前置知识:
- 地图查房
- 关键字搜索
前台
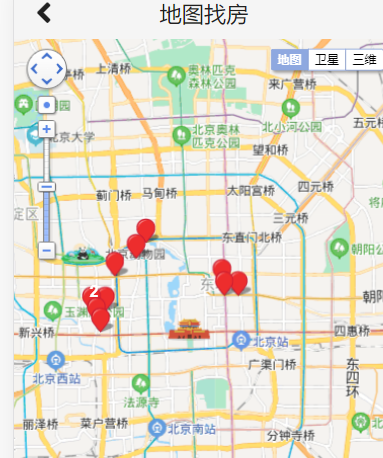
地图查房
文档:http://lbsyun.baidu.com/index.php?title=jspopular3.0
导入BMap
1 | <script type="text/javascript" src="https://api.map.baidu.com/api?v=3.0&ak=q60ejYQeO2qZO6dYhWPOHea4aY0bhrqG&s=1"></script> |
若在子模块直接使用BMap,会出现未定义的错误,原因是组件未加载
需要在 public/index.html 中,先将BMap和BMapLib载入到window
1 | <script type="text/javascript"> |
使用自定义OverFlowIcon
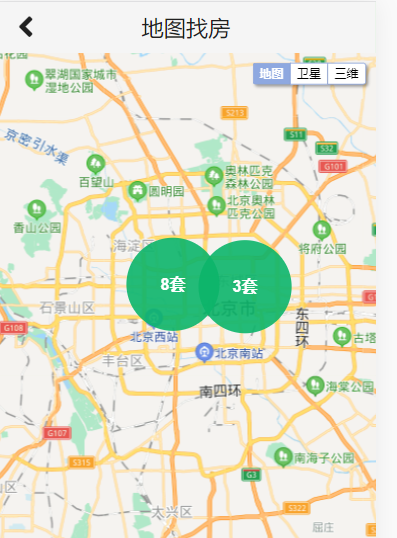
修改数据加载逻辑
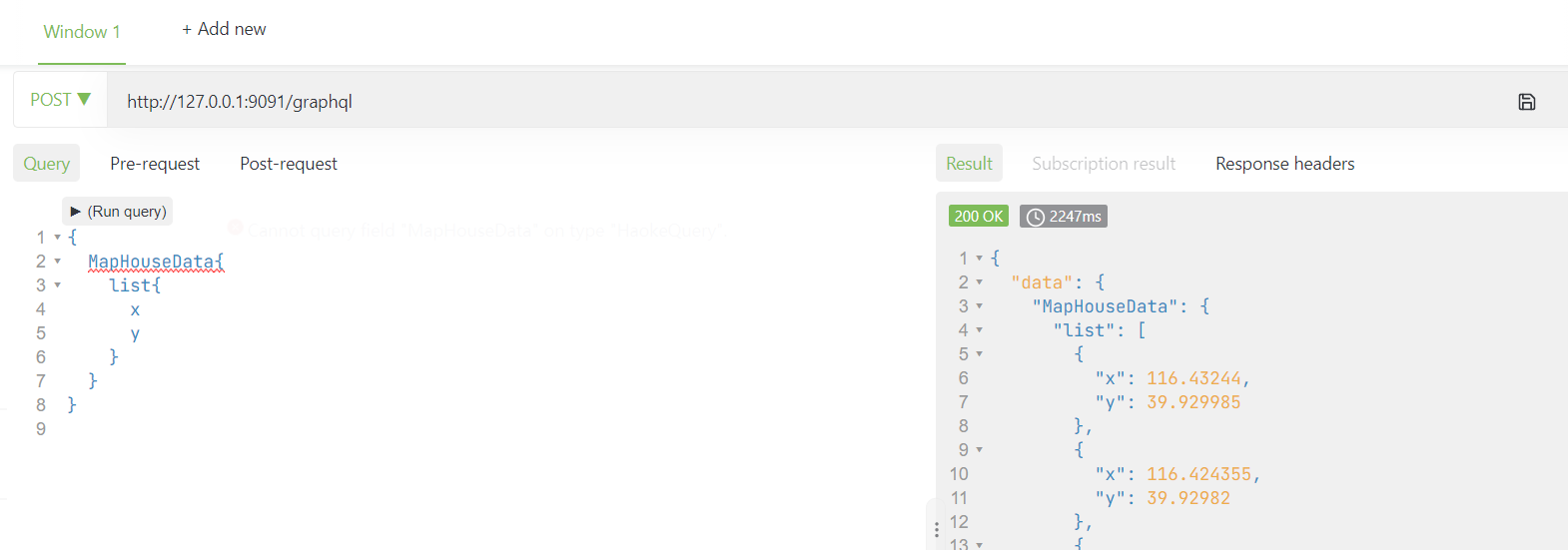
graphql接口
1 | schema { |
编写MapHouseDataResult、MapHouseXY
1 | package com.haoke.api.vo.map; |
1 | package com.haoke.api.vo.map; |
MapHouseDataFetcher Graphql接口
1 | package com.haoke.api.graphql.myDataFetcherImpl; |
测试Graphql接口
整合前端
1 | import { ApolloClient, gql , InMemoryCache} from '@apollo/client'; |
整合前端测试
测试后,数据是从后端传来的,则数据加载逻辑修改成功
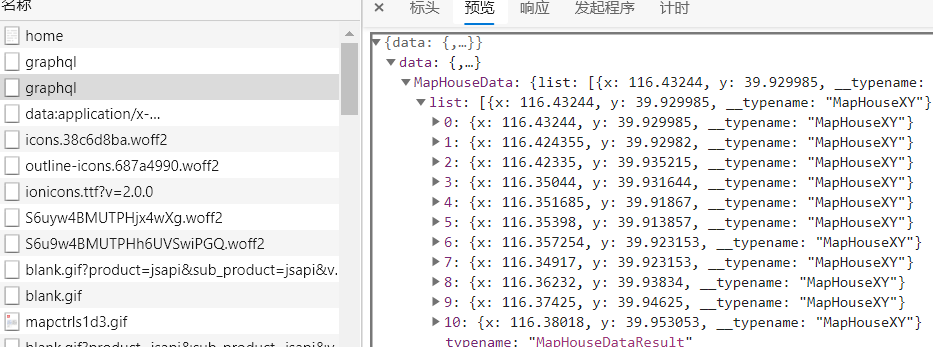
