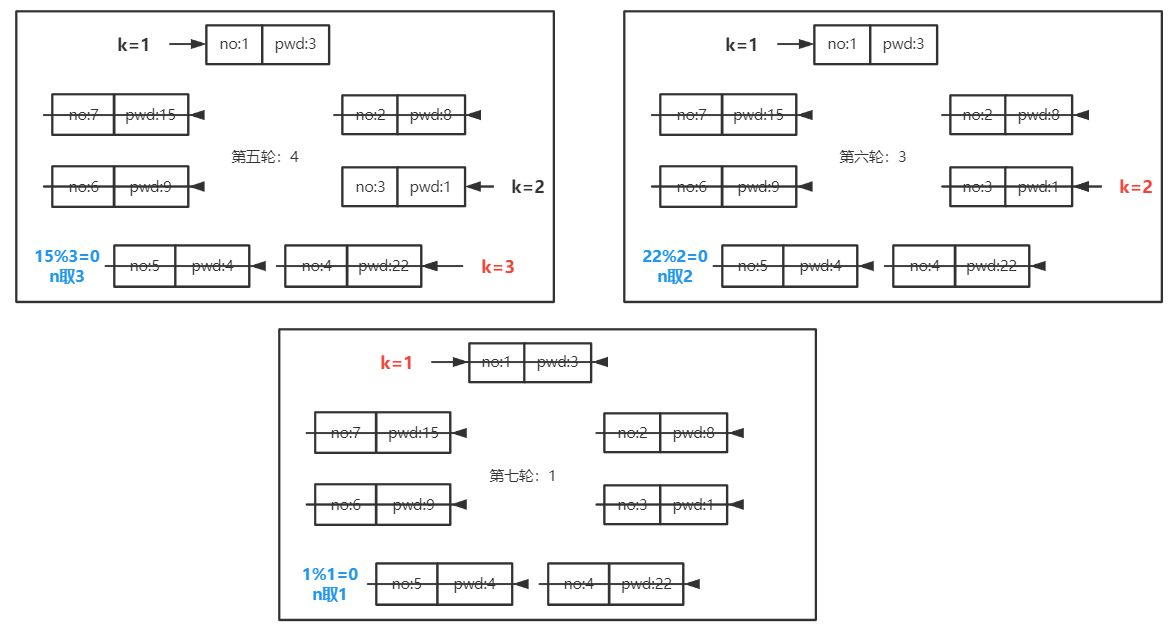
约瑟夫问题 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 typedef struct LNode { int no; unsigned int pwd; struct LNode *next ; }LNode,*LinkList; LinkList CreateLinkList (int n) ; void playing (LinkList tail,int n,int m) ;void main () { LinkList tail; int n,it; scanf ("%d%d" ,&n,&it); tail = CreateLinkList(n); if (tail) playing(tail,n,it); } LinkList CreateLinkList (int n) { LNode *p,*r; p = (LNode *)malloc (sizeof (LNode)); if (!p) exit (-1 ); scanf ("%d" ,&p->pwd); p->no = 1 ; p->next = p; r = p; for (int i = 2 ;i <= n;++i){ p = (LNode *)malloc (sizeof (LNode)); if (!p) exit (-1 ); scanf ("%d" ,&p->pwd); p->no = i; p->next = r->next; r->next = p; r = p; } return r; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 void playing (LinkList tail,int n,int m) { LNode *pre,*p; m = m%n ? m%n : n; pre = tail; p = pre->next; int k = 1 ; while (n > 1 ){ if (k==m){ printf ("%4d" ,p->no); pre->next = p->next; n--; m = p->pwd%n ? p->pwd%n : n; free (p); p = pre->next; k = 1 ; }else { k++; pre = p; p = p->next; } } printf ("%4d" ,p->no); }
将两个循环单链表连接 1 2 3 4 5 6 7 8 9 10 11 LinkList link (LinkList &L1,LinkList &L2) { LNode *p = L1,*q = L2; while (p->next != L1) p = p->next; while (q->next != L2) q = q->next; p->next = L2; q->next = L1; return L1; }
循环单链表选择排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void Del (LinkList &L) { LNode *p,*pre,*minp,*minpre; while (L->next != L){ p = L->next; pre = L; minp = p; minpre = pre; while (p!=L){ if (p->data < minp->data){ minp = p; minpre = pre; } pre = p; p = p->next; } print(minp->data); minpre-next = minp->next; free (minp); } free (L); }
循环双链表 空表条件: p->pre == p->next = L
便于进行各种修改操作,但占有较大指针域,存储密度不高
