- Vim编辑器
- GNU(第二代Shell)——BASH Shell
- Bash功能:指令管理、记录、文件或命令补全、环境变量的使用
- 数据流重导向——正则表达式与文件格式化处理
- Shell脚本
3.1 Vim
在Linux不同的发行版中,有不同的系统管理工具
- Red Hat Enterprise Linux 与Fedora 的ntsysv 与setup 等
- SuSE 则有YAST 管理工具
Linux中,绝大部分的配置文件都是以ASCII纯文本的形式保存,因此使用文本编辑工具也可以完成系统配置与管理等工作
常见的文本编辑工具有:emacs、pico、nano、joe与vim等
- 通用性:所有类Unix的系统都会内置vi文本编辑器,其他编辑器不一定存在
- 支持编程:vim具有程序编辑能力,能通过字体颜色辨识语法正确性
vim为vi编辑器的进阶版,vim会依据文件扩展名或文件开头的信息,识别程序的类型,进而调用相应的语法判断程序,再以颜色来区分程序代码
3.1.1 Vi的使用
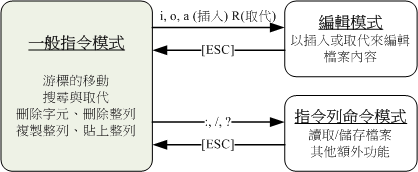
一般指令模式(command mode):
内容调整模式
使用vi打开一个文件,默认为一般模式
可以进行跳转、搜索与取代、删除(单个字符、整行)、复制、粘贴等功能
编辑模式:
在一般模式中,键入
i(I)、a(A)、o(O)、r(R)插入或取代文件的内容
指令行模式(command-line mode):
文件编辑
在一般模式中,键入
:、/、?读取或删除文件内容,支持其他额外的功能
编辑模式与指令行模式不能互相切换
1 | /bin/vi [文件名] |
3.1.2 按键说明
数字,通常表示重复做几次操作,也代表去到第几个
一般指令模式(内容调整模式)
跳转
| 分类 | 按键 | 结果 |
|---|---|---|
| 光标移一字符 | ||
| \ | 光标左移一字符 | |
| \ | 光标下移一字符 | |
| \ | 光标上移一字符 | |
| \ | 光标右移一字符 | |
| 光标移动多字符 | ||
| n \ | n表示数字,表示向右移动n个字符 | |
| \<0\>或\ | 移动到当前行的最前面一个字符 | |
| \<$>或\ | 移动到当前行的最后一个字符 | |
| 移动一行 | ||
| + | 光标移动到非空格符的下一行 | |
| - | 光标移动到非空格符的上一行 | |
| n \ | n表示数字, 光标向下移动n行 | |
| 移动到一屏内指定行 | ||
| \ | 移动到当前一屏的最上方一个行的第一个字符 | |
| \ | 移动到当前一屏的中央一个行的第一个字符 | |
| \ | 移动到当前一屏的最下方一个行的第一个字符 | |
| 移动到指定行 | ||
| \ | 移动到本文件的第一行,相当于1G | |
| n\ | n为数字,表示移动到这个文件的第n行 | |
| \ | 移动到当前文件的最后一行 | |
| 光标跳转一屏 | ||
| \ | 向下移一屏,相当于 \ | |
| \ | 向上移一屏,相当于 \ | |
| \ | 向下移半屏 | |
| \ | 向上移半屏 |
搜索与替换
| 分类 | 按键 | 说明 |
|---|---|---|
| 搜索 | ||
| \</>[word] | 在光标之下搜索关键词word | |
| \<?>[word] | 在光标之上搜索关键词word | |
| \ | 在搜索完成后,按\ | |
| \ | 反方向重复前一个搜索动作 | |
| 替换 | ||
| \<:>[n1]\<,>[n2]\ | 在n1行与n2行之间,搜索word1,并将其替换为word2 | |
| \<:>\<1\>\<,>\<$>\ | 从第1行到最后一行,搜索word1,并将其替换为word2 | |
| \<:>\<1\>\<,>\<$>\ | 从第1行到最后一行,搜索word1,并将其替换为word2,在替换前让用户确认 |
删除、复制、粘贴
| 分类 | 按键 | 说明 |
|---|---|---|
| 删除 | ||
| \ | x为向后删除一字符,相当于\ X为向前删除一字符,相当于\ | |
| [n]\ | 向后连续删除n个字符 | |
| \ | 删除光标所在位置,到该行最后一个字符 | |
| \ | 删除光标所在位置,到该行第一个字符 | |
| \ | 删除光标所在行 | |
| [n]\ | 删除光标所在行的向下n行 | |
| \ | 删除光标所在行,到第一行的所有数据 | |
| \ | 删除光标所在行,到最后一行的所有数据 | |
| 复制 | ||
| \ | 复制光标处字符到当前行的第一个字符 | |
| \ | 复制光标处字符到当前行的最后一个字符 | |
| \ | 复制光标所在的行 | |
| [n]\ | 复制光标所在的向下几行 | |
| \ | 复制光标所在到第一行的所有数据 | |
| \ | 复制光标所在行到最后一行的所有数据 | |
| 粘贴 | ||
| \ | 将已复制的数据粘贴到光标的下一行 | |
| \ | 将已复制的数据粘贴到光标的上一行 | |
| 合并 | ||
| \ | 将光标所在行与下一行的数据合并到同一行 | |
| \ | 重复删除多个数据,10\ |
重复与撤销的操作
| 按键 | 说明 | |
|---|---|---|
| \ | 撤销上一个操作 | |
| \ | 重复上一个操作 | |
| \<.> | 重复上一个操作 |
内容调整模式切换到内容编辑模式
| 模式 | 按键 | 说明 |
|---|---|---|
| 进入插入模式 | ||
| \,\ | i表示从当前光标所在处插入 I表示从当前光标所在的第一个非空格字符插入 | |
| \,\ | a表示从当前光标所在的下一个字符处追加 A表示从当前光标所在行的最后一个处追加 | |
