cephadm是一个用于管理 Ceph 集群的实用程序。以下列出了cephadm可以执行的一些操作:
- 将Ceph容器添加到集群中。
- 从集群中删除一个 Ceph 容器。
- 更新 Ceph 容器。
cephadm 不依赖于 Ansible、Rook 或 Salt 等外部配置工具。但是,这些外部配置工具可用于自动执行 cephadm 本身未执行的操作。要了解有关这些外部配置工具的更多信息,请访问其页面:
- https://github.com/ceph/cephadm-ansible
- https://rook.io/docs/rook/v1.10/Getting-Started/intro/
- https://github.com/ceph/ceph-salt
cephadm管理Ceph集群的整个生命周期:
- 从引导过程(bootstraping process)开始,此时
cephadm在但每个节点上创建了一个小型Ceph集群。这个集群由一个mon和mgr组成。 - 然后,cephadm 使用编排接口 (orchestration interface) 扩展集群、添加主机并配置 Ceph 守护进程和服务。
可以通过 Ceph 命令行界面 (CLI) 或仪表板 (GUI) 执行此生命周期的管理。
cephadm 仅适用于 BlueStore OSD。集群中的 FileStore OSD 无法使用 cephadm 进行管理
版本兼容性
要使用 cephadm 开始使用 Ceph,请按照部署新的 Ceph 集群中的说明进行操作。
cephadm 是在 Ceph v15.2.0 (Octopus) 中引入的,不支持旧版本的 Ceph
下表显示了哪些版本对预计可以一起使用或不能一起使用:
https://docs.ceph.com/en/quincy/cephadm/compatibility/#compatibility-with-podman-versions
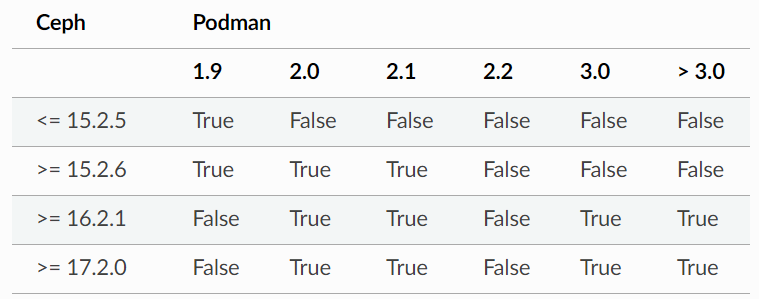
虽然并非所有 Podman 版本都针对所有 Ceph 版本进行了主动测试,但将 Podman 3.0 版或更高版本与 Ceph Quincy 及更高版本一起使用没有已知问题。
要将 Podman 与 Ceph Pacific 结合使用,您必须使用 2.0.0 或更高版本的 Podman。但是,Podman 版本 2.2.1 不适用于 Ceph Pacific。 已知“Kubic stable”可与 Ceph Pacific 配合使用,但它必须使用较新的内核运行。
稳定性
Cephadm 相对稳定,但仍在添加新功能,偶尔会发现错误。
Cephadm 对以下功能的支持仍在开发中:
- ceph-exporter deployment
- stretch mode integration
- 监控堆栈(转向 prometheus 服务发现并提供 TLS)
- RGW multisite deployment support (requires lots of manual steps currently)
- cephadm agent
如果 cephadm 命令失败或服务停止正常运行,请参阅 暂停或禁用 cephadm以获取有关如何暂停 Ceph 集群后台活动以及如何禁用 cephadm 的说明。
安装
https://docs.ceph.com/en/quincy/cephadm/install/
两种方法安装 cephadm
- a curl-based installation method 基于curl的安装方法
- distribution-specific installation methods 特定于发行版的安装
不能同时使用基于curl 的方法和特定于发行版的安装
在 Quincy 中,cephadm 不是作为从源代码编译的可执行文件分发的。该功能是在 Reef 版本中引入的。
特定于发行版的安装
某些 Linux 发行版可能已经包含最新的 Ceph 软件包。在这种情况下,您可以直接安装cephadm。
In Ubuntu:
1 | apt install -y cephadm |
In CentOS Stream:
1 | dnf search release-ceph |
In Fedora:
1 | dnf -y install cephadm |
In SUSE:
1 | zypper install -y cephadm |
基于curl的安装方法
首先,确定您要安装的 Ceph 版本。您可以使用版本页面查找最新的活动版本。例如,我们可能会发现 18.2.1 是最新的活跃版本。
使用curl 获取该版本的cephadm 版本。
1 | CEPH_RELEASE=18.2.0 # replace this with the active release |
确保 cephadm 文件可执行:
1 | chmod +x cephadm |
该文件可以直接从当前目录运行:
1 | ./cephadm <arguments...> |
如果您因错误(包括错误解释器消息)而在运行 cephadm 时遇到任何问题,则您可能没有安装 Python 或正确版本的 Python。
cephadm 工具需要 Python 3.6 或更高版本。您可以通过在命令前加上已安装的 Python 版本作为前缀,使用特定版本的 Python 手动运行 cephadm。例如:
1 | python3.8 ./cephadm <arguments...> |
尽管独立的 cephadm 足以引导集群,但最好在主机上安装 cephadm 命令。要安装提供 cephadm 命令的软件包,请运行以下命令:
1 | ./cephadm add-repo --release quincy |
通过运行以下命令确认 cephadm 现在位于您的 PATH 中:
1 | which cephadm |
主机管理
列出主机
1 | ceph orch host ls [--format yaml] [--host-pattern <name>] [--label <label>] [--host-status <status>] |
- “host-pattern” 是一个与主机名匹配的正则表达式,它仅返回匹配的主机。
- “label” 仅返回具有指定标签的主机。
- “host-status” 仅返回具有指定状态(当前为“offline”或“maintenance”)的主机。
- 这些过滤标志的任意组合都是有效的。可以同时过滤名称、标签和状态,或者过滤名称、标签和状态的任何适当子集。
“detail”参数为基于 cephadm 的集群提供更多主机相关信息
1 | ceph orch host ls --detail |
添加主机
主机需要满足一些 要求 ,不满足所有要求的主机无法被添加到集群中,可以使用检查指令,判断是否安装好cephadm所需的全部依赖。
1 | cephadm check-host --expect-hostname node01 |
在新主机的root用户的
authorized_keys文件夹中,安装集群的公共SSH密钥1
2ssh-copy-id -f -i /etc/ceph/ceph.pub root@*<new-host>*
ssh-copy-id -f -i /etc/ceph/ceph.pub root@192.168.182.133告诉 Ceph 新节点是集群的哪一部分
1
2
3ceph orch host add *<newhost>* [*<ip>*] [*<label1> ...*]
ceph orch host add local-168-182-130 192.168.182.130
最好显式提供主机 IP 地址。 如果 IP 是 未提供,则主机名将立即通过 将使用该 DNS 和该 IP。
还可以包含一个或多个标签以立即标记 新主机,例如,默认情况下,_admin 标签将使 cephadm 在 /etc/ceph 中维护 ceph.conf 文件和 client.admin 密钥环文件的副本:
1 | ceph orch host add local-168-182-130 192.168.182.130 --labels _admin |
删除主机
删除所有守护程序后,可以安全地从集群中移除主机 从它。
要从主机中排出所有守护程序,请运行以下形式的命令
1
2ceph orch host drain *<host>*
ceph orch host drain local-168-182-130_no_schedule和_no_conf_keyring标签将应用于主机。如果仅向排出守护进程,但将管理 conf 和 keyring 文件保留在主机上,可将
--keep-conf-keyring添加在排除指令后1
ceph orch host drain *<host>* --keep-conf-keyring
1
2主机上的所有所有 osd 都将按计划删除。您可以通过以下方式检查 osd 删除进度:
ceph orch osd rm statusorch host排出命令还支持—zap-osd-devices标志。在排空主机时设置此标志将导致 cephadm 在排空过程中删除它正在删除的 OSD 设备
1
ceph orch host drain *<host>* --zap-osd-devices
可以使用以下命令检查主机上是否没有守护程序:
1
2
3ceph orch ps <host>
ceph orch ps local-168-182-130删除所有守护程序后,可以使用以下命令删除主机:
1
2ceph orch host rm <host>
ceph orch host rm local-168-182-130如果主机处于脱机状态且无法恢复,仍可以通过以下方法将其从群集中移除:
1
2ceph orch host rm <host> --offline --force
ceph orch host rm local-168-182-130 --offline --force这可能会导致数据丢失。此命令通过为每个 OSD 调用 osd purge-actual 来强制从集群中清除 OSD。仍包含此主机的任何服务规范都应手动更新。