判断循环双链表是否对称 p 从左向右扫描, q 从右向左扫描;若相等, 则一直比较下去,直到指向同一结点(p == q) 或者相邻(p->next==q 或 q->prior ==p );否则,返回0。
1 2 3 4 5 6 7 8 9 10 11 12 int Symmetry (DLinkList L) { DNode *p = L->next,*q = L->prior; while (p != q && q->next != p){ if (p->data == q->data){ p = p->next; q = q->prior; }else return 0 ; } return 1 ; }
5. 静态链表 预先分配连续的内存空间
指针 $\iff$ 游标 next == -1 为表尾结点定义
1 2 3 4 5 # define MaxSize 50 typedef struct { ElemType data; int next; }SLinkList[MaxSize];
2.2.3 顺序表与链表比较 存取方式 逻辑&物理结构 查找 插&删 空间分配 顺序表 顺序存取 逻辑相邻 无序:O(n); O(n) 静态分配: 随机存取 按序号:O(1) 动态分配: 链表 顺序存取 逻辑关系通过指针表示 O(n) O(1) 按需分配,灵活高效
2.2.4 存储结构的选择 基于存储 基于运算 基于运算 顺序表 适用于有存储密度的要求 常用操作为按序号访问 不支持指针的语言;易于实现 链表 适用于难以估计存储规模 常用操作为插入删除 基于指针
Note:插入删除
链表按位序查找主要进行比较操作;顺序表主要操作是移动数据元素;
虽然时间复杂度同样为 $O(n)$ ,但显然比较操作相对优于移动操作
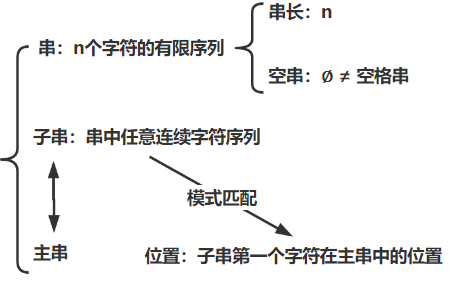
2.3 串 2.3.1 基本概念
1. 基本操作 StrAssign:串赋值 StrCompare:串比较 StrLength:串长度 Concat(&T,s1,s2):串连接 SubStr(subStr,T,pos,len) 从pos开始的长度为len的子串在T中的位置 2. 串&线性表 数据对象
操作对象
2.3.2 存储结构 1. 定长顺序存储 1 2 3 4 5 # define MaxStrLen 256 typedef char SqString{ char ch[MaxStrLen]; int length; }SqString;
2. 堆分配 1 2 3 4 typedef char SqString{ char *ch; int length; }SqString;
堆:自由存储区,用 malloc 和 free 完成动态管理 2.3.3 模式匹配 1. 暴力法
原理推导
主串游标 i 最大为 n-m+1
主串第 i 个失配,模式串第 j 个适配,则有 j-1 个已匹配,故模式串第一个元素在主串的第 i-(j-1) 处,故失配后下一轮主串游标从 i-j+2 开始
匹配成功标志 j==子串长+1
若末尾匹配成功,则 i>主串.len 且 j>子串.len
实现
时间复杂度:$O(m*n)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int Index (SqString S,SqString P) { int i = 1 ,j=1 ; while (i <= S.len && j <= P.len){ if (S.ch[i] == P.ch[i]){ i++; j++; }else { i = i-j+2 ; j = 1 ; } } if (j > P.len) return i-P.len; return -1 ; }
2. KMP 暴力法模式匹配可优化部分
失配原因是 $S[k+4]\neq P[4]$ ,但前缀
即可用 $P[1,2,3] \iff S[k+1,k+2,k+2]$ 。暴力法模式匹配效率低的原因是每次失配模式串游标都要回到起点。
若可以利用等价部分提前对模式串处理,使失配后,模式串游标无需回到起点,可减少比较次数。