| \ | o表示在当前光标所在的下一行插入新的一行 O表示在当前光标所在的上一行插入新的一行 | |
| 进入取代模式 | ||
| \ | r表示只会取代光标所在的那个字符 R表示一直取代光标所在的字符,直至按下ESC | |
| 退出到内容调整模式 | ||
| ESC |
内容调整模式切换到文件编辑模式
| 分类 | 按键 | 说明 |
|---|---|---|
| 退出 | ||
| \<:>\ | 将文件内容写入硬盘 | |
| \<:>\ | 强制写入 | |
| \<:>\ | 退出 | |
| \<:>\ | 修改过文件,不保存,强制退出 | |
| \<:>\ | 保存后离开 | |
| \<:>\ | 强制保存后离开 | |
| ZZ | 若未修改文件,则不保存退出;若修改过文件,则保存后退出 | |
| \ | 退出,vim放到后台执行 | |
| 另存为 | ||
| \<:>\ | 将数据另存为一个文档 | |
| \<:>n1,n2 w [文件名] | 将n1到n2的内容保存为文件名指定的文件 | |
| 从其他文件读入 | ||
| \<:>\ | 将文件名指定的数据添加到光标所在行的后面 | |
| 离开文件执行指令 | ||
| \<:> command | 暂时退出vim,显示command的执行结果 | |
| 行号 | ||
| :set nu | 显示行号 | |
| :set nonu | 取消行号 |
3.1.3 Vim的功能说明
vim的暂存文件
vim在被编辑文件的同级目录下,新建 .filename.swp 的临时文件
出现暂存文件的两种情况:
- 其他人也在编辑当前文件
- vim 异常退出
存在暂存文件情况下,有六个可用按键
- [O]pen Read-Only:以只读文件的形式打开文件
- [E]dit anyway:以读写形式打开,不载入暂存文件
- [R]ecover:加载暂存文件内容,退出后,还需要手动删除暂存文件
- [D]elete:删除暂存文件
- [Q]uit:退出vim,不进行任何操作
- [A]bort:忽略编辑
颜色显示功能
相较vi,vim具有颜色显示功能,且支持许多的程序语法,便于进行调试
1 | [dmtsai@study ~]$ alias |
区块选择
分区块选择与对区块操作两部分
| 分类 | 按键 | 说明 |
|---|---|---|
| 区块选择 | ||
| v | 按下v后,选择将光标经过的地方 | |
| V | 按下V后,将光标经过的地方反选 | |
| Ctrl+v | 随光标移动,以矩形方式选择 | |
| 对区块的操作 | ||
| y | 复制选中的区块 | |
| d | 删除选中的区块 | |
| p | 在光标处,粘贴选中的区块 |
多文件编辑
vim是独立的,不支持跨vim窗口进行复制与粘贴,即不能再A文件nyy,再到B文件p
利用vim跨文件复制、粘贴:
1 | 1. 利用vim 打开需要使用的两个文件 |
多窗口
| 按键 | 说明 |
|---|---|
| :sp [文件名] | 开启新窗口,若不加文件名,则新窗口打开同名文件 |
| \ \ | 先按下 [ctrl] 不放, 再按下 w 后放开所有的按键,然后再按下 j (或向下箭头键),则光标可移动到下方的窗口。 |
| \ \ | 先按下 [ctrl] 不放, 再按下 w 后放开所有的按键,然后再按下 k (或向上箭头键),则光标可移动到下方的窗口。 |
| \ | 关闭当前窗口 |
代码补全
| 按键 | 说明 |
|---|---|
| Ctrl+x,Ctrl+n | 参照当前文件的【前文内容】为关键字,进行补全 |
| Ctrl+x,Ctrl+f | 参照当前文件所在目录的【文件名】为关键字,进行补全 |
| Ctrl+x,ctrl+o | 以当前文件扩展名对应的关键字为依据,以vim内置的关键字进行补全 |
vim环境设置与记录
vim会将曾经的操作记录下来,这些操作被记录到 ~/.viminfo ,
在一般指令模式中,输入 :set all ,可以获取vim的环境设置参数
| 按键 | 说明 | ||
|---|---|---|---|
:set nu:set nonu | 设置与取消行号 | ||
:set hlsearch:set nothlsearch | 高亮搜索,将关键词高亮 | ||
:set autoindent:set noautoindent | 自动缩进 | ||
:set backup | 设置自动备份,原始文件被复制为 filename~ | ||
:set ruler | 是否显示右下角状态说明 | ||
:set showmode | 是否显示左下角状态说明 | ||
| `:set backspace=(0 | 1 | 2)` | 对于有些distrobution,backspace不可删除任意字符,此时, backspace设置为2,表示可以删除任意值 backspace设置为0或1,表示金科删除刚输入的值 |
:set all | 显示所有环境参数的设置值 | ||
:set | 显示与系统默认值不同的设定值 | ||
:syntax on:syntax off | 是否根据语法显示不同颜色 | ||
:set bg=dark:set bg=light | 修改背景色 |
~/.vimrc 中记录了一些环境设置,格式如下
1 | dmtsai@study ~]$ vim ~/.vimrc |
编码转换与中文编码
编码转换
iconv 可将进行文本的编码格式转换
1 | iconv --list 可列出iconv支持的语系编码格式 |
| 选项 | 参数 | 含义 |
|---|---|---|
| -f | 原本的编码格式 | |
| -t | 转换后的编码格式 | |
| -o | filename | 若要保留原始文件,则-o 指定新编码格式的文件存为filename |
中文编码
