[TOC]
OSD组件
op_shardedwq
Ceph OSD处理OP,snap trim,scrub的是相同的work queue - osd::op_shardedwq
相关数据结构
这里主要涉及到两个数据结构:
class PGQueueableclass ShardedOpWQ
class PGQueueable
这个是封装PG一些请求的class,相关的操作有:
OpRequestRefPGSnapTrimPGScrub
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
class PGQueueable {
typedef boost::variant<
OpRequestRef,
PGSnapTrim,
PGScrub
> QVariant;
QVariant qvariant;
int cost;
unsigned priority;
utime_t start_time;
entity_inst_t owner;
epoch_t map_epoch;
...
public:
PGQueueable(OpRequestRef op)
: qvariant(op), cost(op->get_req()->get_cost()),
priority(op->get_req()->get_priority()),
start_time(op->get_req()->get_recv_stamp()),
owner(op->get_req()->get_source_inst())
{}
PGQueueable(
const PGSnapTrim &op, int cost, unsigned priority, utime_t start_time,
const entity_inst_t &owner)
: qvariant(op), cost(cost), priority(priority), start_time(start_time),
owner(owner) {}
PGQueueable(
const PGScrub &op, int cost, unsigned priority, utime_t start_time,
const entity_inst_t &owner)
: qvariant(op), cost(cost), priority(priority), start_time(start_time),
owner(owner) {}
PGQueueable(
const PGRecovery &op, int cost, unsigned priority, utime_t start_time,
const entity_inst_t &owner, epoch_t e)
: qvariant(op), cost(cost), priority(priority), start_time(start_time),
owner(owner), map_epoch(e) {}
...
void run(OSD *osd, PGRef &pg, ThreadPool::TPHandle &handle) {
RunVis v(osd, pg, handle);
boost::apply_visitor(v, qvariant);
}
...
};
|
class ShardedOpWQ
这个是OSD中shard相关线程的work queue类,用来处理PGQueueable封装的三类PG操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| class OSD : public Dispatcher, public md_config_obs_t
{
...
friend class PGQueueable;
class ShardedOpWQ: public ShardedThreadPool::ShardedWQ < pair <PGRef, PGQueueable> > {
struct ShardData {
Mutex sdata_lock;
Cond sdata_cond;
Mutex sdata_op_ordering_lock;
map<PG*, list<PGQueueable> > pg_for_processing;
std::unique_ptr<OpQueue< pair<PGRef, PGQueueable>, entity_inst_t>> pqueue;
ShardData(
string lock_name, string ordering_lock,
uint64_t max_tok_per_prio, uint64_t min_cost, CephContext *cct,
io_queue opqueue)
: sdata_lock(lock_name.c_str(), false, true, false, cct),
sdata_op_ordering_lock(ordering_lock.c_str(), false, true, false, cct) {
if (opqueue == weightedpriority) {
pqueue = std::unique_ptr
<WeightedPriorityQueue< pair<PGRef, PGQueueable>, entity_inst_t>>(
new WeightedPriorityQueue< pair<PGRef, PGQueueable>, entity_inst_t>(
max_tok_per_prio, min_cost));
} else if (opqueue == prioritized) {
pqueue = std::unique_ptr
<PrioritizedQueue< pair<PGRef, PGQueueable>, entity_inst_t>>(
new PrioritizedQueue< pair<PGRef, PGQueueable>, entity_inst_t>(
max_tok_per_prio, min_cost));
}
}
};
vector<ShardData*> shard_list;
OSD *osd;
uint32_t num_shards;
...
void _process(uint32_t thread_index, heartbeat_handle_d *hb);
void _enqueue(pair <PGRef, PGQueueable> item);
void _enqueue_front(pair <PGRef, PGQueueable> item);
...
} op_shardedwq;
...