为避免遗漏,要是失配后模式串开头移动距离最小,即 next[j] 最小
KMP过程
next[j] 怎样应用算法实现(1)若 P[j] == P[next[j]] ,则其 next[j+1] = next[j]+1
(2)若 P[j] $\neq$ P[next[j]],则将P再后移
例如
算法实现 时间复杂度:$O(n+m)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 int Index (SqString S,SqString P,int pos) { int i = pos; int j = 1 ; while (i <= S.len && j <= P.len){ if (j == 0 || S[i] == P[j]){ i++; j++; }else j = next[j]; } if (j > P.len) return i-P.len; } int get_next (SqSting P,int &next[]) { int i = 1 ; next[1 ] = 0 ; while (i <= P.len){ if (j == 0 || P[i] == P[j]){ i++; j++; next[i] = j; }else j = next[j]; } }
KMP优化
简单来说,nextval[j] = next[next[...]] ,使得 P[j] $\neq$ P[next[next[...]]]
故其 nextval[j] 数组如下图所示,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void get_nextval (String P,int &nextval[]) { int i = 2 ,j = 1 ; nextval[1 ] = 0 ; while (i <= P.length){ if (j==1 || P.ch[i]==P.ch[j]){ ++i;++j; if (P.ch[i] != P.ch[j]) nextval[i] = j; else nextval[i] = nextval[j] }else j = nextval[j]; } }
2.4 队列 2.4.1 顺序队列 1. 基本概念 先进先出(FIFO ),后进后出
连续的存储空间 + 1队首指针 + 1队尾指针
判空:Q.front==Q.rear
判满:Q.rear==MaxSize
缺陷:假上溢
2. 结构定义 1 2 3 4 5 6 7 8 9 typedef struct QNode { QElmeType data; struct QNode *next ; }QNode,*QueuePtr; typedef struct { QueuePtr front; QueuePtr rear; }LinkQueue;
3. 基本操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 Status InitQueue (LinkQueue &Q) { Q.front = Q.rear = (QueuePtr)malloc (sizeof (QNode)); if (!Q.front) exit (OVERFLOW); Q.front->next = NULL ; return OK; } Status EnQueue (LinkQueue &Q,QElemType e) { p = (QueuePtr)malloc (sizeof (QNode)); if (!p) exit (OVERFLOW); p->data = e; p->next = NULL ; Q.rear->next = p; Q.rear = p; return OK; } Status DeQueue (LinkQueue &Q,QElemType &e) { if (Q.rear == Q.front) return ERROR; p = Q.front->next; e = p->data; Q.front->next = p->next; if (Q.rear == p) Q.rear = Q.front; free (p); return OK; }