对于中文编码,存在big5与utf8两种,出现乱码时,需要考虑:
Linux默认支持的语系,在 /etc/locale.conf中
bash的语系,与
LANG,LC_ALL这几个环境变量有关1
2LANG=zh_TW.big5
export LC_ALL=zh_TW.big5文本原始的编码格式
开启终端的软件
在Linux中,tty1~tty6默认不支持中文编码。
DOS与Linux的换行符
cat -A 可以查看文件内容中的特殊字符
DOS中,使用的换行符为 ^M$,称为 CR(回车)与LF(换行)两个符号,表示为 \r
Linux中,换行符为 LF,即LF,表示为 $
在Linux下,指令开始执行的依据是回车,回车为LF符号
DOS换行为CRLF,因此在DOS写的shell脚本,直接移植到Linux中,可能无法执行
使用 dos2unix 指令,可以将shell脚本中的,CRLF转换为LF,
1 | dos2unix [-kn] file [newfile] |
| 选项 | 参数 | 含义 |
|---|---|---|
| -k | 保留mtime时间格式 | |
| -n | 保留原始文件,将转换后的内容输出到新文件 |
1 | [dmtsai@study vitest]$ ll man_db.conf |
1 | dmtsai@study vitest]$ dos2unix -k -n man_db.conf man_db.conf.linux |
3.2 Bash
3.2.1 Shell与Bash Shell
硬件<—>内核<—>应用程序(Shell)
用户通过Shell输入指令,Shell将输入的指令发送给内核,内核控制硬件工作
操作系统包含内核层与Shell层,控制计算机系统的硬件,并管理系统的活动检测
Shell是操作系统提供用户控制计算机整个软硬件系统的接口
Shell包括指令行、图形接口之类的软件,包括bash等
Shell分类与查看
Shell:Bourne Shell(sh)、C Shell(csh,Sun BSD版 Unix)、K Shell 等,
Linux中使用 Bourne Again Shell——bash,基于GNU架构发展出来
当前Linux系统合法的Shell,要写入 /etc/shell
shell配置文件:系统某些服务在运行过程中,会检查使用者能够使用的shell‘
- FTP会去检查shell,若不想让FTP用户使用FTP之外的资源,会赋一些shell,让其无法登入主机,如 /sbin/nologin
系统用户预设的shell在 /etc/passwd 中配置
1 | [dmtsai@study ~]$ cat /etc/passwd |
当登录到终端机(tty)后,Linux会依据 /etc/passwd 设定的shell分配一个shell进程,然后将指令下达给shell
Bash Shell功能
指令记录
在 ~/.bash_history 中记录上次登录所执行的指令,本次登录所执行的指令都暂存于内存,仅当系统注销后,这些指令执行记录才会被记录到 .bash_history 中
指令与文件补全
若安装
bash-completion软件,则某些指令后[Tab] ,可进行 选项/参数 补全指令别名(alias)
1
alias lm='ls -al'
工作控制、前台控制、后台控制
shell脚本
支持通配符(wildcard)
Bash输入指令时的快捷键
| 快捷键 | 功能 |
|---|---|
| [CTRL]+u/[CTRL]+k | 从光标所在之前/之后删除指令 |
| [CTRL]+a/[CTRL]+e | 光标移动到指令行的最后或最前面 |
3.2.2 Shell中一些常用通配符与特殊符号
通配符
| 符号 | 含义 |
|---|---|
| * | 代表0到无穷多个任意字符 |
| ? | 代表一个任意字符 |
| [] | 代表括号范围内的一个字符 如[a,b,c] 代表三个字符中的一个 |
| [ - ] | 表示编码顺序内的所有字符 如,[0-9]表示0-9之间的所有数字 |
表示反向选择,[^a,b,c] 表示一定有一个字符,只要是非a,b,c都接受 |
特殊符号
| 符号 | 含义 | |
|---|---|---|
| # | 注释 | |
| \\ | 转移符号,将用特殊字符或通配符还原为一般符号 | |
| \ | 管道 | |
| ; | 连续指令下达分隔符, | |
| ~ | 家目录 | |
| $ | 取变量符 | |
| & | 任务控制,将前台任务变为后台任务 | |
| ! | 逻辑非 | |
| / | 目录符号 | |
| >,>> | 输出数据流重定向 | |
| <,<< | 输入数据流重定向 | |
| ‘’ | 特殊符号变为普通字符 | |
| “” | 保存特殊符号的含义 | |
| `` | 指令执行符,与 $() 等价 | |
| () | 子shell的开始与结束 | |
| {} | 中间部分为命令的组合 |
3.2.3 Shell中一些常用指令
区分Bash指令与外部指令
1 | 查看name指令是bash内置指令还是外部指令 |
| 选项 | 参数 | 含义 |
|---|---|---|
| -t | 输出指令类型 - file:外部指令 - alias:该指令为指令别名所设的名称 - builtin:bash内置指令 | |
| -p | 若为外部指令,显示完整路径 | |
| -a | 在PATH定义的路径中,将所有含name的指令列出 |
1 | 范例一:查询一下 ls 这个指令是否为 bash 内建? |
显示登录用户的信息
1 | [dmtsai@study ~]$ last |
与文件系统及程序的限制(ulimit)
通过 ulimit 限制用户的某些系统资源,包括可以开启的文件数量,可以使用的CPU时间以及可占用的内存等
1 | ulimit [-SHacdfltu] [配额] |
| 选项 | 参数 | 含义 |