增加拖动事件
在地图拖动后,增加事件,获取中心位置的坐标,以便后续的查询
1 | map.addEventListener("dragend", function showInfo(){ |
百度地图缩放比例:
| 级别 | 比例尺 |
|---|---|
| 19级 | 20m |
| 18级 | 50m |
| 17级 | 100m |
| 16级 | 200m |
| 15级 | 500m |
| 14级 | 1km |
| 13级 | 2km |
| 12级 | 5km |
| 11级 | 10km |
| 10级 | 20km |
| 9级 | 25km |
| 8级 | 50km |
| 7级 | 100km |
| 6级 | 200km |
| 5级 | 500km |
| 4级 | 1000km |
| 3级 | 2000km |
| 2级 | 5000km |
| 1级 | 10000km |
传递经纬度和缩放比例参数
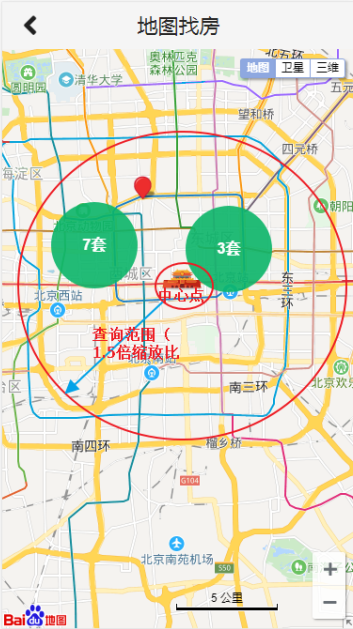
实现目标
拖动地图,更新范围内的房源数据
原理
- 拖动地图
- 获取地图中心点
- 将当前中心点的经纬度传及缩放比传递到后台
- 后台根据计算出的搜索范围,查询数据
实现
定义graphql接口
1 | type HaokeQuery{ |
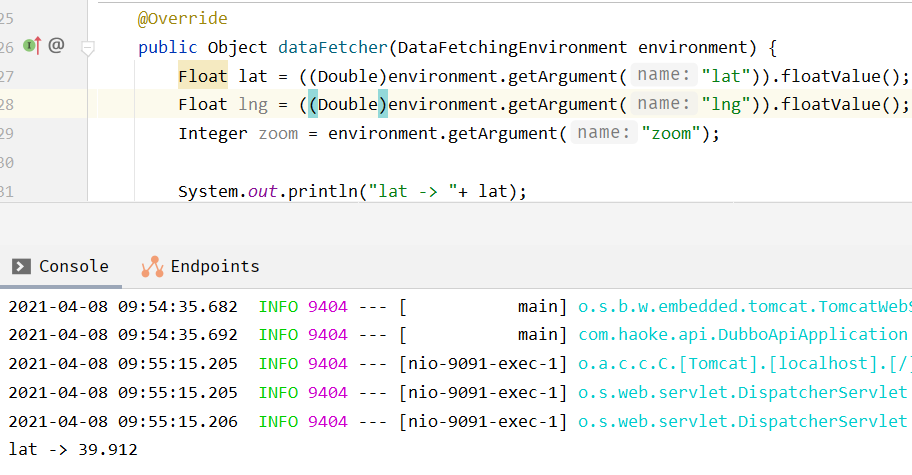
后台接口接收参数
1 | package com.haoke.api.graphql.myDataFetcherImpl; |
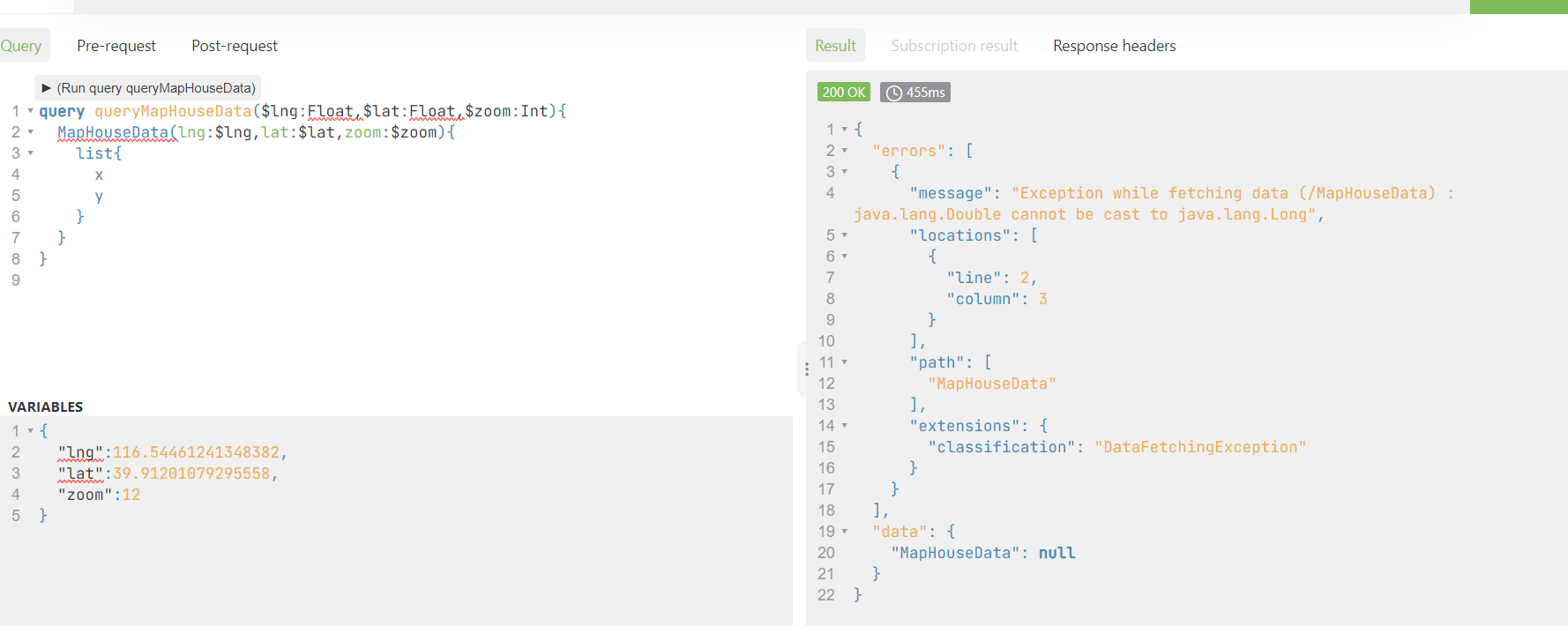
修改为
1 | Float lat = ((Double)environment.getArgument("lat")).floatValue(); |
前端代码修改
1 | import React from 'react'; |
MongoDB的地理位置索引