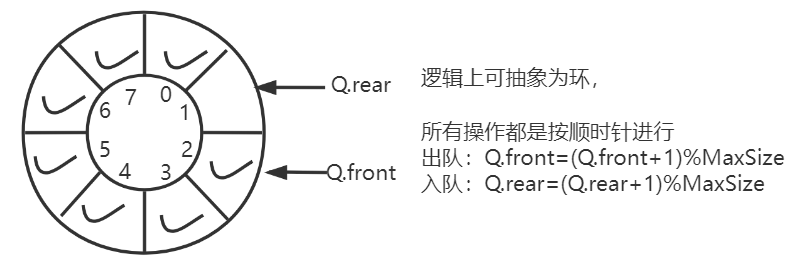
2.4.2 循环队列 1. 基本概念
初始条件
Q.front 指向队首元素
Q.rear 指向队尾元素后一位置
队长
(Q.rear-Q.front+MaxSize)%MaxSize
判断条件
队头指针在队尾指针的下一位位置作为队满的标志 牺牲一空间
队满条件:(Q.rear+1)%MaxSize==Q.front
队空条件:Q.front==Q.rear
结点类型中,增加表示元素个数的数据项 size 记录元素个数
队满条件:Q.size==MaxSize
队空条件:Q.size==0
结点类型中,增设 tag 不牺牲存储空间
队满条件:Q.rear==Q.front && Q.tag==1
队空条件:Q.rear==Q.front && Q.tag==0
进队置 tag=1 ,出队置 tag=0
若因出队导致 Q.rear==Q.front ,此时 tag=0 则队空;
若因入队导致 Q.rear==Q.front ,此时 tag=1 则队满
2. 存储结构 1 2 3 4 5 6 #define MAXSIZE 100 typedef struct { QElemType *base; int front; int rear; }SqQueue;
3. 基本操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 # 初始化 Status InitQueue (SqQueue &Q) { Q.base = (QElemType *)malloc (MAXSIZE*sizeof (QElemType)); if (!Q.base) exit (OVERFLOW); Q.front = Q.rear = 0 ; return OK; } # 入队 Status EnQueue (SqQueue &Q) { if ((Q.rear + 1 )%MAXSIZE == Q.rear) return ERROR; Q.base[Q.rear] = e; Q.rear = (Q.rear+1 )%MAXSIZE; return OK; } # 出队 Status DeQueue (SqQueue &Q,QElemType &e) { if (Q.front == Q.rear) return ERROR; e = Q.base[Q.front]; Q.front = (Q.front + 1 )%MAXSIZE; return OK; }
2.4.3 链式队列 1. 头结点对第一次入队的影响 不带头结点:判断 Q.front==Q.rear ,若不是,则需要将 Q.front 与 Q.rear 都指向首结点 带头结点:无需额外操作 2. 出队操作 若出队的是最后一个元素,则令 Q.rear=Q.front
3. 判空条件 Q.rear==Q.front
4. 存储结构的选择 一般队列:带头尾指针的 非循环单链表
不出队:即不从最后一个删除元素,故无需寻找最后一个元素的前一个结点,这是可以选择 只带尾指针的循环单链表
出队入队时间复杂度为 O(1) :带头尾指针的循环双链表
2.4.4 双端队列 队列的两端都可进行出队和入队操作
输出受限的双端队列:只有一端输出
$\iff$ 一个栈+一个可以从栈底入栈的栈
当限定进端即出端时,变为两个栈底相接的栈
2.4.5 FIFO思想的应用 1. 层序遍历 处理当前层的同时,就对下一层预处理。当前层处理完,可按与上一层相关联的处理顺序处理下一层
例:
2. 应用于计算机系统 排队等候
原因:
2.5 栈 2.5.1 基本概念 后进先出(LIFO)
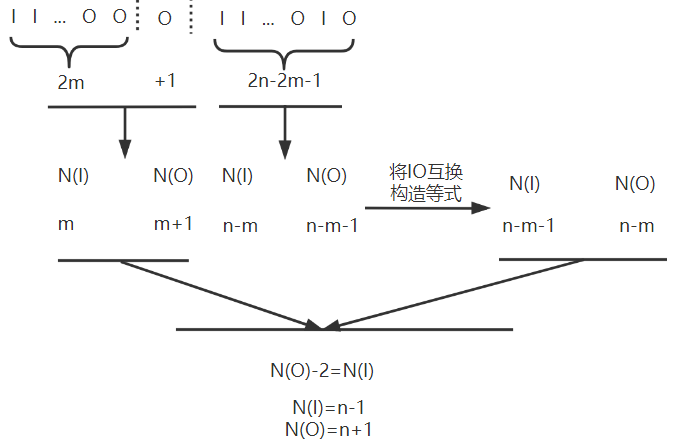