|---|---|---|
| -H | 配额 | 严格限定,必定不超过这个设定值(hard limit) |
| -S | 配额 | 警告限定,可以超过,但超过设定值会有警告信息(soft limit) - 通常,soft会设定小于hard |
| -a | 后面不接任何选项或参数,可列出所有限制的配额 | |
| -c | 配额 | 当某些程序发生错误时,系统可能会将程序在内存中的信息写为文件(核心文件,core file),用于排错 - -c 后的配额限制每个核心文件的最大容量 |
| -f | 配额 | shell可以创建的最大文件容量,单位为KB |
| -d | 配额 | 程序可使用的最大段内存容量 |
| -l | 配额 | 用于锁定(lock)的内存容量 |
| -t | 配额 | 可使用的最大CPU时间(单位为秒) |
| -u | 配额 | 单一用户可以使用的最大进程数 |
1 | 列出你目前身份(假设为一般账号)的所有限制数据数值 |
对于设置的配额,只有注销并重新登入当前shell,才能取消配额
命令别名
1 | alias [别名]='指令 选项...' |
相当于创建一个指令
查看已有别名(常用别名)
1 | [dmtsai@study ~]$ alias |
取消设置别名
1 | unalias [别名] |
historty
查看历史执行指令的记录
当以bash登入linux后,系统会从 ~/.bash_history 中读取最近下达的指令
注销时,将最近的
HISTFILESIZE条历史命令,记录到 ~/.bash_history 中~/.bash_history 中,最多可记录
HISTFILESIZE条历史指令
1 | history [-nc] |
| 选项 | 参数 | 含义 |
|---|---|---|
| -n | 列出最近的n行记录 记录数量与 HISTFILESIZE 环境变量有关 | |
| -c | 将目前shell内所有的history 删除 | |
| -a | histfiles(可选) | 将目前新增的history 记录到 histfiles 中,若未接histfiles,则记录到 ~/.bash_history |
| -r | histfiles | 将histfiles中的内容读到history中 |
| -w | histfiles(可选) | 将history的内容写入到 histfiles中,默认会写入 ~/.bash_history |
利用history执行指令
1 | 执行第几条历史指令 |
同一账号多重登录的history写入问题
同一账号,打开多个bash,~/.bash_history 以最后注销的bash 的更新为主
无法历史记录指令执行时间
虽然历史指令依序号记录,但没有记录时间
因此,可以通过 ~./bash_log 进行history 的记录,并加上date来记录时间
1 | vim /etc/bashrc |
字符转换指令
tr-字符替代与删除
删除标准输入中的字符串,或替换文本信息
替换
1 | 将a-z替换为A-Z |
删除
1 | tr [-ds] pattens ... |
col-tab转空格
[Tab]以 ^I 表示,
1 | col [-xb] |
expand-tab转空格
1 | expand -t 文件路径 |
unexpand-空格转tab
多文件处理
paste-同行粘贴
两个文件中,有公共部分的行,将其粘贴为一行
1 | paste [-d] file1 file2 |
1 | 用 root 身份,将 /etc/passwd 与 /etc/shadow 同一行贴在一起 |
join-同行合并
两个文件中,有关键字的行,将其合并为一行
join之前,所处理的文件实现要经过排序(sort)处理
1 | join [-tri] 分隔符 file1 file2 |
| 选项 | 参数 | 含义 |
|---|---|---|
| -t | 分隔符 | 默认以空格分隔数据,对比第一个字段的数据, 若两个文件相同,将两笔数据合并,第一个字段放到行首 |
| -i | 忽略大小写差异 | |
| -1/2 | 关键字的域id | 第一/二个文件的关键字,由关键字域id指定 |
/etc/passwd 中记录的信息为账号、UID、GID、bash路径,/etc/shadow记录账号、账号密文,/etc/group记录GID,因此这三个文件有关联行
1 | 用 root 的身份,将 /etc/passwd 与 /etc/shadow 相关数据整合成一栏 |
1 | /etc/passwd 第4个域是GID,GID记录在 /etc/group中,可以合并 |
split-文件分片
根据文件大小或行数分片
1 | [dmtsai@study ~]$ split [-bl] file PREFIX |
1 | 范例一:我的 /etc/services 有六百多K,若想要分成 300K 一个文件时? |
1 | 范例三:使用 ls -al / 输出的信息中,每十行记录成一个文件 |
3.2.4 Shell 变量
变量:让一组特定文字或符号等,代表不固定的内容
作用:
同一变量,在不同用户下可赋不同的值
如:
mail指令主动取用MAIL变量,不同用户记录有不同的邮箱路径影响bash环境操作的环境变量
在Linux系统中,所有线程都需要一个指令名
只有登录Linux系统后,才能利用Shell对Linux进行操作
在进入Shell之前,需要利用环境变量,辅助系统进行数据的存取,或设定一些环境参数
环境变量通常都是大写,如PATH、HOME、Shell等
脚本程序中,利用变量提高效率
仅需修改变量定义的内容,即可调整整个脚本
变量的取用与设置
1 | 获取变量内容 |
规定:
等号两侧都不能直接接空格
1
2
3都错
myname = VBird
myname=VBird Tsai变量名只能是英文与数字,开头不能是数字