在MongoDB中,支持存储位置的经纬度,可以对其索引,通过算子操作,进行查找附近的数据,如:查找附近的人,附近的建筑
将房源数据导入到MongoDB
1 | ##进入容器 |
mongodb地理位置的索引
注意距离要除以111.2(1度=111.2km),跟普通查找的区别仅仅是多了两个算子 \$near 和 \$maxDistance
1 | 查询上海人民广场附近5公里的房源,人民广场的坐标为:121.48130241985999,31.235156971414239 |
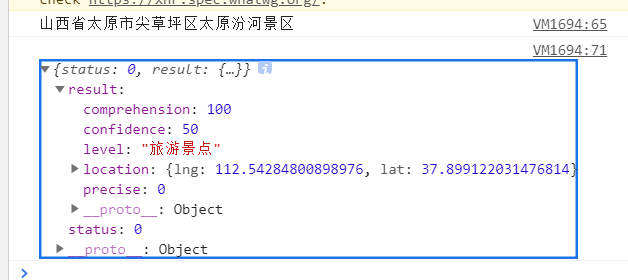
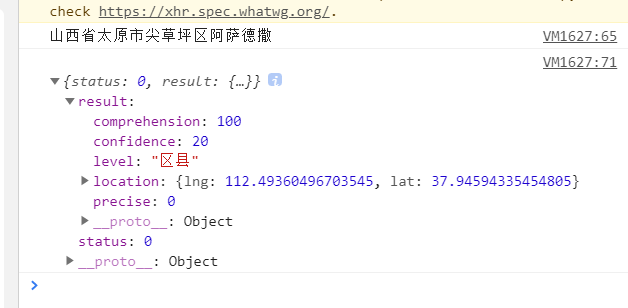
实现基于MongoDB的查询
mongo依赖
1 | <!--mongo依赖--> |
配置文件
1 | #mongodb配置 |
Mapper层代码
pojo
1 | package com.haoke.api.pojo; |
service
1 | package com.haoke.api.service; |
接口实现
1 | package com.haoke.api.graphql.myDataFetcherImpl; |
小程序用户登录
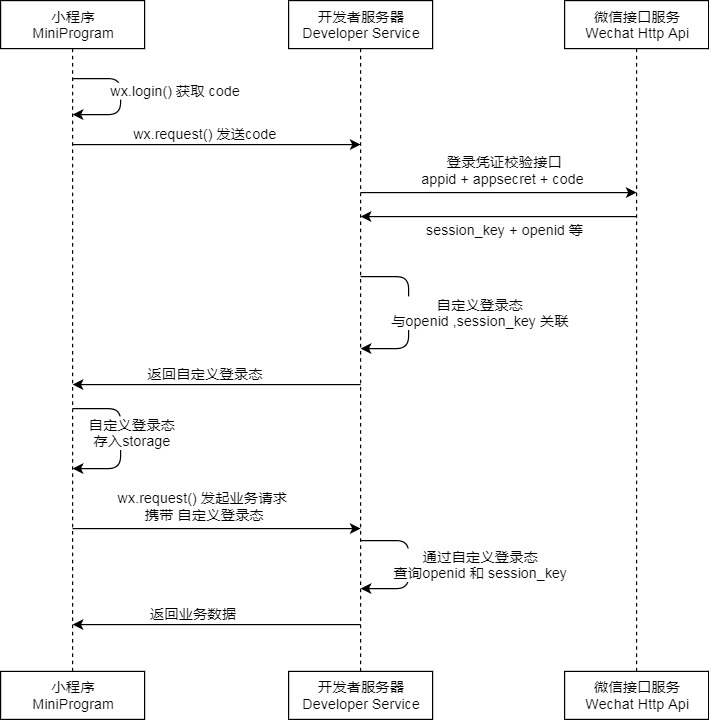
调用
wx.login()获取 临时登录凭证code ,并回传到开发者服务器wx.login()[https://developers.weixin.qq.com/miniprogram/dev/api/open-api/login/wx.login.html]
调用
code2Session接口,换取 用户唯一标识 OpenId 和 会话密钥 session_key用户在当前小程序的唯一标识(openid)
微信开放平台帐号下的唯一标识(unionid,若当前小程序已绑定到微信开放平台帐号)
- 本次登录的会话密钥(session_key)
注意
- 会话密钥