主机标签
Orchestrator 支持将标签分配给主机。标签 是自由形式的,本身和每个主机都没有特定的含义 可以有多个标签。它们可用于放置指定的守护进程。
添加标签
1
2
3
4
5
6
7为新添加的主机指定标签
ceph orch host add my_hostname --labels=my_label1
ceph orch host add local-168-182-130 --labels=my_label1,my_label2
为已经存在的主机添加标签
也可以,ceph orch host label add my_hostname my_label
ceph orch host label add local-168-182-130 my_label删除标签
1
2ceph orch host label rm my_hostname my_label
ceph orch host label rm local-168-182-130 my_label
特殊主机标签
以下主机标签对头孢具有特殊含义。 都始于 _
_no_schedule: 不要在此主机上调度或部署守护程序此标签可防止 cephadm 在此主机上部署守护程序。 如果它被添加到 已经包含 Ceph 守护进程的现有主机,将导致 cephadm 移动 其他位置的守护程序(OSD 除外,不会自动删除)。
_no_conf_keyring:不要在此主机上部署配置文件或密钥。该标签实际上与 _no_schedule 相同,但它不适用于守护进程,它适用于由 cephadm 管理的客户端密钥环和 ceph conf 文件
_no_autotune_memory:不自动调整此主机上的内存此标签将阻止守护程序内存被调整,即使 osd_memory_target_autotune 或为一个或多个守护程序启用类似选项 在该主机上。
_admin:将 client.admin 和 ceph.conf 分发到此主机.该标签应用于集群中的第一台主机(最初运行 bootstrap 的地方),并且 client.admin 密钥设置为通过 ceph orch client-keyring … 函数分发到该主机。
将此标签添加到其他主机通常会导致 cephadm 在 /etc/ceph 中部署配置和密钥环文件
从版本 16.2.10 (Pacific) 和 17.2.1 (Quincy) 开始,除了默认位置
/etc/ceph/ cephadm还将配置和密钥环文件存储在/var/lib/ceph/<fsid>/config目录中。1
ceph orch client-keyring …/etc/ceph/etc/ceph//var/lib/ceph/<fsid>/config
维护模式
将主机置于维护模式和退出维护模式(停止主机上的所有 Ceph 守护进程)
1 | 进入维护模式 |
--force 标志允许用户绕过警告(但不能绕过警报)。
--yes-i-really-mean-it 标志会绕过所有安全检查,并且无论如何都会尝试强制主机进入维护模式。
使用 –yes-i-really-mean-it 标志强制主机进入维护模式可能会导致数据可用性丧失、mon quorum 因运行的监视器太少而崩溃、mgr 模块命令(例如命令)变得无响应,以及许多其他可能的问题。请仅在您绝对确定自己知道自己在做什么的情况下使用此标志。
重新扫描主机设备(rescanning host devices)
某些服务器和外部机箱可能不会向内核注册设备移除或插入。在这些情况下,您需要在适当的主机上执行设备重新扫描。
重新扫描通常不会造成中断,可以使用以下 CLI 命令执行:
1 | ceph orch host rescan <hostname> [--with-summary] |
with-summary 提供了已发现和扫描的 HBA 数量的详细信息,以及失败的 HBA 数量
1 | ceph orch host rescan rh9-ceph1 --with-summary |
一次创建多个主机
通过提交 multi-document YAML 文件,可以使用 ceph orch apply -i 一次添加许多主机:
1 | service_type: host |
这可以与服务规范相结合 ,以创建集群规范文件,从而通过一个命令部署整个集群。
在添加集群 SSH 密钥之前,必须将其复制到主机。cephadm bootstrap --apply-spec
CRUSH相关
设置主机的初始CRUSH位置
主机能包含 location 标签,这将指示 cephadm 创建位于指定层次结构的新CRUSH主机
1 | service_type: host |
cephadm将创建 rack 级的CRUSH
location 标签仅影响初始CRUSH的位置。location 属性的后续更改将被忽略。此外,删除主机不会删除关联的 CRUSH 存储桶,除非向 orch host rm 命令提供 —rm-crush-entry 标志
从CRUSH map中删除主机
ceph orch host rm 命令支持从 CRUSH 映射中删除关联的主机存储桶。这是通过提供 --rm-crush-entry 标志来完成的。
1 | cephadm 将尝试从 CRUSH map中删除主机存储桶,作为host删除的一部分 |
- 如果主机上部署了 OSD,则从 CRUSH 映射中删除将会失败。
- 首先使用 ceph orch host排出命令来在进行主机删除,及本指令执行。
- 删除OSD后,应该是可以执行成功的。
调整OS配置
调整配置
Cephadm 可用于管理将 sysctl 设置应用于主机集的操作系统调整配置文件。
创建 YAML 文件
1 | profile_name: 23-mon-host-profile |
使用以下命令应用配置文件
1 | ceph orch tuned-profile apply -i <tuned-profile-file-name> |
该指令将配置文件将写入 placement 中指定的主机的 /etc/sysctl.d/ 目录下,
然后在该主机上运行 sysctl --system
在
/etc/sysctl.d/中写入的配置文件名是<profile-name>-cephadm-tuned-profile.conf,其中<profile-name>是您在 YAML 规范中指定的 profile_name 设置。我们建议按照通常的 sysctl.d NN-xxxxx 约定命名这些配置文件。由于 sysctl 设置按字典顺序应用(按指定设置的文件名排序),因此您可能需要仔细选择规范中的 profile_name,以便它在其他 conf 文件之前或之后应用。
仔细选择可确保此处提供的值根据需要覆盖或不覆盖其他 sysctl.d 文件中的值。
这些设置仅应用于主机级别,并不特定于任何特定的守护程序或容器。
当传递 —no-overwrite 选项时,应用调整配置文件是幂等的。此外,如果传递 —no-overwrite 选项,则不会覆盖具有相同名称的现有配置文件。
查看配置
执行以下命令,查看cephadm当前管理的所有配置文件:
1 | ceph orch tuned-profile ls |
要进行修改并重新应用配置文件,请将 --format yaml 传递给 tuned-profile ls 命令。 tuned-profile ls --format yaml 命令以易于复制和重新应用的格式呈现配置文件。
删除配置文件
要删除以前应用的配置文件
1 | ceph orch tuned-profile rm <profile-name> |
删除配置文件后,cephadm 会清除之前写入 /etc/sysctl.d 的文件。
修改配置文件
可以通过重新应用与要修改的配置文件同名的 YAML 规范来修改配置文件,但可以使用以下命令调整现有配置文件中的设置。
要添加或修改现有配置文件中的设置:
1 | ceph orch tuned-profile add-setting <profile-name> <setting-name> <value> |
要从现有配置文件中删除设置:
1 | ceph orch tuned-profile rm-setting <profile-name> <setting-name> |
修改放置需要重新应用同名的配置文件。请记住,配置文件是通过其名称进行跟踪的,因此当应用与现有配置文件同名的配置文件时,它会覆盖旧的配置文件,除非传递 —no-overwrite 标志。
配置SSH
https://docs.ceph.com/en/quincy/cephadm/host-management/#ssh-configuration
配置主机名
服务与进程管理
服务是一组配置在一起的守护进程。
查看服务状态
命令行打印服务列表
1
2
3
4查看所有服务
ceph orch ls
打印 Orchestrator已知的服务列表
ceph orch ls [--service_type type] [--service_name name] [--export] [--format f] [--refresh]--host:限制仅打印指定主机上的服务--type:仅打印特定类型的服务(mon、osd、mgr、mds、rgw)
找到要检查其状态的服务
1
2
3查看指定服务
ceph orch ls alertmanager
ceph orch ls --service_name crash打印服务的状态
将已知的服务规范导出到 orchestrator
1 | ceph orch ls --export |
使用此命令导出的服务规范将导出为 yaml,并且该 yaml 可以与 ceph orch apply -i 命令一起使用。(见 服务规范)
1 | root@node01:~# ceph orch ls --host node01 --export |
查看进程状态
守护进程 是一个正在运行的 systemd 单元,是服务的一部分。
要查看守护程序的状态
打印 orchestrator已知的所有守护程序的列表
1
2
3
4
5