1. 卡特兰数 结论重要,证明仅供参考 :n个 不同元素 进栈,出栈序列有 $\frac{1}{n+1}C_{2n}^n$ 种
*证明 用 I 表示入栈,O 表示出栈,N() 表示 () 出现的次数:
n个元素的 IO 组合有 $C_{2n}^n$ 种,故 $N(合理出栈序列) = C_{2n}^n - N(不合理出栈序列)$
2.5.2 栈的存储结构 1. 顺序栈 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 typedef struct { ElemType *base; ElemType *top; int stackSize; }SqStack; StackEmpty() top == base; Pop(e) e = *--p; GetTop() e = *(top-1 ); Status Push (SqStack &S,ElemType e) { if (S.top - S.base == S.stacksize){ S.base = (ElemType *)realloc (S.base, (S.stackSize+STACKINCREMENT)*sizeof (ElemType)); if (!S) exit (OVERFLOW); S.top = S.base + S.stackSize; S.stackSize += STACKINCREMENT; } *S.top = e; S.top++; return OK; }
2. 链栈 使用 单链表 实现,规定所有的操作均在表头进行,无头结点
便于多个栈共享存储空间,提高存储效率 不存在栈满上溢
2.5.3 栈的应用 1. 进制转转换 除基取余,从下到上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # define SYSTEM 2 # define STACKMAXSIZE 100 typedef struct Stack { int *base; int top; int size; }Stack; void decimal2binary (int n) { InitSack(S); while (n!=0 ){ Push(S,n % SYSTEM); n /= SYSTEM; } int e; while (!StackEmpty(S)){ Pop(S,e); printf ("%d" ,e); } }
2. 括号匹配 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 typedef struct Stack { char *base; int size; int top; }Stack; bool BracketsCheck (char *str) { InitStack(S); int i = 0 ; while (str[i]!='\0' ){ switch (str[i]){ case '(' : Push(S,'(' ); break ; case '[' : Push(S,'[' ); break ; case '{' : Push(S,'{' ); break ; case ')' : Pop(S,e); if (e != '(' ) return false ; break ; case ']' : Pop(S,e); if (e != '[' ) return false ; break ; case '}' : Pop(S,e); if (e != '{' ) return false ; break ; default : break ; } i++; } if (!StackEmpty(S)) return false ; else return true ; }
3. 判断字符串是否中心对称 将串的前一半元素入栈。当串长度为奇数,跳过中间一个。
每从后一半串取到一个字符,都弹出栈顶一个字符,至栈为空,则中心对称。
若出现不相等,则不是中心对称