session_key是对用户数据进行 [加密签名][https://developers.weixin.qq.com/miniprogram/dev/framework/open-ability/signature.html] 的密钥。为了应用自身的数据安全,开发者服务器 不应该把会话密钥下发到小程序,也不应该对外提供这个密钥- 临时登录凭证 code 只能使用一次
编写登录服务
1. wx.login()获取code
1 | <view class="container"> |
2. 从微信服务器获取用户相关信息
请求微信的API地址[https://developers.weixin.qq.com/miniprogram/dev/api-backend/open-api/login/auth.code2Session.html]
1 | GET https://api.weixin.qq.com/sns/jscode2session? |
返回值示例
1 | { |
3. Bean——RestTemplate、JAVA的HTTP工具类
1 | package com.haoke.api.config; |
4. Controller
1 | package com.haoke.api.controller; |
5. session是否失效
wx.checkSession(Object object)
用户越久未使用小程序,用户登录态越有可能失效。反之如果用户一直在使用小程序,则用户登录态一直保持有效。
1 | checkLogin(){ |
6. 登录测试
1 | login(){ |
插件
wx-jq: wx-jq一套完全原创的微信小程序插件集合库,微信小程序插件,wx-jq (gitee.com)
WebMagic & 房源搜索
WebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。

- 简单的API,可快速上手
- 模块化的结构,可轻松扩展