6其实可以通过docker ps查看,但是不太直观,所以既然有ceph命令,肯定是用ceph查看更为详细直观了。
ceph orch ps
ceph orch ps [--hostname host] [--daemon_type type] [--service_name name] [--daemon_id id] [--format f] [--refresh]
ceph orch ps --daemon-type osd
ceph orch ps --daemon-type [alertmanager|crash|grafana|mds|mgrmon|node-exporter|osd|prometheus|rgw]然后查询特定服务实例的状态(mon、osd、mds、rgw)。 对于 OSD,ID 是数字 OSD ID。对于 MDS 服务,id 是文件 系统名称:
1
ceph orch ps --daemon_type osd --daemon_id 0
节点启动服务
1 | # 查看节点 |
服务规范
>
服务规范是一种用于指定服务部署的数据结构。除了 placement 或 networks 等参数之外,用户还可以设置服务配置项的初始值。对于每个 参数配置项/参数值 ,cephadm使用以下指令设置其值
1 | ceph config set <service-name> <param> <value> |
如果在规范中发现无效的配置参数,cephadm 会发出健康警告CEPHADM_INVALID_CONFIG_OPTION ;如果尝试应用新配置选项时出现任何错误,会发出 CEPHADM_FAILED_SET_OPTION
YAML 格式的服务规范示例
1 | service_type: rgw |
https://docs.ceph.com/en/quincy/cephadm/services/#ceph.deployment.service_spec.ServiceSpec
服务规范的应用
多个服务规范能够通过一个 多-文档 yaml生效,运行 ceph orch apply -i 指令
1 | cat <<EOF | ceph orch apply -i - |
服务规范修改
如果服务已经通过 ceph orch apply… 启动,那么直接更改服务规范会很复杂。
我们建议按照以下说明导出正在运行的服务规范,而不是尝试直接更改服务规范:
1 | ceph orch ls --service-name rgw.<realm>.<zone> --export > rgw.<realm>.<zone>.yaml |
然后可以如上所述更改并重新应用规范。
更新服务规范
Ceph Orchestrator 在 ServiceSpec 中维护每个服务的声明状态。
对于某些操作,例如更新 RGW HTTP 端口,我们需要更新现有规范。
列出当前的
ServiceSpec:1
ceph orch ls --service_name=<service-name> --export > myservice.yaml
更新yaml服务规范文件:
1
vi myservice.yaml
应用新的
ServiceSpec:1
ceph orch apply -i myservice.yaml [--dry-run]
进程放置
为了让 orchestrator 部署服务,它需要知道在哪里部署守护进程以及部署多少个。这就是放置规范的作用。放置规范可以作为命令行参数或在 YAML 文件中传递。
cephadm 不会在带有
_no_schedule标签的主机上部署守护进程
apply指令不太容易理解,所以建议使用 YAML 格式的放置规范每个
ceph orch apply <service-name>命令都会取代之前的命令
2
3
ceph orch apply mon host2
ceph orch apply mon host3这导致只有一个主机应用了监视器:主机 3。第一个命令在 host1 上创建一个监视器。然后第二个命令破坏 host1 上的监视器并在 host2 上创建一个监视器。然后第三个命令破坏 host2 上的监视器并在 host3 上创建一个监视器。在这种情况下,此时,host3 上只有一个监视器。
为了确保将监视器应用于这三个主机中的每一台,请运行以下命令:
所以为了避免覆盖,使用yaml文件进行进程放置 (daemon placement)
2
3
4
5
6
placement:
hosts:
- host1
- host2
- host3
指定主机的进程放置
守护进程可以通过简单指定来明确地放置在主机上
1 | 明确地将 prometheus 服务放置在主机host1 host2 host3上 |
相应的 YAML 配置为
1
2
3
4
5
6service_type: prometheus
placement:
hosts:
- host1
- host2
- host3
1 | MON 和其他服务可能需要一些增强的网络规范 |
[v2:1.2.3.4:3300,v1:1.2.3.4:6789]是监视器的网络地址,并=name指定新监视器的名称。
按标签的进程放置
守护进程放置可以限制为与特定标签匹配的主机。
为主机指定标签
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16为 hostname 添加 mylabel 标签
ceph orch host label add *<hostname>* mylabel
要查看当前主机和标签,请运行以下命令:
ceph orch host ls
ceph orch host label add host1 mylabel
ceph orch host label add host2 mylabel
ceph orch host label add host3 mylabel
ceph orch host ls
HOST ADDR LABELS STATUS
host1 mylabel
host2 mylabel
host3 mylabel
host4
host5按标签部署守护进程
1
2通过运行以下命令告诉 cephadm 根据标签部署守护进程:
ceph orch apply prometheus --placement="label:mylabel"相应的 YAML
1
2
3service_type: prometheus
placement:
label: "mylabel"
按模式匹配的进程放置
更改守护进程的数量
通过指定count,将仅创建指定数量的守护进程:
1 | ceph orch apply prometheus --placement=3 |
要在主机子集上部署守护程序,请指定数量:
1 | 仅部署两个服务,所以仅选择两台主机部署 |
```yaml
service_type: prometheus
placement:
count: 31
2
3
4
5
如果数量大于主机数量,cephadm 将为每个主机部署一个:
```shell
ceph orch apply prometheus --placement="3 host1 host2"```yaml
service_type: prometheus
placement:
count: 2
hosts:- host1 - host2 - host31
2
3
4
5
6
7
8
9
10
### 守护进程共置
cephadm 支持在同一主机上部署多个守护进程
```yaml
service_type: rgw
placement:
label: rgw
count_per_host: 2
每个主机部署多个守护进程的主要原因是在同一主机上运行多个 RGW 和 MDS 守护进程可以获得额外的性能优势。
算法描述
Cephadm 不断将集群中 实际运行的守护进程列表 与 进程放置的服务规范列表 进行比较。Cephadm 会根据需要添加新守护进程并删除旧守护进程,以符合服务规范。
Cephadm 执行以下操作来保持符合服务规范。
- Cephadm 首先选择候选主机列表。Cephadm 会查找明确的主机名并选择它们。
- 如果 cephadm 未找到明确的主机名,它会查找标签规范。
- 如果规范中未定义标签,cephadm 会根据主机模式选择主机。
- 如果未定义主机模式,作为最后的手段,cephadm 会选择所有已知主机作为候选主机。
Cephadm 知道正在运行服务的现有守护进程并试图避免移动它们。
1 | service_type: mds |
- 该服务规范指示 cephadm 在整个集群中标记为
myfs的主机上部署三个守护进程。 - 如果候选主机上部署的守护程序少于三个,cephadm 会随机选择要部署新守护程序的主机
- 如果候选主机上部署的守护程序超过三个,cephadm 会删除现有守护程序。
- 最后,cephadm 删除候选主机列表之外的主机上的守护程序。
如果放置规范选择的主机数量少于 count 所需的数量,cephadm 将仅在选定的主机上部署。
额外的容器参数
https://docs.ceph.com/en/quincy/cephadm/services/#extra-container-arguments
额外的入口参数
https://docs.ceph.com/en/quincy/cephadm/services/#extra-entrypoint-arguments
自定义配置文件
https://docs.ceph.com/en/quincy/cephadm/services/#custom-config-files
Cephadm 支持为守护进程指定各种配置文件。为此,用户必须提供配置文件的内容以及守护进程容器内应挂载的位置。
在应用指定了自定义配置文件的 YAML 规范并让 cephadm 重新部署指定了配置文件的守护进程后,这些文件将在守护进程容器的指定位置挂载。
服务规范示例:
1 | service_type: grafana |
为了使这些新的配置文件真正挂载到守护进程的容器中
1 | ceph orch redeploy <service-name> |
删除服务
1 | ceph orch rm <service-name> |