}
|
op_shardedwq对应的thread pool为:osd_op_tp
osd_op_tp的初始化在OSD的初始化类中:
1
2
| osd_op_tp(cct, "OSD::osd_op_tp", "tp_osd_tp",
cct->_conf->osd_op_num_threads_per_shard * cct->_conf->osd_op_num_shards),
|
这里相关的配置参数有:
osd_op_num_threads_per_shard,默认值为 2osd_op_num_shards,默认值为 5
PG会根据一定的映射模式映射到不同的shard上,然后由该shard对应的thread处理请求;
ShardedOpWQ的处理函数
该sharded的work queue的process函数如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
void OSD::ShardedOpWQ::_process(uint32_t thread_index, heartbeat_handle_d *hb )
{
...
pair<PGRef, PGQueueable> item = sdata->pqueue->dequeue();
boost::optional<PGQueueable> qi;
if (!pg) {
pg = osd->_lookup_lock_pg(item.first);
} else {
pg->lock();
}
op->run(osd, item.first, tp_handle);
...
sdata->sdata_op_ordering_lock.Unlock();
}
|
从上面可以看出在调用实际的处理函数前,就先获取了PG lock;处理返回后释放PG lock;
osd::opshardedwq的 _process() 函数会根据request的类型,调用不同的函数处理:
OSD::dequeue_op()ReplicatedPG::snap_trimmer()PG::scrub()
在文件src/osd/PGQueueable.cc中有这三类操作的不同处理函数定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| void PGQueueable::RunVis::operator()(const OpRequestRef &op) {
osd->dequeue_op(pg, op, handle);
}
void PGQueueable::RunVis::operator()(const PGSnapTrim &op) {
pg->snap_trimmer(op.epoch_queued);
}
void PGQueueable::RunVis::operator()(const PGScrub &op) {
pg->scrub(op.epoch_queued, handle);
}
void PGQueueable::RunVis::operator()(const PGRecovery &op) {
osd->do_recovery(pg.get(), op.epoch_queued, op.reserved_pushes, handle);
}
|
PG lock粒度
从函数OSD::ShardedOpWQ::_process()中看出,thread在区分具体的PG请求前就获取了PG lock,在return前释放PG lock;这个PG lock的粒度还是挺大的,若snap trim和scrub占用了PG lock太久,会影响到OSD PG正常的IO操作;
OSD PG相关的OP类型有(OSD::dequeue_op()函数处理):
CEPH_MSG_OSD_OPMSG_OSD_SUBOPMSG_OSD_SUBOPREPLYMSG_OSD_PG_BACKFILLMSG_OSD_REP_SCRUBMSG_OSD_PG_UPDATE_LOG_MISSINGMSG_OSD_PG_UPDATE_LOG_MISSING_REPLY
osd_snap_trim_sleep和osd_scrub_sleep配置
从上面看g_conf->osd_snap_trim_sleep和g_conf->osd_scrub_sleep配置为非0后,能让snap trim和scrub在每次执行前睡眠一段时间(不是random时间),这样能一定程度上降低这两个操作对PG IO ops的影响(获取PG lock);
如果设置了osd_snap_trim_sleep或osd_scrub_sleep为非0,处理的线程会sleep,这样虽说释放了PG lock,但是占用了一个PG的一个处理线程,所以才有贴出来的ceph bug - http://tracker.ceph.com/issues/19497