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 bool dc (char *str) { InitStack(S); int i; int len = 0 ; for (len = 0 ;str[len] != '\0' ;len++); for (i = 0 ;i < len/2 ;++i) Push(S,str[i]); if (len%2 ==1 ) i++; char e; while (str[i] != '\0' ){ Pop(S,e); if (e != str[i]) return false ; i++; } return true ; }
4. 递归与迭代 阶乘 1 2 3 4 5 6 7 8 9 10 11 int fac (int n) { if (n==0 ) return 1 ; return n*fac(n-1 ); } int fac (int n) { int cnt = 1 ,product = 1 ; for (cnt = 1 ;cnt <= n;cnt++) product *= cnt; return product; }
斐波那契数列 1 2 3 4 5 6 7 unsigned long long fib0 (int n) { if (n <= 1 ) return n; return fib0(n-1 )+fib0(n-2 ); }
1 2 3 4 5 6 7 8 9 10 11 12 long long fib2 (int n) { if (n <= 1 ) return 1 ; long long first = 0 ,second = 1 ,third = 0 ; for (int i = 2 ;i <= n;++i){ third = first + second; first = second; second = third; } return third; }
一个递归函数的非递归运算 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 long dp (int n,long x) { if (n == 0 ) return 1 ; if (n == 1 ) return 2 *x; return 2 *x*dp(n-1 ,x)-x*(n-1 )*dp(n-2 ,x); } # define MAXSIZE 100 typedef struct ElemType { int no; long value; }ElemType; typedef struct Stack { ElemType *base; int size; int top; }Stack; bool InitStack (Stack &S) { S.base = (ElemType *)malloc (MAXSIZE*sizeof (ElemType)); if (!S.base) exit (OVERFLOW); S.size = 0 ; S.top = -1 ; return true ; } long p (int n,long x) { long fv1=1 ,fv2 = 2 *x; if (n == 0 ) return fv1; Stack S; InitStack(S); for (int i = n;i >= 2 ;--i) S.base[++S.top].no = i; while (S.top >= 0 ){ S.base[S.top].value = 2 *x*fv2-2 *(S.base[S.top].no-1 )*fv1; fv1 = fv2; fv2 = S.base[S.top].value; S.top--; } return fv2; }