禁用守护进程的自动部署
Cephadm 支持根据每个服务禁用守护进程的自动部署和删除。CLI 支持两个命令来实现此功能。
- 完全删除服务,见上节
要禁用守护进程的自动管理,请unmanaged=True在 服务规范(mgr.yaml)中设置。
mgr.yaml
1 | service_type: mgr |
1 | ceph orch apply -i mgr.yaml |
Cephadm 还支持使用 ceph orch set-unmanaged 和 ceph orch set-managed 命令将 unmanaged 参数设置为 true 或 false 。该命令采用服务名作为唯一参数(由 ceph orch ls 列出)
1 | 为mon服务的自动部署设置true |
在服务规范中应用此更改后,cephadm 将不再部署任何新的守护程序(即使放置规范与其他主机匹配)。
The “osd” service used to track OSDs that are not tied to any specific service spec is special and will always be marked unmanaged. Attempting to modify it with
ceph orch set-unmanagedorceph orch set-managedwill result in a messageNo service of name osd found. Check "ceph orch ls" for all known services
手动部署进程
在主机上手动部署守护进程
此工作流程的用例非常有限,只应在极少数情况下使用。
通过获取现有规范、添加
unmanaged: true并应用修改后的规范来修改服务的服务规范然后使用以下命令手动部署守护程序
1
2ceph orch daemon add <daemon-type> --placement=<placement spec>
ceph orch daemon add mgr --placement=my_host从服务规范中删除 unmanaged: true 将启用该服务的协调循环,并可能导致删除守护程序,具体取决于放置规范。
手动从主机中删除守护程序
1 | ceph orch daemon rm <daemon name>... [--force] |
MON服务
https://docs.ceph.com/en/quincy/cephadm/services/mon/
典型的 Ceph 集群有三到五个监视器守护进程,分布在不同主机上。如果集群中有五个或更多节点,我们建议部署五个监视器。
Ceph 会在集群增长时自动部署监视器守护进程,并在集群缩小时自动缩减监视器守护进程。此自动增长和收缩的顺利执行取决于正确的子网配置。
cephadm 引导程序将集群中的第一个监视器守护进程分配给特定子网。cephadm将该子网指定为集群的默认子网。除非 cephadm 被指示执行其他操作,否则新的监视器守护进程将默认分配给该子网。
如果集群中的所有 ceph 监视器守护进程都在同一个子网中,则无需手动管理 ceph 监视器守护进程。 cephadm当新主机添加到集群时,将根据需要自动向子网添加最多五个监视器。
为监视器指定特定子网
1 | ceph config set mon public_network *<mon-cidr-network>* |
Cephadm 仅在具有指定子网内的 IP 地址的主机上部署新的监视守护进程。
您还可以使用网络列表指定两个公共网络:
1 | ceph config set mon public_network *<mon-cidr-network1>,<mon-cidr-network2>* |
在特定网络上部署监视器
您可以明确指定每个监视器的 IP 地址或 CIDR 网络,并控制每个监视器所在的位置。
要禁用自动监视器部署,请运行以下命令:
1
ceph orch apply mon --unmanaged
要部署每个附加监视器:
1
ceph orch daemon add mon *<host1:ip-or-network1>
例如,要newhost1 使用 IP 地址 10.1.2.123 部署第二台监视器,并在网络newhost2 10.1.2.0/24 上部署第三台监视器进程,请运行以下命令:
1 | ceph orch apply mon --unmanaged |
现在,启用守护进程的自动放置
1 | ceph orch apply mon --placement="newhost1,newhost2,newhost3" --dry-run |
最后通过删除 —dry-run 应用这个新的放置
1 | ceph orch apply mon --placement="newhost1,newhost2,newhost3" |
将监视器移至不同网络
https://docs.ceph.com/en/quincy/cephadm/services/mon/#moving-monitors-to-a-different-network
设置显示器的CRUSH位置
MGR服务
https://docs.ceph.com/en/quincy/cephadm/services/mgr/
OSD服务
列出设备
ceph-volume 按顺序不时扫描群集中的每个主机,以确定存在哪些设备以及它们是否有资格用作 OSD
1 | 输出发现的设备列表 |
“Health”、“Ident”和“Fault”的字段。此信息由与libstoragemgmt的集成提供。默认情况下,此集成被禁用。(因为libstoragemgmt可能与您的硬件不 100% 兼容)。
尽管 libstoragemgmt库执行标准 SCSI 查询调用,但无法保证您的固件完全实现这些标准。这可能会导致某些较旧的硬件出现不稳定行为,甚至总线重置。因此,建议在启用此功能之前,先测试硬件与 libstoragemgmt 的兼容性,以避免服务意外中断。
有许多方法可以测试兼容性,最简单的方法是使用
cephadm shell直接调用libstoragemgmt
2
3
4
5
6
如果支持的话,应该有如下输出:
Path | SCSI VPD 0x83 | Link Type | Serial Number | Health Status
----------------------------------------------------------------------------
/dev/sda | 50000396082ba631 | SAS | 15P0A0R0FRD6 | Good
/dev/sdb | 50000396082bbbf9 | SAS | 15P0A0YFFRD6 | Good
要让cephadm包含这些字段,需要启用 device_enhanced_scan 选项。
1 | ceph config set mgr mgr/cephadm/device_enhanced_scan true |
在成功启用 libstoragemgmt 支持后,输出会如下
1 | ceph orch device ls |
- libstoragemgmt 已确认驱动器的运行状况以及与驱动器机箱上的标识和故障 LED 进行交互的能力。
- 当前版本的 libstoragemgmt (1.8.8) 仅支持基于 SCSI、SAS 和 SATA 的本地磁盘。没有对 NVMe 设备 (PCIe) 的官方支持
创建新的OSD
- 为了部署 OSD,必须有一个可用于部署 OSD 的存储设备。
ceph orch ls显示所有集群主机上的存储设备清单 - 如果满足以下所有条件,则认为存储设备可用 available :Ceph 不会在不可用的设备上配置 OSD。
- 该设备必须没有分区。
- 设备不得具有任何 LVM 状态。
- 不得安装该设备。
- 该设备不得包含文件系统。
- 设备不得包含 Ceph BlueStore OSD。 该设备必须大于 5 GB。
- 创建新的OSDs
使用任何可用和未使用的存储设备
1 | 如果将新磁盘添加到群集,它们将自动用于 创建新的 OSD。 |
这还意味着 ceph orch apply 命令后所有 available(例如通过切换)的驱动器将被自动找到并添加到集群中。
- 如果您向集群添加新磁盘,它们将自动用于创建新的 OSD。
- 如果删除 OSD 并清理 LVM 物理卷,将自动创建新的 OSD。
要禁用在可用设备上自动创建 OSD,请使用 unmanaged 参数:
1 | ceph orch apply osd --all-available-devices --unmanaged=true |
ceph orch apply 的默认行为会导致 cephadm 不断进行协调。这意味着 cephadm 一旦检测到新驱动器就会创建 OSD。
设置 unmanaged: True 将禁用 OSD 的创建。如果设置了unmanaged: True,即使应用新的OSD服务也不会发生任何事情。
ceph orch daemon add 创建 OSD,但不添加 OSD 服务。
指定主机上的特定设备创建OSD
1 | ceph orch daemon add osd *<host>*:*<device-path>* |
试运行,不是真正的执行
1 | --dry-run 标志使 orchestrator 呈现将要发生的情况的预览,而无需实际创建 OSD。 |
删除OSD
1 | ceph orch osd rm <osd_id(s)> [--replace] [--force] |
- 从集群中撤出所有归置组(PG)
- 从集群中删除无PG的OSD
1 | ## 1.停止osd进程 |
监控OSD删除的状态
1 | ceph orch osd rm status |
停止删除 OSD
1 | ceph orch osd rm stop <osd_id(s)> |
替换OSD
1 | ceph orch osd rm <osd_id(s)> --replace [--force] |