现在我们配置的是:
osd_op_num_shards = 30osd_op_num_threads_per_shard = 2 //默认值
所以一旦某个shard对应的一个thread被占用了,对应处理该shard的只有一个thread了,这样就有可能影响映射到该shard上的PG的正常IO了。
https://www.yangguanjun.com/2018/10/25/ceph-bluestore-rocksdb-analyse/
Bluestore组件
对于bluestore存储引擎来说,RocksDB意义很大,存储了Bluestore相关的元数据信息,对它的理解有助于更好的理解BlueStore的实现,分析后续遇到的问题
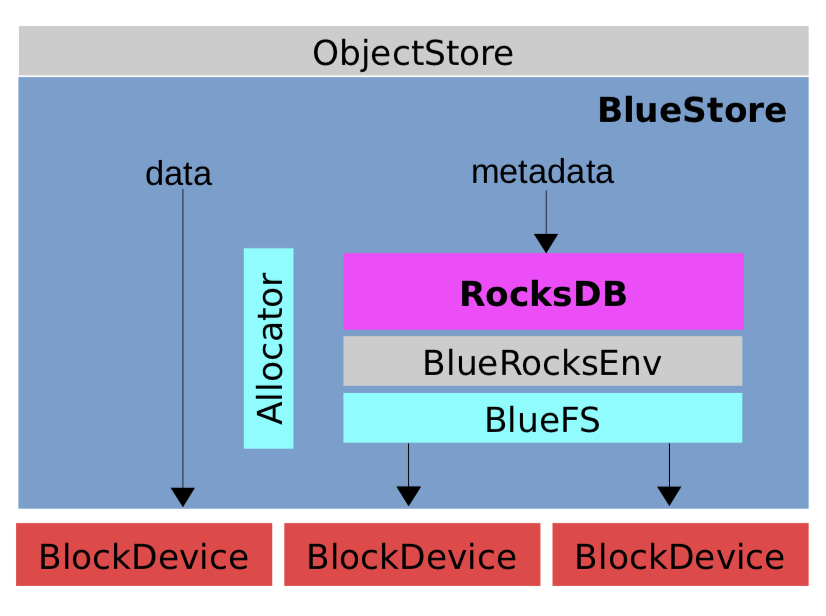
RocksDB对接了BlueStore的metadata信息
查看 BlueStore 的成员
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
class BlueStore : public ObjectStore, public md_config_obs_t {
...
private:
BlueFS *bluefs = nullptr;
unsigned bluefs_shared_bdev = 0;
bool bluefs_single_shared_device = true;
utime_t bluefs_last_balance;
KeyValueDB *db = nullptr;
BlockDevice *bdev = nullptr;
std::string freelist_type;
FreelistManager *fm = nullptr;
Allocator *alloc = nullptr;
uuid_d fsid;
int path_fd = -1;
int fsid_fd = -1;
bool mounted = false;
vector<Cache*> cache_shards;
std::mutex osr_lock;
std::set<OpSequencerRef> osr_set;
...
};
|
其中关键组件如下:
BlueFS
BlueFS *bluefs = nullptr;
支持RocksDB的定制FS,只实现了BlueRocksEnv需要的API接口;
对应于 _open_db() 将其初始化
1
2
3
4
5
6
7
8
9
10
11
|
int BlueStore::_open_db(bool create)
{
...
rocksdb::Env *env = NULL;
if (do_bluefs) {
bluefs = new BlueFS(cct);
...
}
...
}
|
RocksDB
KeyValueDB *db = nullptr;
BlueStore的元数据和OMap都通过DB存储,这里使用的是RocksDB,它的初始化也是在_open_db()函数中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| int BlueStore::_open_db(bool create)
{
string kv_backend;
if (create) {
kv_backend = cct->_conf->bluestore_kvbackend;
} else {
r = read_meta("kv_backend", &kv_backend);
}
if (create) {
do_bluefs = cct->_conf->bluestore_bluefs;
} else {
string s;
r = read_meta("bluefs", &s);
}
rocksdb::Env *env = NULL;
if (do_bluefs) {
bluefs = new BlueFS(cct);
bfn = path + "/block.db";
if (::stat(bfn.c_str(), &st) == 0) {
r = bluefs->add_block_device(BlueFS::BDEV_DB, bfn);
...
}
bfn = path + "/block";
r = bluefs->add_block_device(bluefs_shared_bdev, bfn);
...
bfn = path + "/block.wal";
if (::stat(bfn.c_str(), &st) == 0) {
r = bluefs->add_block_device(BlueFS::BDEV_WAL, bfn);
...