- 提供多线程和分布式支持
使用WebMagic 抓取数据
0. 爬虫流程
访问列表页面,将当前列表页的房源详情页面添加到
list,作为待爬取页面列表页
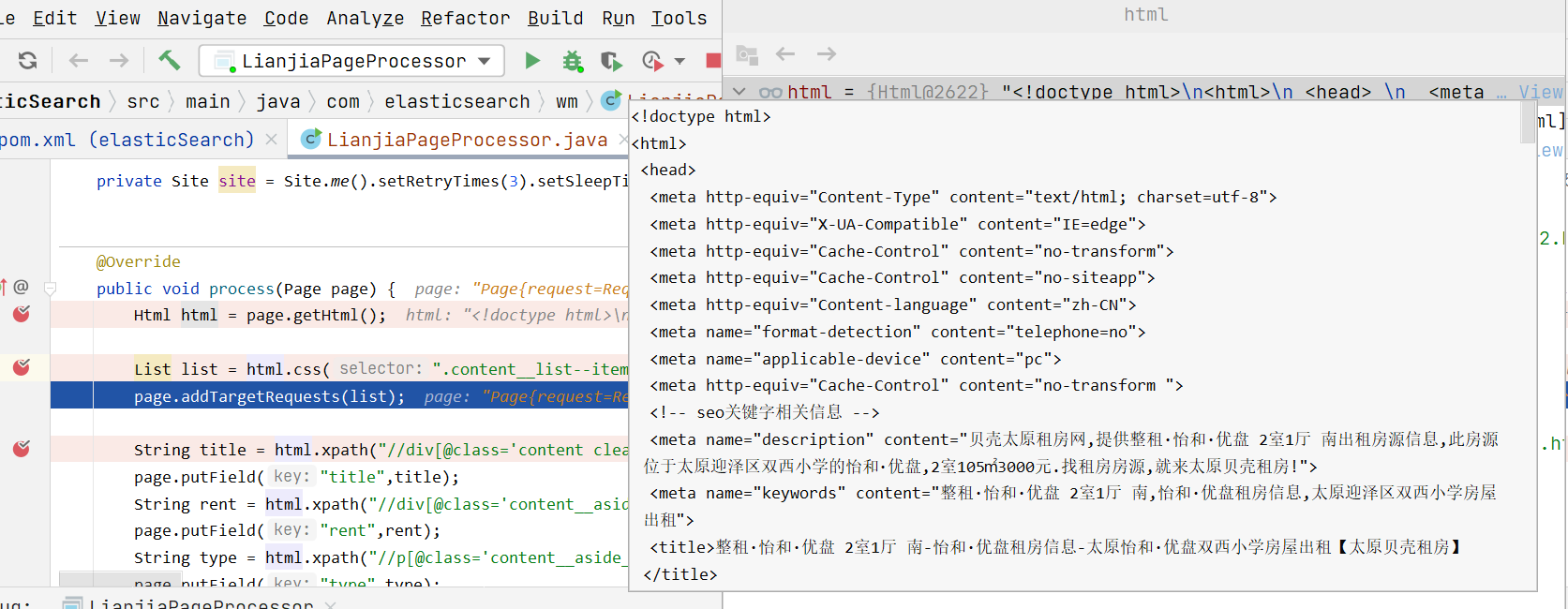
当前列表的详情页链接
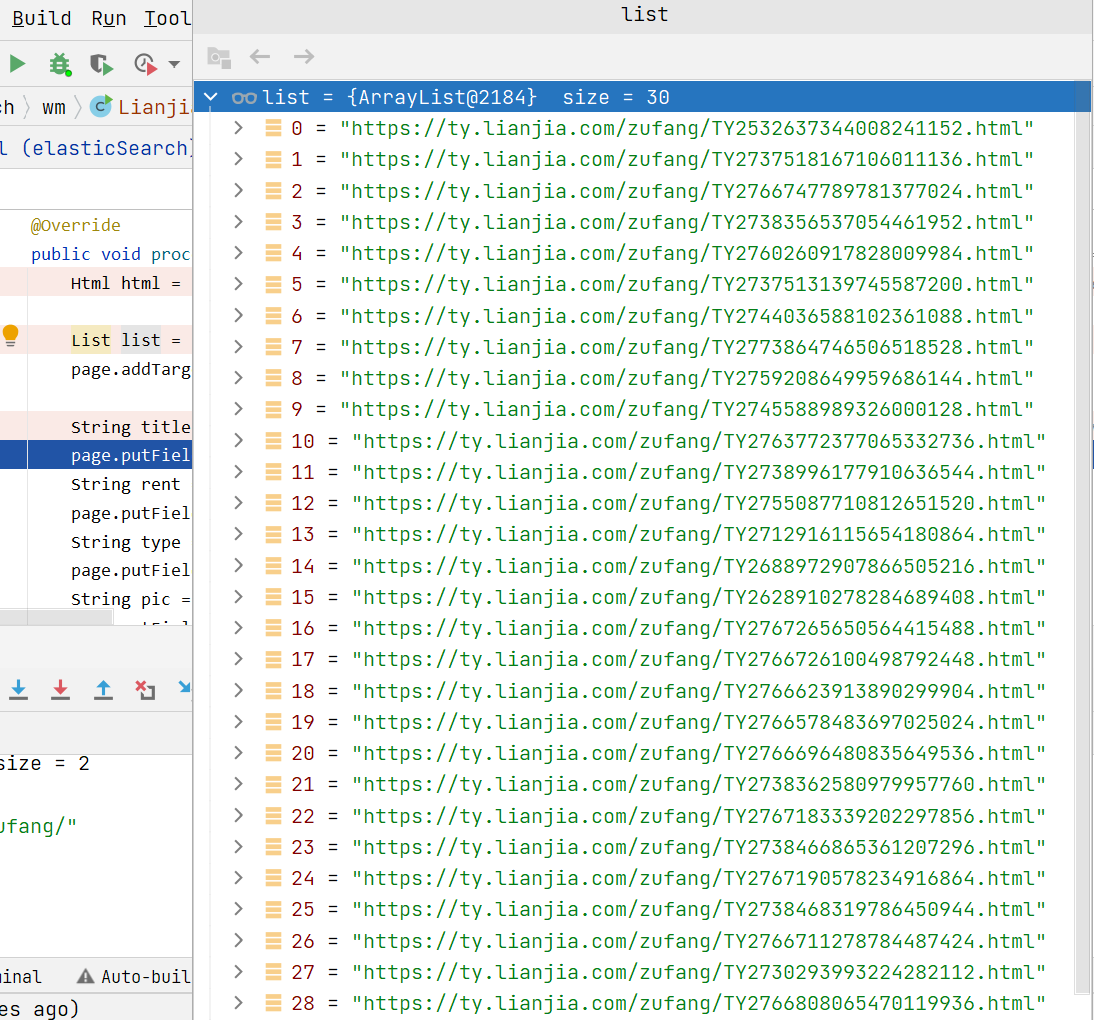
将其余列表页放入到待爬取链接
list中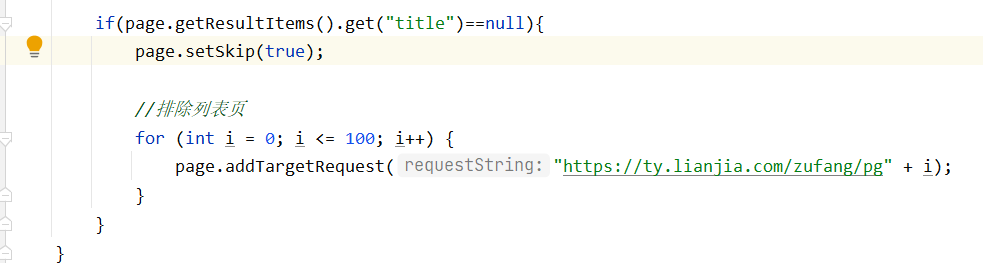
WebMagic内部有去重操作,已爬取过的页面不做重复操作去详情页面爬取信息
调试查看变量
对应的控制台输出

信息被存在
page变量中,默认是输出到控制台,可以编写Pipeline对page自行处理当
LianjiaPageProcessor.process()方法处理后,会调用MyPipeline进行处理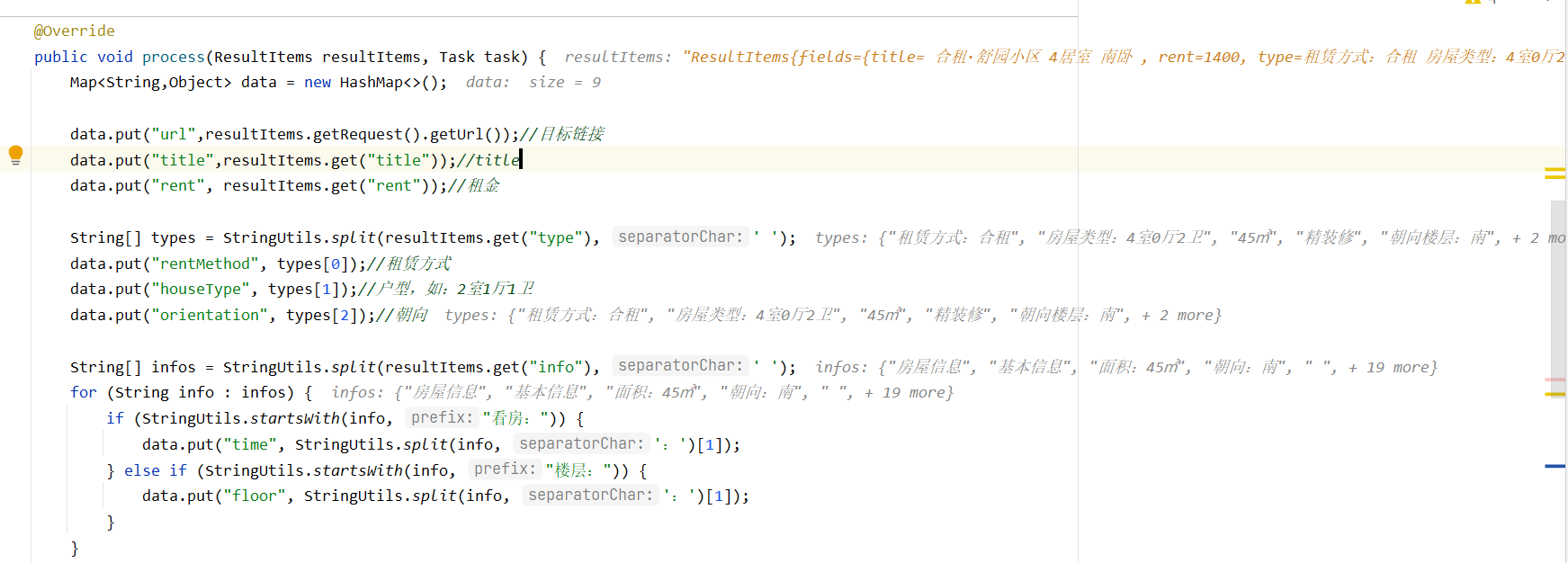
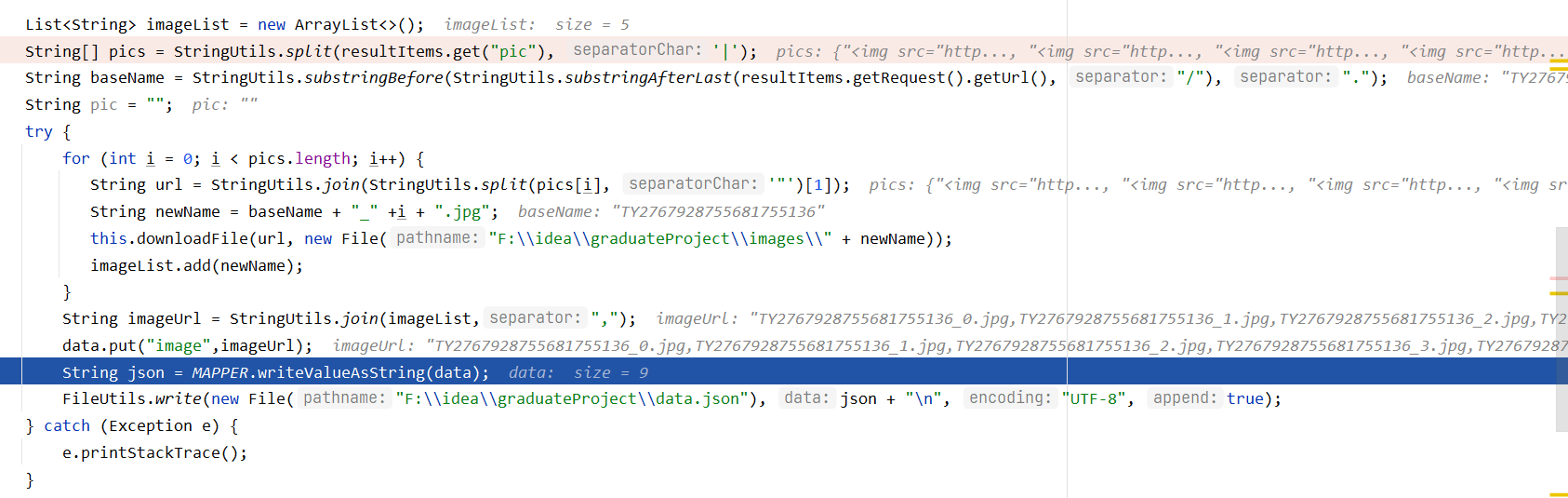
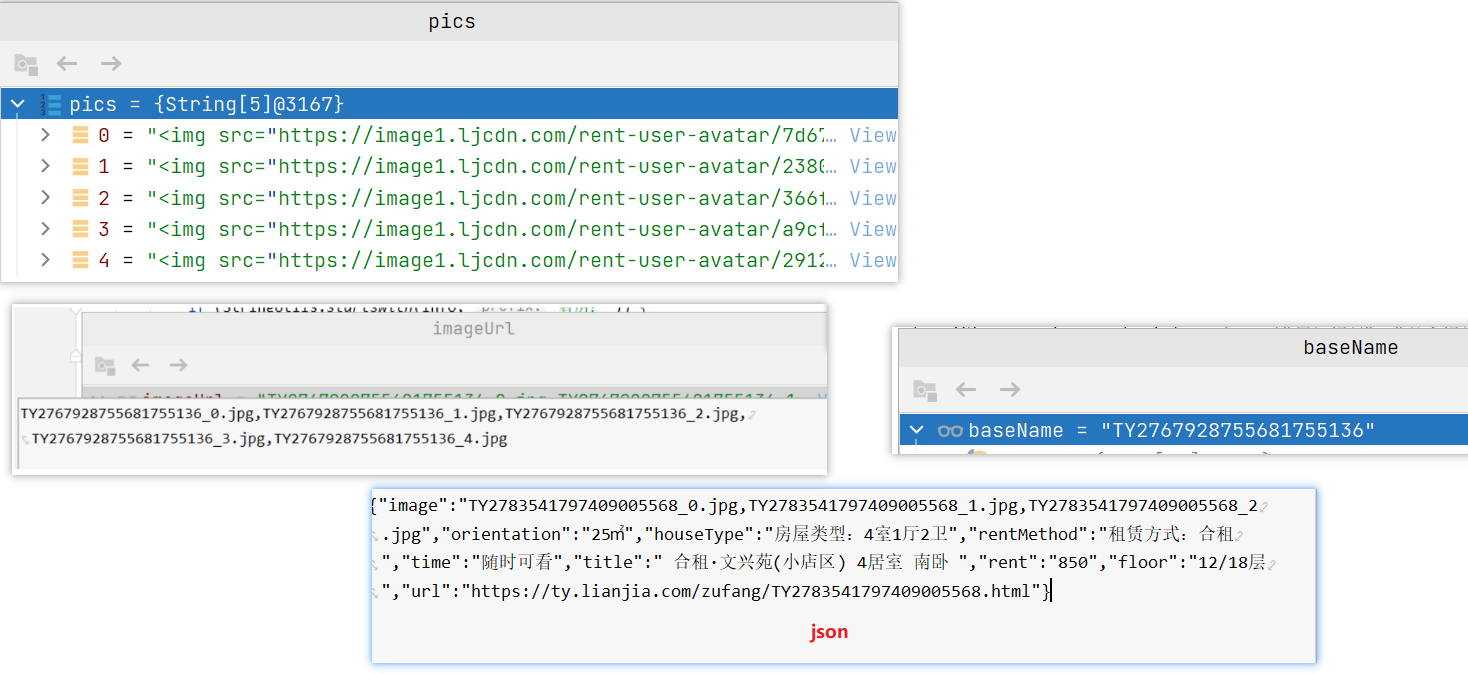
1. 导入依赖
1 | <dependency> |
2. 爬取逻辑
1 | package com.elasticsearch.wm; |
3. MyPipeline对信息处理
1 | package com.elasticsearch.wm; |
4. 将图片上传到COS
将数据导入ES
1. 设置ik分词器
1 | cd /data/es-cluster-data/ik |
测试ik分词器
1 | POST http://8.140.130.91:9200/_analyze |
2. 文档mapping
1 | # 新建索引 |
dynamic
- 参数来控制字段的新增
- true:默认值,表示允许自动新增字段
- false:不允许自动新增字段,但文档可以正常写入,但无法对字段进行查询