新的OSD将替换移除掉的OSD,要求新OSD必须创建在旧OSD相同的主机上
保留OSD ID
‘destroyed’ 标志用于确定哪些 OSD id 将在下一个 OSD 部署中重用。
https://docs.ceph.com/en/quincy/cephadm/services/osd/#replacing-an-osd
擦除设备
擦除 (zap) 设备以便可以重复使用。 zap 在远程主机上调用 ceph-volume zap。
1 | ceph orch device zap <hostname> <path> |
如果未设置 unmanaged 标志,cephadm 会自动部署与 OSDSpec 匹配的驱动器。
- 例如,如果您在创建 OSD 时使用 all-available-devices 选项,则当您 zap 设备时,cephadm Orchestrator 会自动在该设备中创建新的 OSD。
激活现有 OSD
如果重新安装主机的操作系统,则需要激活现有的 OSD。对于这种场景,cephadm 提供了一个包装器激活主机上的所有现有 OSD
1 | ceph cephadm osd activate <host>... |
OSD服务规范
https://docs.ceph.com/en/quincy/cephadm/services/osd/#advanced-osd-service-specifications
RGW服务
https://docs.ceph.com/en/quincy/cephadm/services/rgw/
MDS服务
https://docs.ceph.com/en/quincy/cephadm/services/mds/
NFS服务
https://docs.ceph.com/en/quincy/cephadm/services/nfs/
ISCSI服务
https://docs.ceph.com/en/quincy/cephadm/services/iscsi/
监控服务
Ceph Dashboard 使用 Prometheus、Grafana 和相关工具来存储和可视化有关集群利用率和性能的详细指标。
Ceph 用户有以下三种选择
- 让 cephadm 部署并配置这些服务。这是引导新集群时的默认设置,除非使用 —skip-monitoring-stack 选项。
- 手动部署和配置这些服务。建议在其环境中拥有现有 prometheus 服务的用户(以及 Ceph 与 Rook 在 Kubernetes 中运行的情况)使用此方法。
- 完全跳过监控堆栈。某些 Ceph 仪表板图表将不可用。
监控堆栈由 Prometheus、Prometheus exporters (Prometheus Module, Node exporter),Prometheus Alert Manager 和 Grafana 组成
Prometheus 的安全模型假定不受信任的用户可以访问 Prometheus HTTP 端点和日志。不受信任的用户可以访问数据库中包含的 Prometheus 收集的所有(元)数据,以及各种操作和调试信息。
然而,Prometheus 的 HTTP API 仅限于只读操作。无法使用 API 更改配置,并且机密不会暴露。此外,Prometheus 有一些内置措施来减轻拒绝服务攻击的影响。
使用 CEPHADM 部署监控服务
cephadm 默认会部署一个基本监控堆栈。
对于没有监控堆栈的Ceph集群,如果想向其中添加监控堆栈(您可能在安装集群期间传递了 --skip-monitoring stack ,或者您可能已将现有集群(没有监控堆栈)转换为 cephadm 管理)
在集群的每个节点上部署 node-exporter 服务。node-exporter 提供主机级指标,例如 CPU 和内存利用率:
1
ceph orch apply node-exporter
部署 alertmanager
1
ceph orch apply alertmanager
部署 Prometheus ,单个 Prometheus 实例就足够了,但为了实现高可用性 (HA),您可能需要部署两个
1
2ceph orch apply prometheus
ceph orch apply prometheus --placement 'count:2'部署 grafana
1
ceph orch apply grafana
Ceph 中的集中日志记录
https://docs.ceph.com/en/quincy/cephadm/services/monitoring/#centralized-logging-in-ceph
集中日志管理 (Centralized Log Management , CLM) 整合所有日志数据并将其推送到中央存储库,并具有可访问且易于使用的界面。
Ceph 中的集中日志记录是使用两个新服务实现的 loki 和 promtail。Ceph 集群中默认不部署这两个服务。
- Loki:它基本上是一个日志聚合系统,用于查询日志。它可以在 Grafana 中配置为数据源。
- Promtail:它充当代理,从系统收集日志并将其提供给 Loki。
监控服务的网络和端口
所有监控服务都可以使用 yaml 服务规范配置其绑定的网络和端口
1 | service_type: grafana |
服务组件的镜像
https://docs.ceph.com/en/quincy/cephadm/services/monitoring/#default-images
默认镜像
自定义镜像
自定义配置文件
https://docs.ceph.com/en/quincy/cephadm/services/monitoring/#using-custom-configuration-files
不适用cephadm部署监控服务
如果您有现有的 prometheus 监控基础设施,或者想要自己管理它,则需要对其进行配置以与您的 Ceph 集群集成。
在 ceph-mgr 守护进程中启用 prometheus 模块
1
ceph mgr module enable prometheus
默认情况下,ceph-mgr 会在运行 ceph-mgr 守护进程的每个主机上的端口 9283 上显示 prometheus 指标。配置 prometheus 以抓取这些指标。
禁用监控服务
1 | ceph orch rm grafana |
监控服务的一些设置
SNMP服务
https://docs.ceph.com/en/quincy/cephadm/services/snmp-gateway/
Cephadm操作
查看cephadm日志消息
Cephadm 将日志写入cephadm集群日志通道。可以通过读取日志来实时监控 Ceph 的活动
1 | ceph -W cephadm |
默认情况下,此命令显示 info 级别以上的事件。要查看调试级别消息以及信息级别事件
1 | ceph config set mgr mgr/cephadm/log_to_cluster_level debug |
调试消息非常详细!
您可以通过运行以下命令查看最近事件:
1 | ceph log last cephadm |
这些事件也被记录到 monitor 主机上的 ceph.cephadm.log 和 stderr 上
进程控制
启动和停止守护进程
1 | ceph orch daemon stop <name> |
也可以启动或停止服务
1 | ceph orch stop <name> |
重新部署或重新配置守护程序
可以使用 redeploy 命令停止、重新创建和重新启动守护程序的容器:
1 | ceph orch daemon redeploy <name> [--image <image>] |
可以提供容器镜像名以强制使用特定镜像(而不是由 container_image 配置值指定的镜像)
如果只需要重新生成 ceph 配置,您还可以发出 reconfig 命令,该命令将重写 ceph.conf 文件,但不会触发守护进程的重新启动。
1 | ceph orch daemon reconfig <name> |
轮换守护进程的身份验证密钥
集群中的所有 Ceph 和网关守护进程都有一个密钥,用于连接到集群并进行身份验证。在需要更新密钥时,使用以下命令(密钥轮换):
1 | ceph orch daemon rotate-key <name> |
对于 MDS、OSD 和 MGR 守护程序,这不需要重新启动守护程序。然而,对于其他守护进程(例如,RGW),可以重新启动守护进程以切换到新密钥。
Ceph 守护进程日志
记录到 journald
Ceph日志由容器运行时环境捕获,可以通过 journalctl 访问
Ceph 守护进程在旧版本上将日志写入 /var/log/ceph,新版本默认将日志记录到journald。
- 在 Quincy 之前,ceph 守护进程记录到 stderr。
- 可以通过在引导新集群期间传递
–log-to-file来更改默认值。
记录到JOURNALD的示例
例如,要查看 ID 为 5c5a50ae-272a-455d-99e9-32c6a013e694 的集群的守护进程 mon.foo 的日志,命令将类似于:
1 | journalctl -u ceph-5c5a50ae-272a-455d-99e9-32c6a013e694@mon.foo |
当日志记录级别较低时,这对于正常操作非常有效。
记录到文件
如果您希望日志出现在文件中(就像在早期的 Cephadm 之前、Octopus 之前的 Ceph 版本中所做的那样),您还可以将 Ceph 守护进程配置为记录到文件而不是日志中。
当 Ceph 记录到文件时,日志出现在 /var/log/ceph/
如果您选择将 Ceph 配置为记录到文件而不是记录到日志,请记住配置 Ceph,以便它不会记录到journald(下面介绍了相关命令)。
1 | ceph config set global log_to_file true |
修改日志保留计划
默认情况下,cephadm 在每个主机上设置日志轮换( rotation)以轮换这些文件。
您可以通过修改 /etc/logrotate.d/ceph.