}
}
db = KeyValueDB::create(cct,
kv_backend,
fn,
static_cast<void*>(env));
...
}
|
BlockDevice
BlockDevice *bdev = nullptr;
底层存储BlueStore Data / db / wal的块设备,有如下几种:
- KernelDevice
- NVMEDevice
- PMEMDevice
代码中对其初始化如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| int BlueStore::_open_bdev(bool create)
{
string p = path + "/block";
bdev = BlockDevice::create(cct, p, aio_cb, static_cast<void*>(this));
int r = bdev->open(p);
if (bdev->supported_bdev_label()) {
r = _check_or_set_bdev_label(p, bdev->get_size(), "main", create);
}
block_size = bdev->get_block_size();
block_mask = ~(block_size - 1);
block_size_order = ctz(block_size);
r = _set_cache_sizes();
return 0;
}
|
FreelistManager
FreelistManager *fm = nullptr;
管理BlueStore里空闲的blob;
默认使用的是:BitmapFreelistManager
1
2
3
4
| int BlueStore::_open_fm(bool create){
fm = FreelistManager::create(cct, freelist_type, db, PREFIX_ALLOC);
int r = fm->init(bdev->get_size());
}
|
Allocator
BlueStore的blob分配器,支持如下几种:
- BitmapAllocator
- StupidAllocator
- …
BlueStore的mount过程
在BlueStore的 mount过程中,会调用各个函数来初始化其使用的各个组件,顺序如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| int BlueStore::_mount(bool kv_only)
{
int r = read_meta("type", &type);
if (type != "bluestore") {
return -EIO;
}
if (cct->_conf->bluestore_fsck_on_mount) {
...
}
int r = _open_path();
r = _open_fsid(false);
r = _read_fsid(&fsid);
r = _lock_fsid();
r = _open_bdev(false);
r = _open_db(false);
if (kv_only)
return 0;
r = _open_super_meta();
r = _open_fm(false);
r = _open_alloc();
r = _open_collections();
r = _reload_logger();
if (bluefs) {
r = _reconcile_bluefs_freespace();
}
_kv_start();
r = _deferred_replay();
mempool_thread.init();
mounted = true;
return 0;
}
|
Bluestore写流程
查看其实现的 ”objectStore → block device“ 映射
涉及的关键组件
- RocksDB:存储元数据信息
- BlueRocksEnv:提供RocksDB的访问接口
- BlueFS:实现BlueRocksEnv里的访问接口
- Allocator:磁盘分配器
Object与底层Device映射关系—相关的数据结构
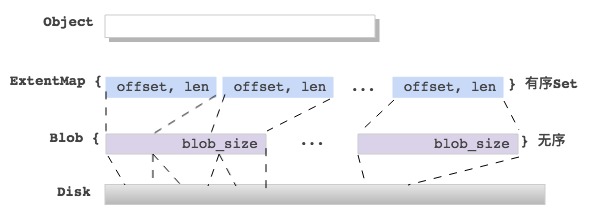
Onode
任何RADOS里的一个Object都对应Bluestore里的一个Onode(内存结构),定义如下:
1
2
3
4
5
6
| struct Onode {
Collection *c;
ghobject_t oid;
bluestore_onode_t onode;
ExtentMap extent_map;
};
|
通过Onode里的ExtentMap来查询Object数据到底层的映射
ExtentMap
ExtentMap是Extent的set集合,是有序的,定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
| struct ExtentMap {