- strict:严格模式,文档不能写入,报错
index
- 控制当前字段是否被索引,默认为 true,false表示不记录,即不可被搜索
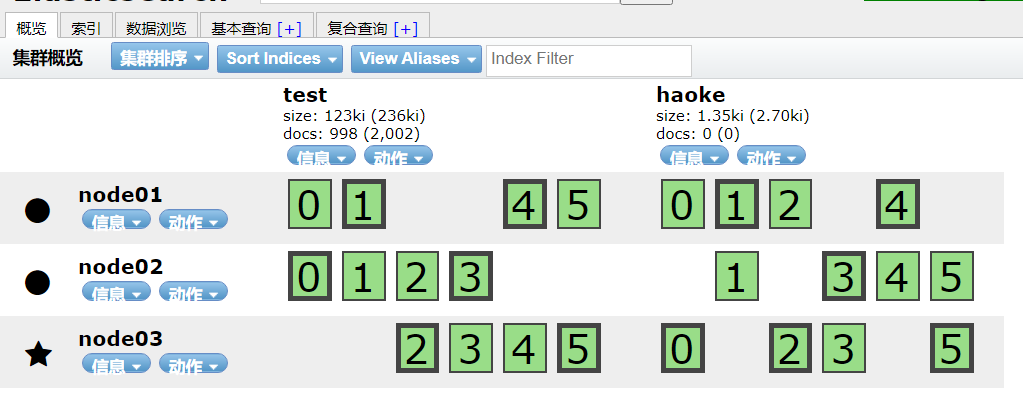
3. 测试ES集群
新增数据
1 | POST http://8.140.130.91:9200/haoke/house |

测试搜索
1 | POST http://8.140.130.91:9200/haoke/house/_search |
测试未被索引字段
1 | { |

index 被设置为false的字段不能进行搜索操作
4. 将数据批量导入ES
1 | import org.apache.commons.io.FileUtils; |
测试
1 | POST http://8.140.130.91:9200/haoke/house/_search |
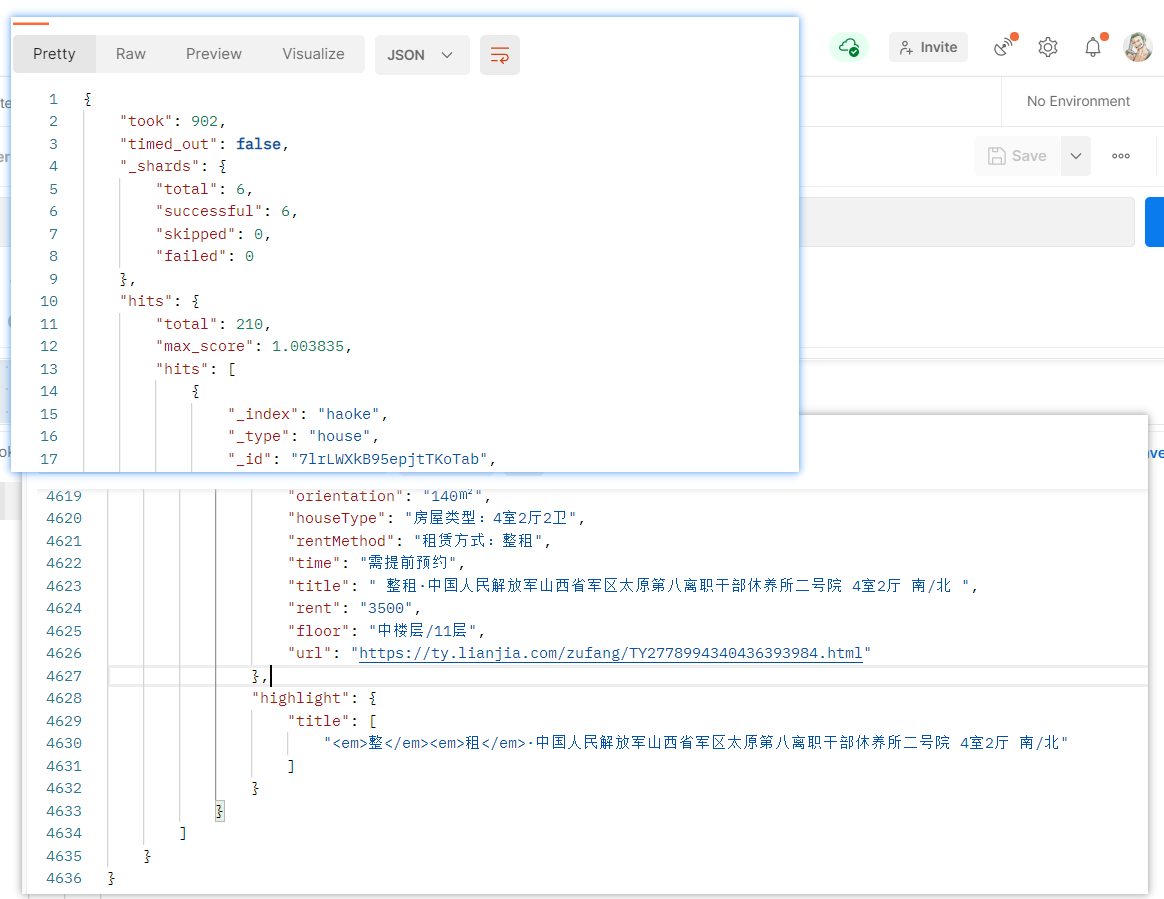
房源搜索功能
房源搜索接口
1. 导入依赖
1 | <!--ElasticSearch依赖--> |
2. 添加配置
1 | # elasticsearch配置 |
3. 编写vo——HouseData、SearchResult
1 |
|
1 |
|
4. 编写Controller
1 | package com.haoke.api.controller.frontController; |
5. 编写Service
1 | package com.haoke.api.service; |
6. 启动

整合Redis后,引发了netty冲突,需要在启动类中加入
1 | package com.haoke.api; |
7. 测试
1 | GET http://127.0.0.1:9091/housing/search?keyWord=整租&page=1 |
房源搜索整合前端
流程:
输入框聚焦,