数据位置
数据与日志存储位置
Cephadm 将守护程序数据和日志存储在与旧版 ceph 不同的位置,(ceph Octopus版之前的ceph版本)
- /var/log/ceph/
目录,包含集群的所有日志。默认情况下,cephadm 通过 stderr 和容器运行时记录日志。除非您按照 cephadm-logs 中的说明启用了基于文件的日志记录,否则这些日志将不存在。 - /var/lib/ceph/
目录,包含所有集群守护进程数据(日志除外)。 - /var/lib/ceph/
/ 包含单个守护进程的所有数据。 - /var/lib/ceph/
/crash 包含集群的崩溃报告。 - /var/lib/ceph/
/removed 包含已被 cephadm 删除的有状态守护进程(例如监视器、prometheus)的旧守护进程数据目录。
磁盘使用情况
由于一些 Ceph 守护进程(特别是监视器和 prometheus)在 /var/lib/ceph 中存储大量数据,我们建议将此目录移至其自己的磁盘、分区或逻辑卷,以便它不会填满 root 文件系统
健康检查
cephadm 模块提供额外的健康检查来补充集群提供的默认健康检查,额外的健康检查分为两类
- cephadm 操作:当cecphadm模块处于 active 状态时,此类别的健康检查始终执行。
- 集群配置:这些健康检查是可选的,重点关注集群中主机的配置。
cephadm的健康状态
CEPHADM_PAUSED
这表明 cephadm 后台工作已因 ceph orch pause 而暂停。 Cephadm 继续执行被动监控活动(例如检查主机和守护进程状态),但不会进行任何更改(例如部署或删除守护进程)。
通过运行以下命令恢复 cephadm 工作
1 | ceph orch resume |
CEPHADM_STRAY_HOST
这表明一台或多台主机有正在运行的 Ceph 守护进程,但未注册为 cephadm 管理的主机。
这意味着这些服务当前无法由 cephadm 管理(例如,重新启动、升级、包含在 ceph orch ps 中)。
您可以通过运行以下命令来管理主机:
1
ceph orch host add *<hostname>*
或者,您可以手动连接到主机并确保该主机上的服务已删除或迁移到由 cephadm 管理的主机。
可以通过运行以下命令完全禁用此警告
1
ceph config set mgr mgr/cephadm/warn_on_stray_hosts false
CEPHADM_STRAY_DAEMON
一个或多个 Ceph 守护进程正在运行,但不受 cephadm 管理。
这可能是因为它们是使用不同的工具部署的,或者是因为它们是手动启动的,所以这些服务当前无法由 cephadm 管理(例如,重新启动、升级或包含在 ceph orch ps 中)
- 如果守护进程是有状态的(监视器或 OSD),则应由 cephadm 采用;请参阅 将现有集群转换为 cephadm。
- 对于无状态守护进程,通常最简单的方法是使用 ceph orch apply 命令配置新守护进程,然后停止非托管守护进程。
如果杂散守护进程在不受 cephadm 管理的主机上运行,您可以通过运行以下命令来管理主机:
1 | ceph orch host add *<hostname>* |
可以通过运行以下命令完全禁用此警告:
1 | ceph config set mgr mgr/cephadm/warn_on_stray_daemons false |
CEPHADM_HOST_CHECK_FAILED
一台或多台主机未通过基本 cephadm 主机检查,
- 主机可访问并且可以在那里执行 cephadm
- 主机满足基本先决条件,例如工作容器运行时(podman 或 docker)和工作时间同步。
如果此测试失败,cephadm 将无法管理该主机上的服务。
您可以通过运行以下命令手动运行此检查:
1 | ceph cephadm check-host *<hostname>* |
您可以通过运行以下命令将损坏的主机从管理中删除:
1 | ceph orch host rm *<hostname>* |
您可以通过运行以下命令来禁用此健康警告:
1 | ceph config set mgr mgr/cephadm/warn_on_failed_host_check false |
集群配置检查
Cephadm 定期扫描集群中的每个主机,以了解操作系统、磁盘、网络接口等的状态。然后可以分析该信息以确保集群中主机之间的一致性,以识别任何配置异常。
启动集群配置检查
集群配置检查是可选功能,可以通过运行以下命令来启用:
1 | ceph config set mgr mgr/cephadm/config_checks_enabled true |
集群配置检查返回的状态
每次主机扫描后都会触发配置检查。 cephadm 日志条目将显示配置检查的当前状态和结果,如下所示:
Disabled state (config_checks_enabled false):
1
ALL cephadm checks are disabled, use 'ceph config set mgr mgr/cephadm/config_checks_enabled true' to enable
Enabled state (config_checks_enabled true):
1
CEPHADM 8/8 checks enabled and executed (0 bypassed, 0 disabled). No issues detected
管理配置检查(子命令)
配置检查本身是通过多个 cephadm 子命令进行管理的。
确定是否启用配置检查
1 | ceph cephadm config-check status |
列出所有配置检查及其当前状态
1 | ceph cephadm config-check ls |
每个配置检查的名称可用于通过运行以下形式的命令来启用或禁用特定检查:
1 | ceph cephadm config-check disable <name> |
各项检查的具体含义,见
- CEPHADM_CHECK_KERNEL_LSM
- CEPHADM_CHECK_SUBSCRIPTION
- CEPHADM_CHECK_PUBLIC_MEMBERSHIP
- CEPHADM_CHECK_MTU
- CEPHADM_CHECK_LINKSPEED
- CEPHADM_CHECK_NETWORK_MISSING
- CEPHADM_CHECK_CEPH_RELEASE
- CEPHADM_CHECK_KERNEL_VERSION
客户端密钥环和配置
Cephadm 可以将 ceph.conf 文件和客户端密钥环文件的副本分发到主机。
从版本 16.2.10 (Pacific) 和 17.2.1 (Quincy) 开始,除了默认位置 /etc/ceph/ cephadm 还将配置和密钥环文件存储在 /var/lib/ceph/
/config 目录中。 通常最好在用于通过 CLI 管理集群的所有主机上存储 config 和 client.admin 密钥环的副本。
默认情况下,cephadm 会对任何具有 _admin 标签的节点(通常包括引导主机)执行此操作
Ceph 守护进程仍将使用 /etc/ceph/ 上的文件。新配置位置 /var/lib/ceph/
/config 仅由 cephadm 使用。将此配置目录放在 fsid 下有助于 cephadm 加载与集群关联的配置。
当 client.keyring 受到管理时,cephadm
- 根据指定的放置规范构建目标主机列表
- 在指定主机上存储 /etc/ceph/ceph.conf 文件的副本
- 在 /var/lib/ceph/
/config/ceph.conf 下存储 ceph.conf 副本 - 在 /var/lib/ceph/
/config/ceph.client.admin.keyring 下存储ceph.client.admin.keyring 副本 - 在指定主机上存储 keyring 文件的副本
- 根据需要更新
ceph.conf文件(例如,由于集群监视器的变化) - 如果实体的密钥发生更改(例如通过命令),则更新密钥环文件
ceph auth ... - 确保密钥环文件具有指定的所有权和指定的模式
- 当客户端密钥环管理被禁用时删除密钥环文件
- 如果密钥环放置规范已更新,则从旧主机中删除密钥环文件(根据需要)
列出客户端密钥环
1 | ceph orch client-keyring ls |
将 KEYRING 置于管理之下
1 | ceph orch client-keyring set <entity> <placement> [--mode=<mode>] [--owner=<uid>.<gid>] [--path=<path>] |
- 默认情况下,路径为
/etc/ceph/client.{entity}.keyring,这是 Ceph 默认查找的位置。指定备用位置时要小心,因为现有文件可能会被覆盖。 - (所有主机)的放置
*很常见。 - 模式默认为
0600,所有权默认为0:0(用户根,组根)
例如,要创建一个client.rbd密钥并将其部署到具有 rbd-client 标签的主机,并使其可由 uid/gid 107(qemu)读取,请运行以下命令:
1 | ceph auth get-or-create-key client.rbd mon 'profile rbd' mgr 'profile rbd' osd 'profile rbd pool=my_rbd_pool' |
禁用密钥环文件的管理
1 | ceph orch client-keyring rm <entity> |
这将删除之前写入集群节点的该实体的所有密钥环文件。
/ETC/CEPH/CEPH.CONF
将 Ceph.CONF 分发到没有密钥环的主机
>
将 ceph.conf 文件分发到没有关联客户端密钥环文件的主机。默认情况下,cephadm 仅将 ceph.conf 文件部署到有 client-keyring 的主机(参见上文)。
1 | 要将配置文件写入没有 client_keyring 的主机,请运行以下命令: |
使用放置规范指定哪些主机获取密钥环
默认情况下,配置会写入所有主机(即 ceph orch host ls 列出的主机)。要指定哪些主机获取 ceph.conf,请运行以下形式的命令:
1 | ceph config set mgr mgr/cephadm/manage_etc_ceph_ceph_conf_hosts <placement spec> |
将 Ceph.CONF 分发到标记为 BARE_CONFIG 的主机
1 | ceph config set mgr mgr/cephadm/manage_etc_ceph_ceph_conf_hosts label:bare_config |
创建集群
1 | cephadm bootstrap --mon-ip 192.168.192.156 --allow-overwrite |
销毁集群
为了销毁集群并删除该集群中存储的所有数据,请禁用 cephadm 以停止所有编排操作(这样我们就可以避免部署新的守护进程)。
1 | ceph mgr module disable cephadm |
然后验证集群的 FSID:
1 | ceph fsid |
从集群中的所有主机中清除 ceph 守护进程
每台主机执行
1 | ceph fsid |
已有集群迁移到Cephadm
可以转换一些现有集群,以便使用 cephadm 进行管理,适用于使用ceph-deploy、ceph-ansible、DeepSea 部署的一些集群
- Cephadm 仅适用于 BlueStore OSD。集群中的 FileStore OSD 无法使用cephadm 进行管理
准备
确保
cephadm现有集群中的每个主机上都有命令行工具。请参阅安装 cephadm以了解如何操作。cephadm通过在每个主机上运行以下命令来准备使用每个主机:1
cephadm prepare-host
选择要用于转换的 Ceph 版本。此过程适用于任何 Ceph 版本,即 Octopus(15.2.z)或更高版本。默认为 Ceph 的最新稳定版本。
使用以下命令将 Ceph 容器映像传递给 cephadm:
1
cephadm --image $IMAGE <rest of command goes here>
转换开始。
通过运行并确保守护进程的样式已更改来确认转换正在进行:
cephadm ls在开始转换前,
cephadm ls报告所有具有legacy样式的现有守护进程,随着采用过程的进栈,采用的守护进程以cephadm:v1风格呈现
迁移流程
确保 ceph 配置迁移 为使用集群的中央配置数据库。
如果所有主机上的 /etc/ceph/ceph.conf 都相同,则可以在一台主机上运行以下命令,并对所有主机生效:
1
ceph config assimilate-conf -i /etc/ceph/ceph.conf
如果主机之间存在配置差异,您将需要在每个主机上重复此命令
- 注意,如果主机之间的选项设置存在冲突,则将使用最后一个主机的值
在此采用过程中,通过运行以下命令查看集群的中央配置以确认其完整:
1
ceph config dump
监视器的迁移
1
cephadm adopt --style legacy --name mon.<hostname>
每个旧版 Monitor 将停止,作为 cephadm 容器快速重新启动,然后重新加入仲裁。
管理器的迁移
1
cephadm adopt --style legacy --name mgr.<hostname>
ceph服务的迁移
1
2ceph mgr module enable cephadm
ceph orch set backend cephadm为cephadm生成SSH密钥
1
2ceph cephadm generate-key
ceph cephadm get-pub-key > ~/ceph.pub在集群中的每个主机上安装 cephadm SSH 密钥
1
ssh-copy-id -f -i ~/ceph.pub root@<host>
还可以导入现有的 SSH 密钥。SSH errors
还可以安排 cephadm 使用非 root 用户通过 SSH 访问集群主机。该用户需要具有无密码 sudo 访问权限。使用 ceph cephadm set-user
并将 SSH 密钥复制到每个主机上该用户的主目录。 Configuring a different SSH user 告诉 cephadm 要管理哪些主机
1
ceph orch host add <hostname> [ip-address]
在添加每个主机之前,运行
cephadm check-host。此检查可确保主机正常运行。建议使用 IP 地址参数。如果未提供地址,则将通过 DNS 解析主机名。验证所采用的监视器和管理器守护进程是否可见:
1
ceph orch ps
迁移集群中所有的OSD
1
2
3
4cephadm adopt --style legacy --name <name>
cephadm adopt --style legacy --name osd.1
cephadm adopt --style legacy --name osd.2通过告诉 cephadm 为每个文件系统运行多少个守护进程来重新部署 CephFS MDS 守护进程(如果已部署)。
使用命令 ceph fs ls 按名称列出 CephFS 文件系统。在主节点上运行以下命令以重新部署 MDS 守护程序:
1
ceph orch apply mds <fs-name> [--placement=<placement>]
例如,在具有名为 foo 的单个文件系统的集群中:
1
2
3
4ceph fs ls
name: foo, metadata pool: foo_metadata, data pools: [foo_data ]
ceph orch apply mds foo 2最后,停止并删除旧的 MDS 守护进程:
1
2systemctl stop ceph-mds.target
rm -rf /var/lib/ceph/mds/ceph-*重新部署 Ceph 对象网关 RGW 守护进程(如果已部署)。
Cephadm 按区域管理 RGW 守护进程。对于每个区域,使用 cephadm 部署新的 RGW 守护进程:
1
ceph orch apply rgw <svc_id> [--realm=<realm>] [--zone=<zone>] [--port=<port>] [--ssl] [--placement=<placement>]
其中
可以是简单的守护进程计数,也可以是特定主机的列表(请参阅守护进程放置)。仅多站点设置需要区域和领域参数。 守护程序启动并且您确认它们正在运行后,停止并删除旧守护程序:
1
2systemctl stop ceph-rgw.target
rm -rf /var/lib/ceph/radosgw/ceph-*检查命令 ceph health detail 的输出,了解有关杂散集群守护进程或尚未由 cephadm 管理的主机的 cephadm 警告。
Ceph升级
https://docs.ceph.com/en/quincy/cephadm/upgrade/
Cephadm 可以安全地将 Ceph 从一个小版本升级到下一个版本。
自动升级过程遵循 Ceph 最佳实践。
- 升级顺序从管理器开始,然后是监视器,最后是其他守护进程。
- 仅当 Ceph 指示集群将保持可用后,才会重新启动每个守护进程。
HEALTH_WARNINGCeph 集群健康状态很可能在升级过程中切换 。如果集群中某个主机离线,则升级将暂停。
启动升级
在使用 cephadm 升级 Ceph 之前,请通过运行以下命令验证所有主机当前均处于在线状态且集群运行正常:
1 | ceph -s |
要升级到特定版本,请运行以下形式的命令:
1 | ceph orch upgrade start --ceph-version <version> |
升级进度
- 升级是否正在进行中
- 集群要升级到哪个版本:
1 | ceph orch upgrade status |
在 CEPH 升级过程中查看进度条
1 | ceph -s |
在升级过程中查看 CEPHADM 日志
1 | ceph -W cephadm |
取消升级
1 | ceph orch upgrade stop |
升级cephadm
如果新版本基于cephadm,则升级完成后,用户必须将cephadm软件包(如果不适用 cephadm shell ,则更新 ceph-common 软件包)更新为与新版本兼容的版本。
潜在问题
https://docs.ceph.com/en/quincy/cephadm/upgrade/#potential-problems
Ceph 客户端的基本设置