5. 判断栈的操作序列是否合法 I 的数量是否等于 O 的数量,且过程中 O 的数量不能大于 I 的数量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 int Judge (Char A[]) { int i = 0 ; int cnti = 0 ,cnto = 0 ; while (A[i] != '\0' ){ switch (A[i]){ case 'I' : cnti++; break ; case 'O' : cnto++; if (cnto > cnti){ printf ("序列非法" ); return 0 ; } break ; } i++; } if (cnti != cnto){ printf ("序列非法" ); return 0 ; }else { printf ("序列非法" ); return 1 ; } }
I 视为+1,O 视为-1,合法的栈操作序列过程中值不能小于0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 int Judge (char A[]) { int i = 0 ; int sum = 0 ; while (A[i]!='\0' ){ switch (A[i]){ case 'I' : sum++; break ; case 'O' : sum--; if (sum < 0 ){ printf ("非法操作序列!" ); return false ; } break ; } i++; } if (sum != 0 ){ printf ("非法操作序列" ); return false ; }else { printf ("合法操作序列" ); return true ; } }
2.5.4 表达式表示与计算 1. 中缀转后缀表达式 前提
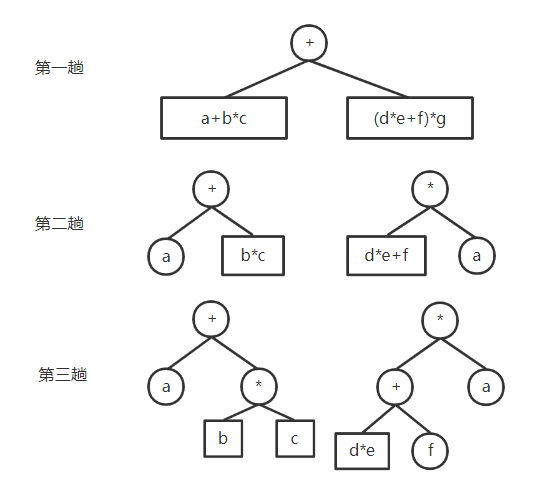
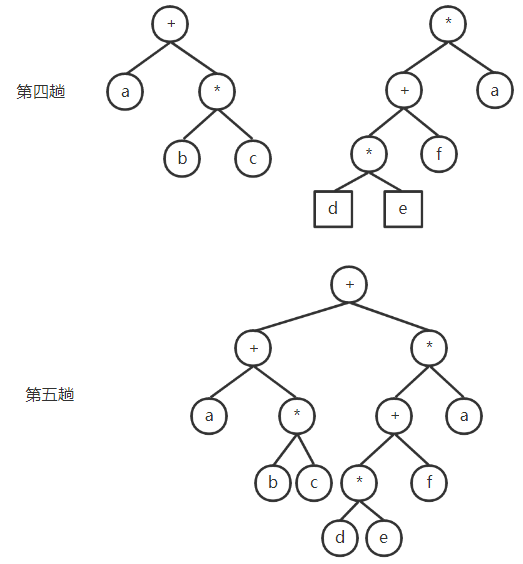
借助一个符号栈 例如 a+bc+(d\ e+f)*g $\Longrightarrow$ abc*+de*f+g*+
二叉树 找优先级最低的运算符作为根 分别对左右子树两部分表达式操作 重复1 2 直至表达式中只有数字
叶子结点都是操作数;非叶结点都是操作符 根结点运算符优先级最低 2. 后缀表达式运算 从左至右扫描后缀表达式
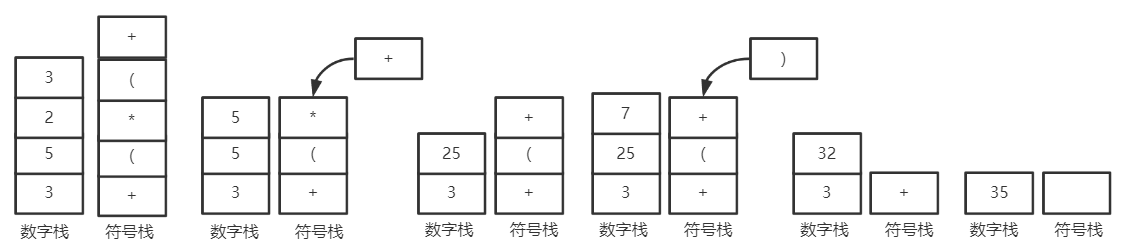
若是数字,则压入数字栈 若是运算符,则弹出栈顶两元素,先读出的为右操作数,后读出的为左操作数,将运算结果压栈
3. 中缀表达式运算 从左到有扫描中缀表达式
若是数字,直接入数字栈
若是操作符
‘(‘,直接入符号栈
‘)’,不停地把符号栈中 top 出栈,直至遇到 ‘(‘
‘* \\ + -‘ ,比较当前元素与符号栈顶 top 优先级比较
若 top < current,则压入符号栈 若 top >= current,则栈顶符号出栈,直至满足 top < current 符号栈每次出栈,需要从数字栈中连续出栈两次,将 数字栈.top <op> 数字栈.top-- 压入数字栈
表达式扫描完后,若符号栈不空,则将数字栈中按照前四条运算。直至符号栈空
2.6 矩阵和广义表 2.6.1 数组 1. 基本概念 顺序存储线性表
注
2. 基本操作 数组被定义后,维数与维界不再改变,只能存取和修改
3. 存储 连续的内存空间
多维数组的映射方式 行下标 $[0,h_1]$ ,列下标 $[0,h_2]$
2.6.2 矩阵压缩存储 矩阵压缩存储:将二维矩阵映射到一维数组,并将矩阵中元素按矩阵下标与一维数组下标间的某一种映射关系存储到数组中
注
A[1…n][1…n] 表示矩阵,下标从 (1,1) 开始 B表示存储数组,下标从 0 开始 1. 对称矩阵 目的:
由于对称阵 A[i][j]==A[j][i] ,故对 A[i][j] 按 按列优先存储 与 按行优先存储 在一维存储数组中位置相同,即成立
理解 : 按行优先,A[i][j] 的下三角前 i-1 行全部存入到存储数组中,共占 $\frac{(1+i-1)(i-1)}{2}$ 个存储空间。第 i 行的前 j-1 个元素存入存储数组,故共占 $\frac{(1+i-1)(i-1)}{2}+j-1$ 个存储空间。
