[TOC]
3.1 Ceph中的数据表示
3.1.1 Ceph对象
Ceph对象是数据及其元数据的组合,由一个全局唯一的标识符标识
基于对象存储的优势
- 基于文件的存储中,文件大小是有限制的,而对象则是可以随着大小可变的元数据变得很大
- 在一个对象中,数据存储为元数据 (数据上下文和数据内容),允许用户管理和访问非结构化数据
对象的存储
所有对象存放在物理上隔离的线性地址空间
这些对象以副本或纠删码的方式存储在基于对象的存储设备(OSD)中
当Ceph集群接收到来自客户端的数据写请求时,将收到的数据另存为对象,然后OSD守护进程将数据写入OSD文件系统的一个文件中
3.1.2 Ceph对象定位
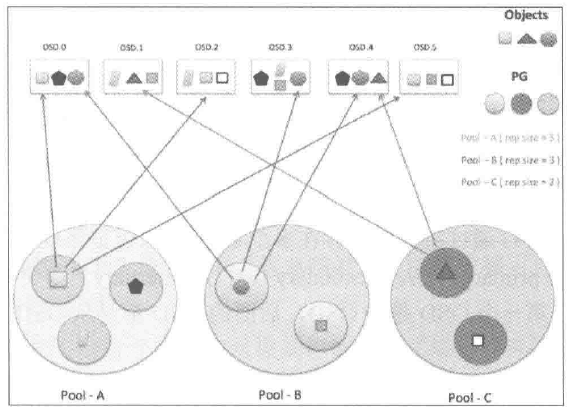
Ceph池
Ceph所有的数据都以对象的形式存储在一个池中,池是存储对象的逻辑分区,每个池包含一定数量的PG,交叉分布在集群所有的节点上的。
Ceph集群部署完成后,会创建一些默认的存储池(rbd)
- 若集群中配置了MDS,则会创建data、metadata池
1 | ceph -s#查看集群信息 |
池根据ceph.conf中配置的副本数创建指定数量的副本池,保障数据的高可用性,比如:复制或纠删码技术(二选一)
- 纠删码:将数据分解成块编码,然后以分布式的方式存储
当数据写入池时,Ceph池会映射到一个CRUSH规则集,CRUSH规则集为Ceph池提供了新的功能
- 缓冲池:创建一个使用SSD的faster池或SSD、SAS和SATA硬盘组成的混合池
- 支持快照:
ceph osd pool mksnap - 为对象设置所有者和访问权限:给池分配一个用户ID标识该池的所有者
池操作
1 | ceph osd pool create [池名] [PG数] [PGP数] #创建池并制定PG和PGP数量 |
删除池时会删除所有该池的所有快照。
- 如果为池手动增加了CRUSH规则集,在删除池后,需要手动删除该CRUSH规则集
- 如果为池的某个用户创建了一个权限,也需要删除该用户
1 | ceph osd pool delete [池名] [池名] --yes-i-really-really-meant-it |
PG
CRUSH首先将一条数据分解为一系列对象,然后根据对象名称、复制级别和系统中总的PG数 PG_num 执行散列操作,生成PG ID
PG是一组对象的逻辑集合(可能不属于同一条对象),根据Ceph池的副本数,PG会被复制到不同的OSD上可以提高系统的可靠性
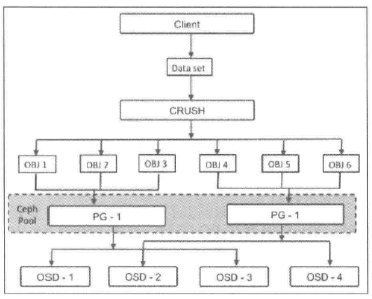
通过PG,可以减少系统管理大量对象带来的资源占用,一般来说,增加集群的PG数能降低每个OSD上的负载,所以PG数需要根据集群规模调整
- 建议每个OSD上放置50-100个PG
PG数计算
平衡每个池中的PG数和每个OSD中的PG数对于降低OSD差异,避免恢复过程缓慢有很大意义
修改PG和PGP
PGP是为定位设置的PG,对于一个池而言 pgp_num=pg_num
对于再平衡操作:当某个池的 PG_num 增加,这个池的每个PG会被一分为二,但先不进行再平衡。等到 pgp_num 被增加时,PG才开始从源OSD迁移到其他OSD,正式开始再平衡
配置指令
1 | ceph osd pool get [池名] 属性名 |
PG peer 和up、acting集合
acting集合负责PG的一组OSD,up集合中的第一个OSD为主OSD,其余为第二、第三…OSD
对于某些PG而言,某个OSD为主OSD,但同时对于其他PG来说,该OSD可能为非主OSD
主OSD的守护进程负责该PG与第二第三OSD间的 peer操作
该PG的所有对象及其元数据状态
存放该PG的所有OSD间的确认操作
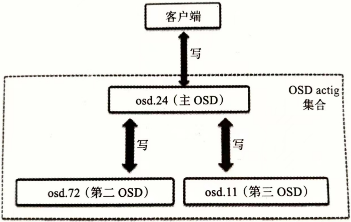
处于up状态的主OSD会保持在up与acting集合中