1
2myname=VBird
环境变量为大写字符,自定义变量为小写字符
转义符
\,将特殊字符(空格,回车,$,\,’等)变为一般字符
关于引号
双引号内的特殊字符(空格,回车,$,\
,’等),保留原本特性
1
2var="lang is $LANG"
echo $var <== lang is zh_TW.UTF-8单引号内的特殊字符,转换为纯文本
1
2var='lang is $LANG'
echo $var <== lang is $LANG指令内容含其他指令的执行结果
使用反单引号 `` 或 $ ,指令执行出来的结果将被作为外部的输入信息
1
2
3version=$(uname -r)
echo $version若扩充变量的内容,用
$变量名或${变量名}累加1
2
3
4
5PATH="$PATH":/home/bin
PATH=${PATH}:/home/bin
[变量名]="变量名"[扩充字符串]
[变量名]=${变量名}{扩充字符串}
1 | 指令是由左边向右找,先遇到的引号先有用,因此如上所示, 单引号变成一般字符! |
从键盘读取变量(read)
1 | read [选项] [变量名] |
| 选项 | 参数 | 含义 |
|---|---|---|
| -p | 接提示符 | |
| -t | 等待时长 |
1 | [dmtsai@study ~]$ read -p "Please keyin your name: " -t 30 named |
指定变量类型(declare)
1 | declare [-aixr] [变量名] |
| 选项 | 参数 | 含义 |
|---|---|---|
| -a | 将变量定义为数组类型 | |
| -i | 将变量定义为整数类型 | |
| -x | 将变量导出为环境变量 | |
| -r | 将变量变为只读类型 - 注销,再登入才能恢复变量 |
在默认情况下,bash 对于变量的基本定义
- 变量类型默认为字符串
- 变量的数值运算,只能到整数位
1 | 范例一:让变量 sum 进行 100+300+50 的加总结果 |
数组变量类型
1 | tzj@LAPTOP-070162A7:~$ declare -a var |
变量内容的删除、取代与替换
变量的删除与取代
| 变量设定方式 | 说明 | 作用 |
|---|---|---|
| ${变量#匹配模式} | 将变量内容从头到尾,符合匹配模式的最短数据删除 | 删除第一个匹配模式 |
| ${变量##匹配模式} | 将变量内容从头到尾,符合匹配模式的最长数据删除 | 保留尾部最后一个非匹配模式 |
| ${变量%匹配模式} | 将变量内容从尾到头,符合匹配模式的最短数据删除 | 删除最后一个匹配模式 |
| ${变量%%匹配模式} | 将变量内容从尾到头,符合匹配模式的最长数据删除 | 保留头部第一个非匹配模式 |
| ${变量/旧字符串/新字符串} | 若变量内容符合旧字符串,则第一个旧字符串会被新字符串替代 | |
| ${变量//旧字符串/新字符串} | 若变量内容符合旧字符串,则全部旧字符串会被新字符串替代 |
1 | [dmtsai@study ~]$ path=${PATH} |
变量内容的判断与替换
作用:判断变量是否已存在,进行替换或赋值
1 | # 若旧变量存在,则使用old_var赋值 |
| 指令 | old_var未设定 | old_var为空字符串 | old_var已设为非空字符串 |
|---|---|---|---|
| new_var=${old_var-content} | new_var=content | new_var=”” | new_var=${old_var} |
| new_var=${old_var:-content} | new_var=content | new_var=content | new_var=${old_var} |
| new_var=${old_var+content} | new_var=”” | new_var=content | new_var=content |
| new_var=${old_var:+content} | new_var=”” | new_var=”” | new_var=content |
| new_var=${old_var=content} | old_var=content new_var=content | old_var=”” new_var=”” | old_var不变 new_var=${old_var} |
| new_var=${old_var:=content} | old_var=content new_var=content | old_var=content new_var=content | old_var不变 new_var=${old_var} |
| new_var=${old_var?content} | content输出到stderr | new_var=”” | new_var=${old_var} |
| new_var=${old_var:?content} | content输出到stderr | content输出到stderr | new_var=${old_var} |
- 有无
:,仅会反转旧变量为空字符串的赋值 -模式:旧变量不存在,则新变量设为字符串;旧变量存在,则新新变量设为旧变量的值+模式:旧变量不存在,则新变量设为””;旧变量存在,则新变量设为字符串=模式:旧变变量不存在,则设定为字符串;旧变量存在,则新变量设为旧变量的值?模式:旧变量不存在,则输出错误;旧变量存在,则设为旧变量的值
环境变量
env 指令查看环境变量
env 或 export 都可以获取本机的环境变量,二者输出相同
常见的环境变量
HOME:用户家目录的路径
SHELL:当前环境使用的SHELL可执行文件的路径
HISTSIZE:记录的历史指令条数