客户端主机需要基本配置才能与 Ceph 集群交互。
大多数客户端主机只需要安装 ceph-common 包及其依赖项:此安装只提供基本的 ceph和rados 指令,也包括 mount.ceph 和 rbd
文件设置
客户端主机通常需要比后端集群主机更小的配置文件(configration files ,有时称为“config files”)。为生成最小的配置文件,登录已配置为客户端或正在运行集群守护程序的主机,然后运行以下命令
1 | ceph config generate-minimal-conf |
此命令生成一个最小的配置文件,告诉客户端如何访问 Ceph 监视器。通常应将此文件复制到每个客户端主机上的 /etc/ceph/ceph.conf。
keyring 设置
大多数 Ceph 集群在启用身份验证的情况下运行。这意味着客户端需要密钥才能与 Ceph 守护进程进行通信。
集群端密钥生成:要生成带有 client.fs 凭据的密钥环文件,请登录正在运行的集群成员并运行以下命令:
1
ceph auth get-or-create client.fs
生成的输出被定向到密钥环文件中 /etc/ceph/ceph.keyring
密钥的分发
要更广泛地了解客户端密钥环分发和管理,阅读 Client keyrings and configs 本文
故障排除
Cephadm 在容器内部署守护进程。排除容器化守护进程故障所需的过程与排除通过软件包安装的传统守护进程故障所需的过程不同。
如何调查
- cephadm 命令失败的原因
- 某项服务不再正常运行的原因
这里有一些工具和命令可以帮助您排除 Ceph 环境故障。
暂停或禁用 CEPHADM
如果出现问题并且 cephadm 行为异常,请运行以下命令暂停大部分 Ceph 集群的后台活动:
1 | 这会停止 Ceph 集群中的所有更改,但 cephadm 仍会定期检查主机以刷新其守护进程和设备清单。 |
通过运行以下命令完全禁用 cephadm:
1 | 这些命令将禁用所有ceph orch ... 的命令。 |
每个服务和每个守护进程的事件
cephadm 会按服务和守护进程存储事件。这些事件通常包含与 Ceph 集群故障排除相关的信息。
列出服务事件
查看与特定服务相关的事件
1 | ceph orch ls --service_name=<service-name> --format yaml |
返回以下形式的信息:
1 | service_type: alertmanager |
列出守护进程事件
查看与某个守护进程相关的事件
1 | ceph orch ps --service-name <service-name> --daemon-id <daemon-id> --format yaml |
返回以下形式的内容
1 | daemon_type: mds |
检查 CEPHADM 日志
参阅 https://docs.ceph.com/en/quincy/cephadm/operations/#watching-cephadm-logs
如果您的 Ceph 集群已配置为将事件记录到文件中,则所有监视器主机上都会有一个ceph.cephadm.log文件
获取日志
收集日志文件
使用journalctl收集所有守护进程的日志文件:
- 默认情况下,cephadm 现在将日志存储在journald 中。这意味着您将不再在 /var/log/ceph/ 中找到守护程序日志。
要读取一个特定守护程序的日志文件,请运行以下形式的命令:
1 | cephadm logs --name <name-of-daemon> |
仅在运行守护程序的同一主机上运行时,此功能才有效。
不同主机同种守护进程的日志
1
cephadm logs --fsid <fsid> --name <name-of-daemon>
同一主机不同守护进程的日志
1
2
3for name in $(cephadm ls | jq -r '.[].name') ; do
cephadm logs --fsid <fsid> --name "$name" > $name;
done
收集系统状态
要打印 systemd 单元的状态,请运行以下形式的命令:
1 | systemctl status "ceph-$(cephadm shell ceph fsid)@<service name>.service"; |
要获取给定主机的所有守护程序的状态,请运行以下 shell 脚本:
1 | fsid="$(cephadm shell ceph fsid)" |
列出所有下载的容器镜像
1 | podman ps -a --format json |
手动运行容器
Cephadm 在运行容器时使用小型包装器。容器执行命令请参考/var/lib/ceph/
SSH ERRORS
https://docs.ceph.com/en/quincy/cephadm/troubleshooting/#ssh-errors
FAILED TO INFER CIDR NETWORK ERROR
https://docs.ceph.com/en/quincy/cephadm/troubleshooting/#failed-to-infer-cidr-network-error
访问管理套接字
每个 Ceph 守护进程都提供一个管理套接字,允许运行时参数配置项的设置和统计信息读取。请参阅使用管理套接字。
要访问管理套接字,请进入主机上的守护程序容器:
1
[root@mon1 ~]# cephadm enter --name <daemon-name>
运行以下形式的命令来查看管理套接字的配置和其他可用操作:
1
2[ceph: root@mon1 /]# ceph --admin-daemon /var/run/ceph/ceph-<daemon-name>.asok config show
[ceph: root@mon1 /]# ceph --admin-daemon /var/run/ceph/ceph-<daemon-name>.asok help
运行各种 CEPH 工具
https://docs.ceph.com/en/quincy/cephadm/troubleshooting/#running-various-ceph-tools
恢复监视器仲裁
如果 Ceph Monitor 守护进程(mons)无法形成法定人数,cephadm则将无法管理集群,直到法定人数恢复。
为了恢复法定人数,请按照以下步骤从 monmap 中删除不健康的监视器:
停止所有监视器。使用
ssh连接到每个监视器的主机,然后在连接到监视器的主机时使用cephadm停止监视器守护程序:1
2ssh {mon-host}
cephadm unit --name {mon.hostname} stop找到一个存活的监控器并登录到其主机:
1
2ssh {mon-host}
cephadm enter --name {mon.hostname}按照 从不健康的集群中删除监视器 中的步骤进行操作
手动部署 MANAGER 守护进程
cephadm 需要至少一个 Manager ( mgr) 守护进程来管理集群。如果最后一个剩余的 Manager 已从 Ceph 集群中删除,请按照以下步骤在集群中的任意主机上部署新的 Manager。
禁用 cephadm 调度程序,以防止
cephadm删除新的管理器。1
ceph config-key set mgr/cephadm/pause true
检索或创建新 mgr 的“auth entry”
1
ceph auth get-or-create mgr.hostname.smfvfd mon "profile mgr" osd "allow *" mds "allow *"
检索监视器的配置:
1
ceph config generate-minimal-conf
检索容器镜像
1
ceph config get "mgr.hostname.smfvfd" container_image
创建一个名为 的文件
config-json.json,其中包含部署守护进程所需的信息1
2
3
4{
"config": "# minimal ceph.conf for 8255263a-a97e-4934-822c-00bfe029b28f\n[global]\n\tfsid = 8255263a-a97e-4934-822c-00bfe029b28f\n\tmon_host = [v2:192.168.0.1:40483/0,v1:192.168.0.1:40484/0]\n",
"keyring": "[mgr.hostname.smfvfd]\n\tkey = V2VyIGRhcyBsaWVzdCBpc3QgZG9vZi4=\n"
}部署 Manager 守护进程:
1
cephadm --image <container-image> deploy --fsid <fsid> --name mgr.hostname.smfvfd --config-json config-json.json
CAPTURING CORE DUMPS
https://docs.ceph.com/en/quincy/cephadm/troubleshooting/#capturing-core-dumps
使用 CEPHADM 运行调试器
https://docs.ceph.com/en/quincy/cephadm/troubleshooting/#running-the-debugger-with-cephadm