2. 三角矩阵 下三角 存完下三角区,再加相同的上三角区元素
行优先 :矩阵下标 A[i][j] 与存储数组下标 B[k] 的对应关系为
上三角 存完上三角区,再加相同的下三角区元素
行优先 :矩阵下标 A[i][j] 与存储数组下标 B[k] 的对应关系为
上三角矩阵行优先 存储与 下三角矩阵按列优先 存储下标相同,故不再过多推导。
3. 三对角矩阵
除第一行和最后一行有两个元素,其余各行都有三个元素,故
2.6.3稀疏矩阵 1. 十字链表存储
2. 三元组存储 定义 1 2 3 4 5 6 7 8 9 10 #define MAXSIZE 10000 typedef int datatype;typedef struct { int i,j; datatype v; }triple; typedef struct { triple data[MAXSIZE]; int m,n,t; }tripletable;
三元组转置 1 2 3 4 5 6 7 8 9 10 11 12 13 void transmatrix (tripletable A,tripletable &AT) { AT.m = A.m; AT.n = A.n; AT.t = A.t; if (AT.t <= 0 ) return ; for (int p = 0 ;p <A.t;++p){ AT.data[p].i = A.data[p].j; AT.data[p].j = A.data[p].i; AT.data[p].v = A.data[p].v; } }
但此时 AT 不是按 i 递增排序的
设置向量 num ,num[copt] 表示 A 中第 col 列中非零元的个数
1 2 3 4 for (col = 1 ;col < A.n;++col) num[col] = 0 ; for (p = 1 ;p <= A;++p) num[A.data[p].j]++;
设置向量 cpot ,cpot[col] 指示 A 中第 col 列的第一个非零元在转置矩阵 AT.data 中的位置
1 2 3 cpot[1 ] = 1 ; for (col = 2 ;col <= A.n;++col) cpot[col] = cpot[col-1 ]+num[col-1 ];
遍历 A 三元组表,it 表示 A.data[p] ,it 在 AT 中的位置由 cpot[it] 指示。 完成转置后,将该列的第一个空闲位置后移。
1 2 3 4 5 6 7 for (p = 1 ;p <= A.t;++p){ col = A.data[p].j; q = copt[col]; AT.data[q].i = A.data[p].j; AT.data[q].j = A.data[p].i; cpot[col]++; }
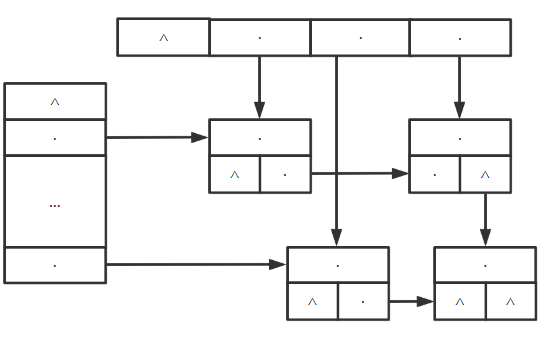
2.6.4 广义表 1. 定义 任何一个非空广义表 $LS=(\alpha1,\alpha2,…\alpha_n)$ 可分解为表头和表尾两部分
表头 :第一个 元素
表尾 :除第一个元素外其余元素构成的 表
$Tail(LS) = (\alpha2,…\alpha n)$ $D = (E,F) = ((a,(b,c),F)$
Head(D) = E Tail(D) = (F) Head(E) = a Tail(E) = ((b,c)) Head(((b,c))) = (b,c) Tail(((b,c))) = () Head((b,c)) = b Tail(b,c) = (c) 2. 特点 广义表的 长度 为表中元素个数 广义表的 深度 为表的嵌套层数 A = ():A是一个空表,深度为1,长度为0 B = (e):B中只有一个原子,深度为1,长度为1 C = (a,(b,c,d)):C中有一个原子和一个子表,深度为2,长度为2 D = (A,B,C):D中有3个子表,深度为3,长度为3