MAIL:当前用户的邮箱目录
PATH:可执行文件的搜索路径,路径间用
:分隔,文件的搜索路径依序由PATH的变量内容查询LANG:语系数据
RANDOM:随机数变量,
echo $RANDOM,会调用随机数生成器 /dev/random 生成一个随机数并赋值给变量 ${RANDOM},变量取值介于 [0,32767]1
2declare -i number=$RANDOM*10/32768 ; echo $number
8 <==会随机取出 0~9 之间的数值PS1:设定提示字符格式
当
PS1=[\u@\h \W]\$时,命令行提示符为[dmtsai@study home]$- \d:显示完整日期格式,[星期 月 日]
- \H:显示完整主机名
- \h:仅显示主机名,第一个小数点之前的名字
- \t:显示时间,24小时制,[HH:MM:SS]
- \T:显示时间,12小时制,[HH:MM:SS]
- \A:显示时间,24小时制,[HH:MM]
- \@:显示时间,12小时制,[am/pm]
- \u:显示当前用户名
- \v:显示BASH的版本信息
- \w:完整的工作目录名称,由根目录写起,家目录用 ~ 代替
- \W:利用basename获取工作目录名
- \#:下达的第几条指令
- \$:提示字符,root用户则为 \#,普通用户为 $
$:表示当前Shell的PID
?:返回代表上个指令执行结果的代码
1
2
3
4
5
6
7
8
9
10[dmtsai@study ~]$ echo $SHELL
/bin/bash <==可顺利显示!没有错误!
[dmtsai@study ~]$ echo $?
0 <==因为没问题,所以回传值为 0
[dmtsai@study ~]$ 12name=VBird
bash: 12name=VBird: command not found... <==bash 返回指令执行有问题
[dmtsai@study ~]$ echo $?
127 <==因为有问题,回传错误代码(非为0)
错误代码回传值依据软件而有不同,我们可以利用这个代码来搜寻错误的原因喔!OSTYPE, HOSTTYPE, MACHTYPE:这些指令与主机硬件与内核等级相关
set指令获取全部变量
使用 set 指令可显示所有变量值
在Linux的预设情况中,使用{大写字母}定义环境变量
export获取/转换环境变量
子程序与父程序的概念:
登入linux并取得一个bash后,bash就是一个独立的程序,通过 程序标识符(PID) 识别这个程序,在该bash下达的所有指令,都是这个bash衍生出来的子程序
子程序会继承父程序的环境变量,但不继承自定义变量
通过 export [变量名] ,可将自定义变量转换为环境变量,因此当前Bash中定义的变量,可以在子程序中使用
1 | [dmtsai@study ~]$ name=VBird |
通过 export ,可以查看本机所有的环境变量
变量的作用范围
当启动一个shell,操作系统会为该Shell分配一块内存,该内存内的变量(环境变量+自定义变量)可以为子程序所用
若使用 export 变量名 可以将变量写入该内存
当加载另一个shell时(即启动子程序),父shell内存中的变量将被拷贝到子shell的内存区
影响显示结果的语系变量
通过 locale -a 可查看Linux支持的所有语系
- 实际是列出 /usr/lib/locale/ 目录中的语系文件
通过 locale 可查看与语系相关的环境变量,进而修改这些变量内容
- 在其他语系变量未设定情况下,
LANG与LC_ALL会取代其他变量的取值 - 系统默认的语系定义在 /ect/locale.conf 中
3.2.5 Bash Shell的操作环境
路径与指令搜索顺序
指令的搜索顺序:
- 以相对/绝对路径执行指令
- 由
alias找到该指令执行 - 由bash内置的指令执行
- 通过
${PATH}配置的路径,按顺序搜索指令执行
观察依据:
2
3
4
5
[dmtsai@study ~]$ type -a echo
echo is aliased to `echo -n'
echo is a shell builtin
echo is /usr/bin/echo
bash的登录提示信息
与 PS1 环境变量类似,通过预设模式的组合,在 /etc/issue 中配置bash shell的登入前的提示信息。
1 | vim /etc/issue |
| 转义字符 | 说明 |
|---|---|
| \d | 本地端时间的日期 |
| \l | 显示第几个终端机接口 |
| \m | 显示硬件的等级 (i386/i486/i586/i686…) |
| \n | 显示主机的网络名称 |
| \O | 显示 domain name |
| \r | 操作系统的版本 (相当于 uname -r) |
| \t | 显示本地端时间的时间; |
| \S | 操作系统的名称 |
| \v | 操作系统的版本 |
当使用telnet连接到主机时,会显示 /etc/issue.net 配置的信息
在 /etc/motd 中配置的信息,会在用户 登入后 显示提示信息
1 | [root@study ~]# vim /etc/motd |
| 特性 | /etc/issue | /etc/motd |
|---|---|---|
| 显示时机 | 用户登录前显示 | 用户登录后显示 |
| 显示对象 | 本地终端登录提示 | 所有登录用户(包括SSH) |
| 交互性 | 显示后等待输入用户名 | 显示后直接呈现shell提示符 |
| 动态变量 | 支持(如 \l, \n, \t) | 纯静态文本 |
| 网络登录 | 通常不显示给SSH(可配置) | SSH登录默认显示 |
bash的环境配置文件
bash在启动时,会读取bash的环境配置文件,以调整Bash的操作环境