this.state/searchBarFlag = true,则显示SearchBar输入框失焦,
this.state/searchBarFlag = false,则隐藏SearchBar
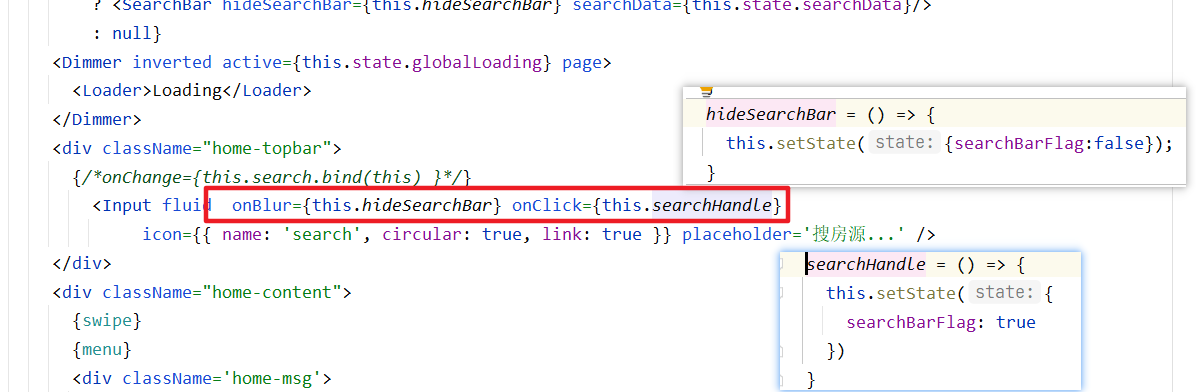
home.js
1 | class Home extends React.Component { |
home.css
1 | ··· |
SearchBar.js
1 | import React from 'react'; |
search.css
1 | .house-title{ |
房源搜索——高亮
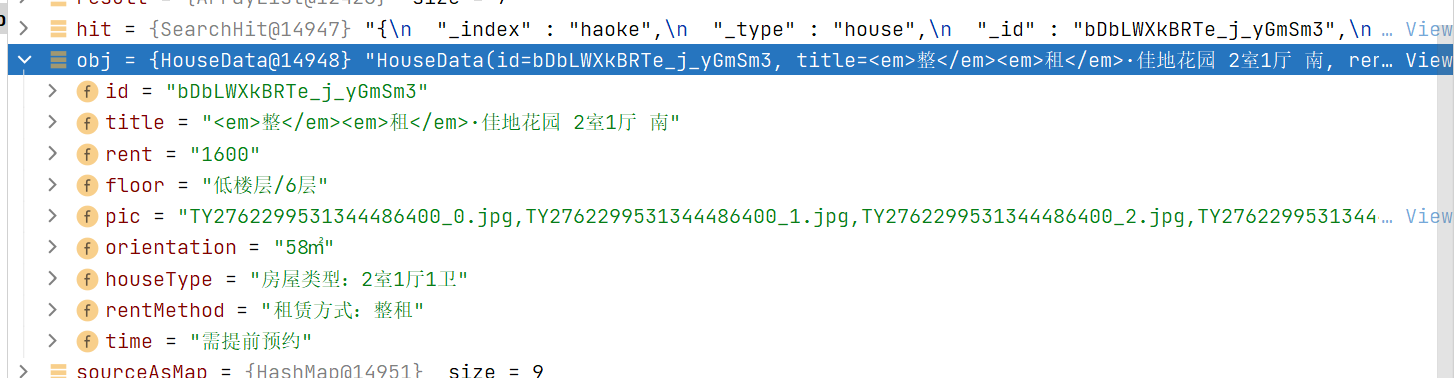
后台实现
1 | package com.haoke.api.service; |
1 | { |
整合前端
1 | <Item.Header><div className='house-title' dangerouslySetInnerHTML= |
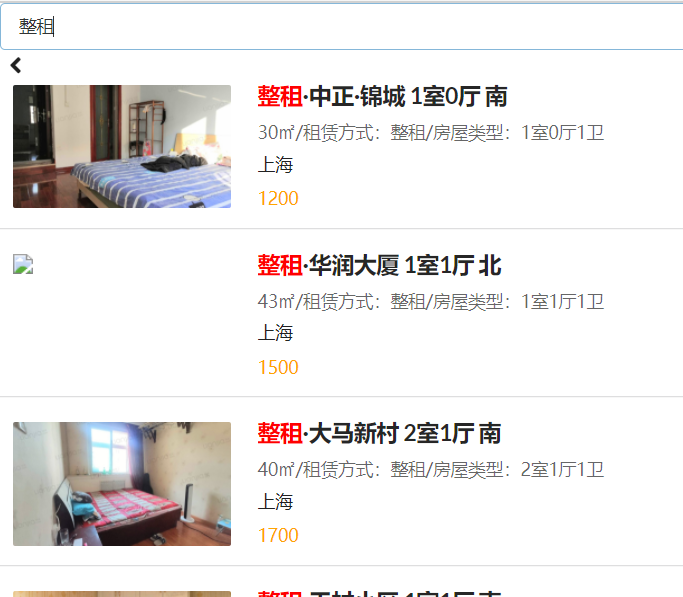
房源搜索——分页
分页组件
1 | import { Icon,Item,Pagination } from 'semantic-ui-react'; |
searchBar.js
1 | handlePageChange = (e, { activePage }) =>{ |
home.js
1 | search = (event, data) =>{ |
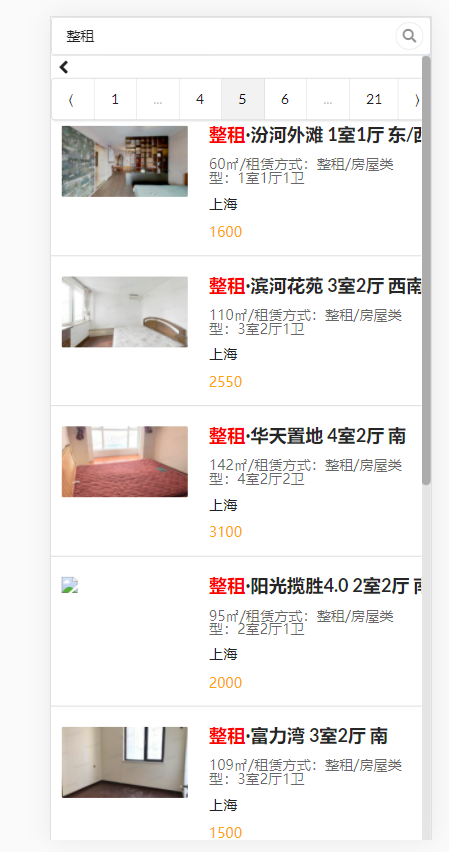
房源搜索——热词搜索
需求:当无搜索结果或搜索结果只有一页时,显示搜索热词,最多显示5个热词
热词:按照用户搜索的关键字以及搜索到的结果数量进行排序,结果数量越多的排到越前面
实现分析
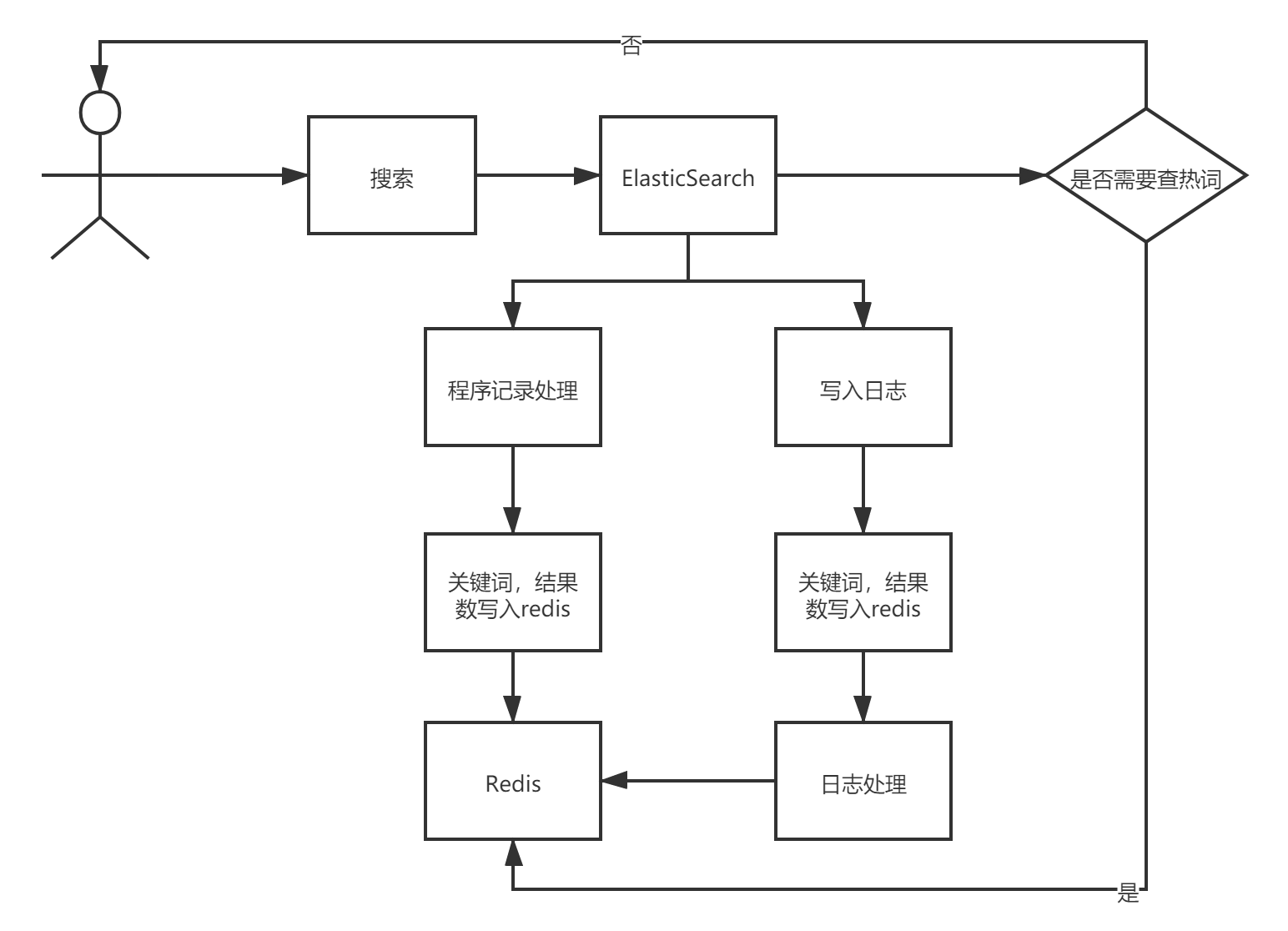
用户搜索数据,首先进行ES搜索
在搜索完成后,进行判断,是否需要显示热词