Onode *onode;
extent_map_t extent_map;
blob_map_t spanning_blob_map;
struct Shard {
bluestore_onode_t::shard_info *shard_info = nullptr;
unsigned extents = 0;
bool loaded = false;
bool dirty = false;
};
mempool::bluestore_cache_other::vector<Shard> shards;
};
|
ExtentMap还提供了分片功能,防止在文件碎片化严重,ExtentMap很大时,影响写RocksDB的性能。
ExtentMap会随着写入数据的变化而变化;
ExtentMap的连续小段会合并为大;
覆盖写也会导致ExtentMap分配新的Blob;
Extent
Extent是实现object的数据映射的关键数据结构,定义如下:
1
2
3
4
5
6
| struct Extent : public ExtentBase {
uint32_t logical_offset = 0;
uint32_t blob_offset = 0;
uint32_t length = 0;
BlobRef blob;
};
|
每个Extent都会映射到下一层的Blob上,Extent会依据 block_size 对齐,没写的地方填充全零。
Extent中的length值,最小:block_size,最大:max_blob_size
Blob
Blob是Bluestore里引入的处理块设备数据映射的中间层,定义如下:
1
2
3
4
5
6
7
8
9
10
| struct Blob {
int16_t id = -1;
SharedBlobRef shared_blob;
mutable bluestore_blob_t blob;
};
struct bluestore_blob_t {
PExtentVector extents;
uint32_t logical_length = 0;
uint32_t compressed_length = 0;
};
|
每个Blob会对应一组 PExtentVector,它就是 bluestore_pextent_t 的一个数组,指向从Disk中分配的物理空间。
Blob里可能对应一个磁盘pextent,也可能对应多个pextent;
Blob里的pextent个数最多为:max_blob_size / min_alloc_size;
Blob里的多个pextent映射的Blob offset可能不连续,中间有空洞;
AllocExtent
AllocExtent是管理物理磁盘上的数据段的,定义如下:
1
2
3
4
5
6
7
8
9
| struct bluestore_pextent_t : public AllocExtent {
...
};
class AllocExtent {
public:
uint64_t offset;
uint32_t length;
...
};
|
AllocExtent的 length值,最小:min_alloc_size,最大:max_blob_size
BlueStore写数据流程
BlueStore里的写数据入口是BlueStore::_do_write(),它会根据 min_alloc_size 来切分 [offset, length] 的写,然后分别依据 small write 和 big write 来处理,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
[offset, length]
|==p1==|=======p2=======|=p3=|
|----------------|----------------|----------------|
| min_alloc_size | min_alloc_size | min_alloc_size |
|----------------|----------------|----------------|
small write: p1, p3
big write: p2
BlueStore::_do_write()
|-- BlueStore::_do_write_data()
|
| | -- BlueStore::_do_write_small()
| | | -- BlueStore::ExtentMap::seek_lextent()
| | | -- BlueStore::Blob::can_reuse_blob()
| | reuse blob? or new blob?
| | | -- insert to struct WriteContext {};
| | -- BlueStore::_do_write_big()
| | | -- BlueStore::ExtentMap::punch_hole()
| | | -- BlueStore::Blob::can_reuse_blob()
| | reuse blob? or new blob?