- login shell:通过完整的登录流程获取bash shell,如登入tty1~tty6 时,需要输入用户名与密码
- no-login shell:获取 bash shell 时不需要重复登录
- 以X windows 登入后,再以图形化接口启动 bash shell,不需要再次输入账号用户密码
- 在原有bash shell中,再次下达bash指令
login shell 和 no-login shell 所读取的配置文件不同
login shell只会读取两个配置文件:
- /etc/profile :这是系统整体的设定,每个用户登入bash shell时,一定会读取的配置文件
- ~/.bash_profile 或 ~/.bash_login 或 ~/.profile :由登入用户设定
/etc/profile(只有login-shell会读)
基于用户的UID来决定环境变量,这个文件设置的主要变量有:
- PATH:会依据UID 决定PATH 变量要不要含有sbin 的系统指令目录
- MAIL:依据账号设定好使用者的mailbox 到/var/spool/mail/账号名
- USER:根据用户的账号设定此一变量内容
- HOSTNAME:依据主机的hostname 指令决定此一变量内容
- HISTSIZE:历史命令记录笔数。CentOS 7.x 设定为1000
- umask:包括root 默认为022 而一般用户为002 等
此外,还会调用外部设定的数据,如,CentOS 7.x 在默认情况下,会将以下脚本中的数据也调入
/etc/profile.d/\.sh :只要在 /etc/profile.d/ 目录中,且扩展名为 .sh* 的文件,且该文件具有 r 的权限,那么该文件就会被调用。
该目录中的脚本,规定bash操作接口的颜色、语系、ll、ls、vi、which等命令的别名
/etc/locale.conf:由 /etc/profile.d/lang.sh 调用,是决定bash预设使用何种语系的配置文件
/usr/share/bash-completion/completions/**:从这个目录里面找到相对应的指令,进行命令、文件名的补全,该目录下的内容由 /etc/profile.d/bash_completion.sh* 这个脚本载入
~/.bash_profile(只有login shell会读)
读取登录用户的个人配置文件
- 只读取一个用户配置文件,读取次序:
- ~/.bash_profile
- ~/.bash_login
- ~/.profile
1 | [dmtsai@study ~]$ cat ~/.bash_profile |
判断家目录下是否有 ~/.bashrc ,如果有,则读取该文件的配置
读入配置文件的指令为
source或.使用 export,扩展环境变量
~/.bashrc(login shell与no-login shell都会读)
定义出底下的数据
- 依据不同的UID 规范出umask 的值;
- 依据不同的UID 规范出提示字符(就是PS1 变量);
- 呼叫 /etc/profile.d/\.sh* 的设定
其他配置文件
/etc/man_db.conf :定义了 man page 的路径去哪找
- 若以tar包的形式安装,man page数据可能放在/usr/local/softpackage/man ,需要手动将路径加到配置文件中
~/.bash_history:记录历史指令,每次登录bash ,都会将所有历史指令读入内存
~/.bash_logout :记录当注销bash后,系统需要完成什么动作才会进入关机流程
tty终端的环境设置
在登录 tty1~tty6 这6个终端时,也会自动获取一些终端环境的设置
快捷键相关
stty(setting tty终端)可以设置在终端输入按键的含义
1 | 列出所有tty可配置的按键与按键内容 |
在vim 中,使用[CTRL+S],会让vim程序暂停,若要恢复输出,则需要重新启动vim,按[CTRL+Q]
在 /etc/inputrc 中可设置终端机的其他快捷键
- /etc/DIR_COLORS、/usr/share/terminfo/* 等文件也是与终端相关的配置文件
一些常用的快捷键
| 按键 | 执行结果 |
|---|---|
| CTRL+C | 终止当前指令 |
| CTRL+D | 输入EOF |
| CTRL+M | ENTER |
| CTRL+S | 终止屏幕输出 |
| CTRL+Q | 恢复屏幕输出 |
| CTRL+U | 提示字符下,将整行指令删除 |
| CTRL+Z | 暂停当前指令 |
指定指令的输入/输出环境
通过 set 指令的选项,可以配置指令执行的环境
| 选项 | 含义 |
|---|---|
| -u | 若未设置变量,则提示错误,默认不启用 |
| -v | 在信息被输出前,显示信息的原始内容,默认不启用 |
| -x | 指令被执行前,会显示指令内容,以 ++ 为前缀,默认不启用 |
| -h | 与历史指令有关,默认启用 |
| -H | 与历史指令有关,默认启用 |
| -m | 与任务管理相关,默认启用 |
| -B | 与中括号的作用相关,默认启用 |
| -C | 若使用 > 等,则若文件存在,则该文件不会被覆盖,默认不启用 |
1 | 显示所有环境变量 |
3.2.6 指令的连续执行
不相关指令的连续下达
; 分号前的指令执行完后,立即执行后续指令
1 | sync; sync; shutdown -h now |
相关指令的连续下达
| 指令模式 | 说明 | ||
|---|---|---|---|
cmd1 && cmd2 | 若cmd1执行完毕且正确($? 为0),则执行cmd2若cmd1执行完毕且错误( $? 不为0),则不执行cmd2 | ||
| `cmd1 | cmd2` | 若cmd1执行完毕且正确($?为0),则不执行cmd2若cmd1执行完毕且错误( $? 不为0),则执行cmd2 |