如果不需要,直接返回用户请求的数据
如果需要,则进行在
Redis中查询热词
对于用户搜索词的处理有两种方案
- 同步方案:在程序中进行处理,并且把搜索词以及命中的数据数量存到
Redis中 - 异步方案:将查询信息记录到日志文件中,由后续的程序做处理,然后再写入到Redis中
- 同步方案:在程序中进行处理,并且把搜索词以及命中的数据数量存到
后台
1 | package com.haoke.api.controller; |
前台
1 | # search.js |

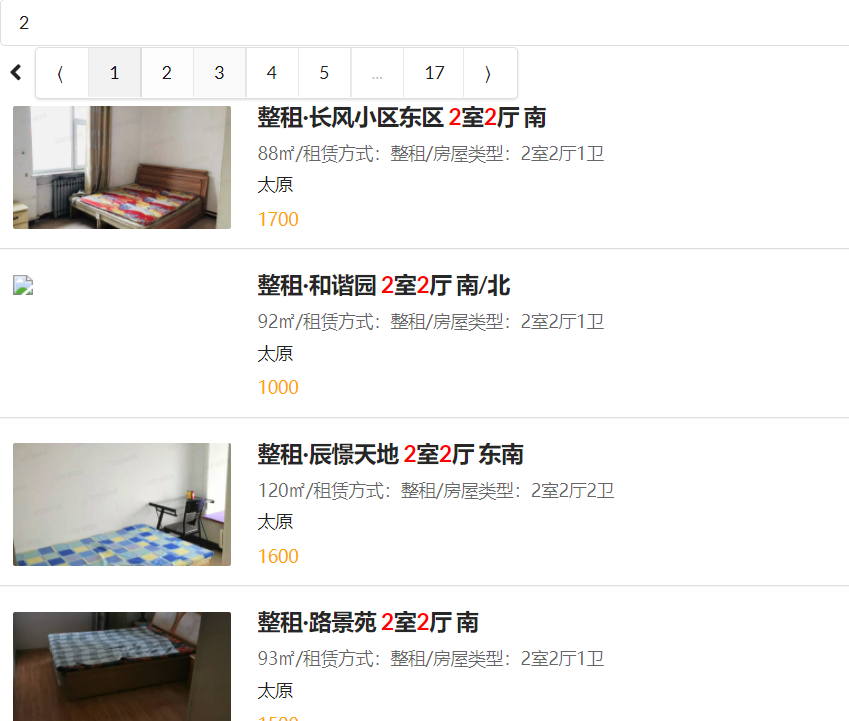
房源搜索——拼音搜索
ES拼音插件地址:https://github.com/medcl/elasticsearch-analysis-pinyin
1. ES集群引入拼音插件
1 | 将zip压缩包,解压到/data/es-cluster-data/pinyin |
2. 测试拼音分词
1 | PUT /medcl/ |
测试分词
1 | GET /medcl/_analyze |
3. 添加拼音分词支持
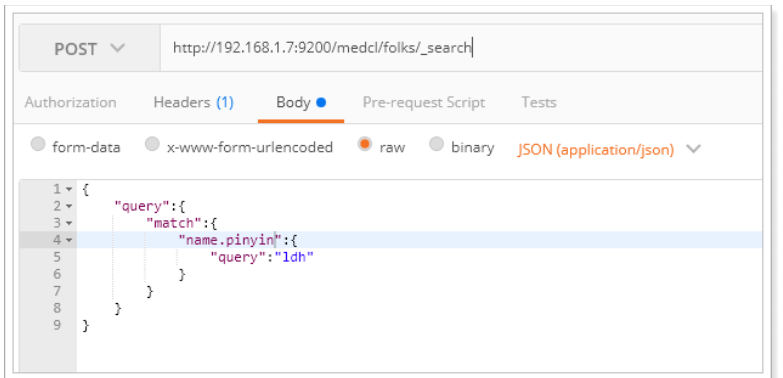
1 | POST /medcl/folks/_mapping |
这里使用的是name的子字段,通过fields指定
插入数据
1 | POST /medcl/folks/andy |
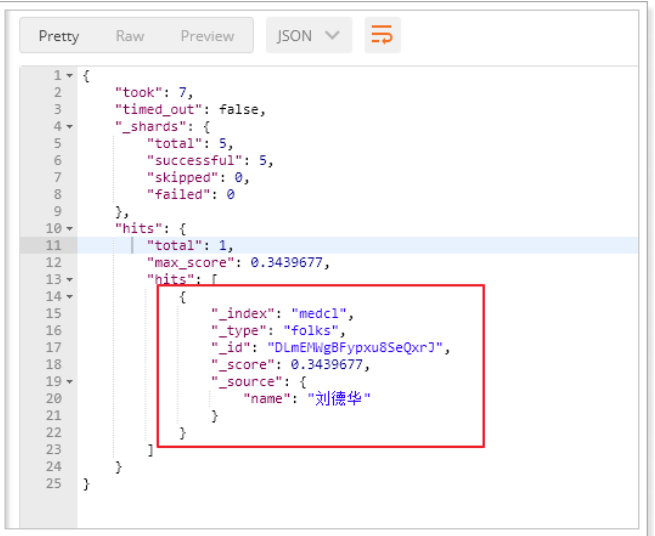
4. haoke索引添加拼音支持
1 | PUT http://8.140.130.91:9200/haoke/ |
测试
1 | POST http://8.140.130.91:9200/haoke/house/_search |

5. 修改ESControler查询逻辑
1 | SearchQuery searchQuery = new NativeSearchQueryBuilder() |