| | | -- insert to struct WriteContext {};
|-- BlueStore::_do_alloc_write()
| | -- StupidAllocator::allocate()
| | -- BlueStore::ExtentMap::set_lextent()
| | -- BlueStore::_buffer_cache_write()
|-- BlueStore::_wctx_finish()
|
小写先写到RocksDB,大写直接落盘
BlueStore Log分析
通过开启Ceph bluestore debug来抓取其写过程中对数据的映射,具体步骤如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| # 1. 创建一个文件
touch tstfile
# 2. 查看该文件的inode numer
ls -i
2199023255554 tstfile
# 3. 获取该文件的映射信息
# 上述inode number转换为16进制:20000000002
# 查看文件的第一个默认4M Object的映射信息
ceph osd map cephfs_data_ssd 20000000002.00000000
osdmap e2649 pool 'cephfs_data_ssd' (3) object '20000000002.00000000' -> pg 3.3ff3fe94 (3.94) -> up ([12,0], p12) acting ([12,0], p12)
# osdmap epoch数 存储池 对象id -> pg id -> osd id
# 4. 在osd 12上开启bluestroe debug信息
ceph daemon /var/run/ceph/ceph-osd.12.asok config set debug_bluestore "30" # 开启debug
ceph daemon /var/run/ceph/ceph-osd.12.asok config set debug_bluestore "1/5" # 恢复默认
# 5. 对测试文件的前4M内进行dd操作,收集log
dd if=/dev/zero of=tstfile bs=4k count=1 oflag=direct
grep -v "trim shard target" /var/log/ceph/ceph-osd.12.log | grep -v "collection_list" > bluestore-write-0-4k.log
|
通过上述方式可以搜集到Bluestore在写入数据时,object的数据分配和映射过程,可以帮助理解其实现。
BlueStore dd write各种case
为了更好的理解BlueStore里一个write的过程,我们通过dd命令写一个Object,然后抓取log后分析不同情况下的Object数据块映射情况,最后结果如下图所示:
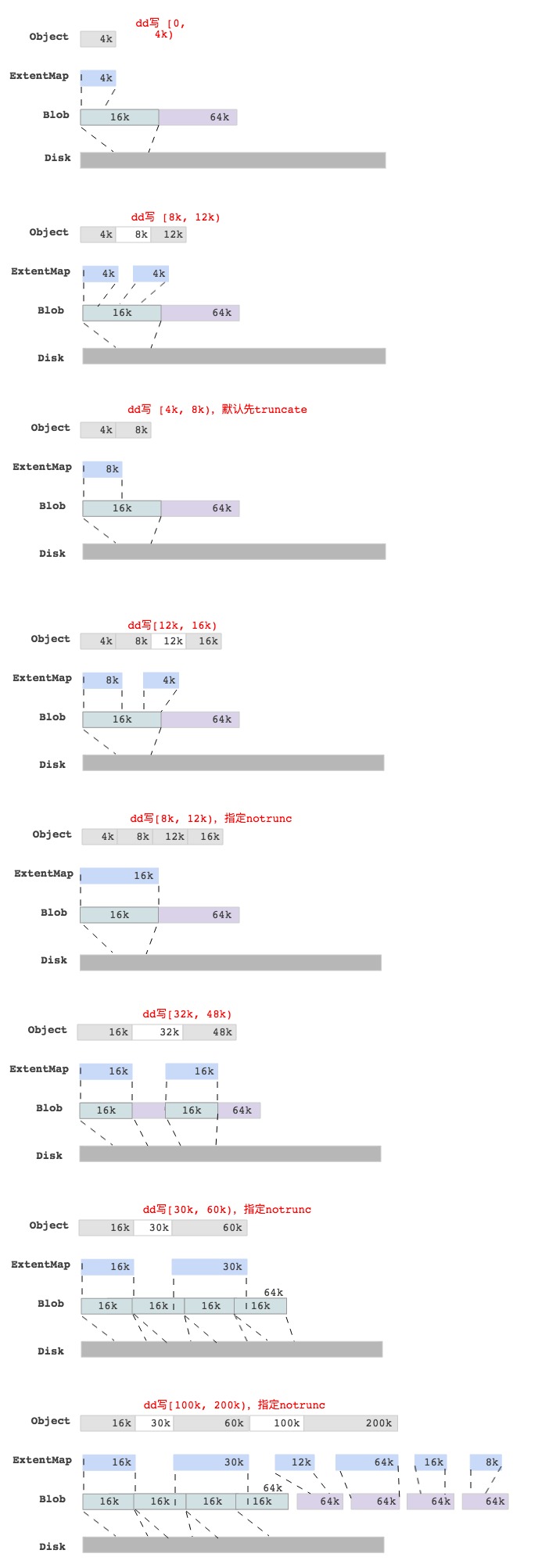
注释:上图的数据块映射关系是通过抓取log后获取的。
最后一图中,写[100k, 200)的区域,查看Object对应的ExtentMap并不是与 min_alloc_size(16k)对齐的,只是保证是block_size(4k)对齐而已。