三目运算符,等价与if…else…
cmd1 && cmd2 || cmd3 :cmd1为判断语句,若成功,则执行cmd2;若失败,则执行cmd3
1 | 我不清楚 /tmp/abc 是否存在,但就是要建立 /tmp/abc/hehe 文件 |
3.2.7 数据流重导向
标准输入输出的重导向
指令执行时,可能会从文件读入数据,再将数据输出到屏幕上
一般情况,指令会从标准输入(standard input)读入数据,从标准输出(standard output)将数据输出,此外还有标准错误输出(standard error output, stderr)
标准输出:输出正确数据
标准错误输出:输出错误信息
在默认情况下,标准输入、标准输出、标准错误输出的数据流都导向屏幕
可以通过 数据流重导向 让这些数据分别输出到相应的文件或设备中
标准输入 (stdin):0,使用
<或<<标准输出 (stdout):1,使用
>或>>标准错误输出 (stderr):2,使用
2>或2>>
输出
> 覆盖写;>> 追加写。若文件不存在,则创建
1>:以覆盖写的方式,将正确的数据输出到指定的文件或设备上1>>:以追加写的方式,将正确的数据输出到指定的文件或设备上2>:以覆盖写的方式,将错误的数据输出到指定的文件或设备上2>>:以追加写的方式,将错误的数据出处到指定的文件或设备上
1 | [dmtsai@study ~]$ find /home -name .bashrc <==身份是 dmtsai 喔! |
/dev/null 为黑洞设备,不转存不需要的信息
将标准输出与标准错误输出重定向到同一个文件
1 | 若两个标准输出都指向同一个文件,则输出的信息回交叉写入,造成次序错乱。 |
输入
< 文件路径 表示用文件的内容代替键盘输入
<< 控制字符:控制字符表示输入结束的标识字符
1 | [dmtsai@study ~]$ cat > catfile << "eof" |
指令数据流的重导向(管道指令)
| 仅能处理前面一个指令传来的standard output的信息
- 管道指令后必须直接跟指令,这个指令必须能够接受standard input才行
- 会忽略standard error output
- 变通,让
2>&1,便可将标准错误输出重定向到管道后的指令
- 变通,让
关键词搜索
grep
取出搜索字符串所在的行
1 | grep [选项] --color=auto '搜索字符串' 文件名 |
| 选项 | 参数 | 含义 |
|---|---|---|
| -a | 将二进制文件以文本文件的形式搜搜 | |
| -c | 统计搜索字符串出现的次数 | |
| -i | 忽略大小写 | |
| -n | 输出行号 | |
| -v | 反向选择,输出不含搜索字符串的一行 |
1 | [dmtsai@study ~]$ grep --color=auto 'MANPATH' /etc/man_db.conf |
依分隔符将行数据处理
1 | cut -d '分隔符' -f 序号 |
| 选项 | 参数 | 含义 |
|---|---|---|
| -d | 分隔符 | |
| -f | 取出依-d分隔的第f段,取值方式,n可缺省 区间:[m,n] 范围:[m-n] | |
| -c | 以字符的单位取出固定字符区间 |
1 | [dmtsai@study ~]$ echo ${PATH} |
排序与筛选
sort 指令可以依据不同数据类型排序
- 数字类型与字符类型排序不同
- 排序结果与语系编码相关
1 | sort [-fbMnrtuk] [file or stdin] |
| 选项 | 参数 | 含义 |
|---|---|---|
| -f | 忽略大小写差异 | |
| -b | 忽略前置空格 | |
| -M | 以月份排序 | |
| -n | 使用纯数字排序(默认是文本) | |
| -r | 反向排序 | |
| -u | uniq,相同数据,仅出现一行代表 | |
| -t | 分隔符,预设用tab, 与-k结合,由-t定义的分隔符划分区间 | |
| -k | 以区间排序 |
1 | [dmtsai@study ~]$ cat /etc/passwd | sort -t ':' -k 3 |
去重
将文件或标准输入的内容去重,仅显示一个
1 | uniq [-ic] |
1 | tzj@LAPTOP-070162A7:~$ last |
统计
1 | wc [-lwm] |
| 选项 | 参数 | 含义 |
|---|---|---|
| -l | 仅列出行 | |
| -w | 列出word | |
| -m | 多少character |
1 | [dmtsai@study ~]$ cat /etc/man_db.conf | wc |
标准输入的数据分流
tee将数据同时分流到文件与屏幕
1 | tee -a file |
-的作用
如果需要 stdout/stdin 时,但偏偏又没有文件, - 就会被当成 stdin 或 stdout
1 | [root@study ~]# mkdir /tmp/homeback |
xargs
读取标准输入(stdin),以空格或换行符为分隔符,将标准输入的字符串作为参数
很多指令其实并不支持管道命令,因此我们可以透过xargs 来提供该指令引用标准输入
1 | [dmtsai@study ~]$ xargs [-0epn] command |
| 选项 | 参数 | 含义 |
|---|---|---|
| -0 | 若含特殊字符,如`、\空格等字符,将其还原为一般字符 | |
| -e | EOF,后接字符串,当xargs识别到这个字符串,则终止 | |
| -p | 执行每个指令的参数时,会询问调用者 | |
| -n | 次数 | 当command执行时,需要几个参数 |
1 | id指令,可以将账号对应的信息展示出来 |