- 正常状态acting集合和up集合一样
- up[]:是一个特定CRUSH规则集下的一个特定OSD map版本的所有相关OSD的有序列表
- acting[]:特定PG map版本的OSD集合
一旦变为down,首先会将其从up集合中移除,再从acting集合中移除。第二OSD会被晋升为主OSD。Ceph会将出错OSD上的PG恢复到新的OSD上,并将该OSD添加到up集合和acting集合中
存储过程
Ceph中的所有数据都会被切分为对象(objects)。Object size 大小由管理员调整,通常为2M或4M。
每个对象都会有唯一的OID,ino和ono生成:ino是文件的File ID,用于全局唯一标志每一个文件,而ono是分片的编号
一个文件FileID是A,被切分为两个对象(一个编号为0,另一编号为1),这两个对象的OID则为A0和A1。
3.2 Ceph数据管理
3.2.1 数据写入过程
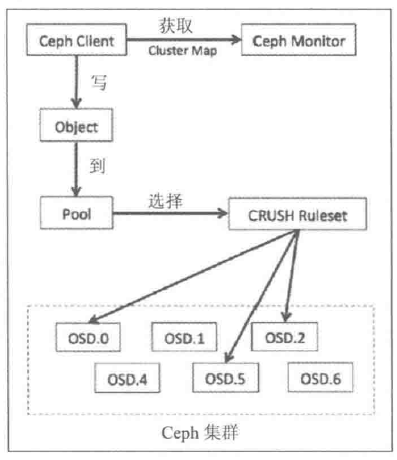
- 客户端-首先与monitor通信,获取集群的map副本,从而 获取Ceph集群状态和配置信息
- 客户端-使用对象和池名/ID 将数据转换为对象
- 客户端-将对象和归置组数(Placemnent group,PG)经过 散列 生成其在Ceph池中最终存放的PG ID
- 客户端-将计算好的PG经过 CRUSH查找 确定存储或获取数据所需的主OSD ID
- 客户端直接相向主OSD 存储 数据
- 主OSD-在写入数据后,执行CRUSH查找,计算辅助归置组和辅助OSD位置来 复制数据副本 ,并等待它们确认写入完成,接收其他OSD返回的写入完成应答信号。
- 最后主OSD向客户端返回写入完成应答信号
3.2.2 相关指令
1 | 生成文件,创建池 |
正常情况下,osd是彼此物理隔离的
ceph osd tree
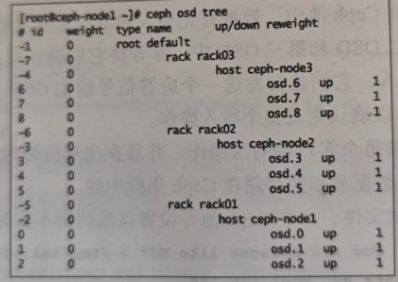
登录到任意一个节点检查OSD上实际存放数据的地方,可以从文件角度看到对象

对象object1被存放在ceph-node2上的PG10.3c中,该PG所在的osd为osd.3,对应的系统分区为/dev/sdb1
3.3 CRUSH计算寻址
3.3.1 元数据机制
每一次有新数据添加到存储系统中时,元数据最先更新(数据存放的物理位置 ),之后才是实际的数据存储
- 元数据是描述数据的数据,包含与数据存储有关的信息(存储节点、磁盘阵列位的位置)
缺点
造成存储系统的单点故障
改进:
在单个节点上保存多个副本
复制整个数据和元数据保证更高的容错度
不管如何改进,复杂的元数据管理机制是存储系统在高伸缩性、高可用性和性能上的瓶颈
3.3.2 CRUSH算法
Ceph使用可扩散散列下的受控复制(Controlled Replication Under Scalable Hashing,CRUSH)算法按需计算元数据,而不存储元数据,元数据的计算过程也被称为 CRUSH查找
对Ceph集群的读写操作:客户端使用自己的系统资源来执行CRUSH查找
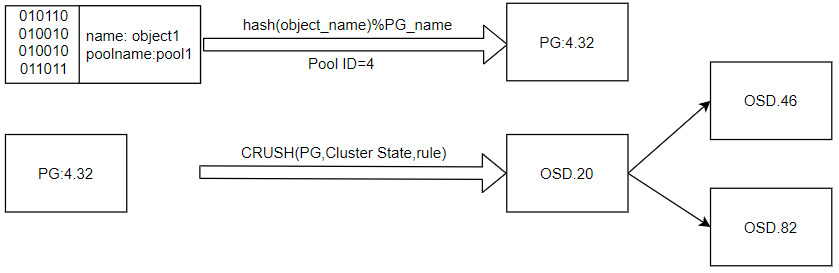
数据复制规则
CRUSH跨故障域传播数据及其副本
CRUSH均匀地在整个集群磁盘上读写数据,确保磁盘中的所有磁盘被同等地利用
OSD权重:每个OSD都有相应的权重,OSD权重越高,表示物理存储容量越大,CRUSH可以将更多地数据写入这个OSD
恢复与再平衡
恢复等待时间
在故障域中的组件发生故障后,Ceph会进入默认等待时间,等待时间耗尽后,会将该OSD标记为 down out 并初始化恢复
- 通过Ceph集群配置文件中的
mon osd down out interval配置项,可以修改等待时间
再平衡操作
在恢复操作期间,Ceph会进行再平衡操作:重新组织发生故障的结点上受影响的数据,保证集群中所有磁盘能均匀使用
原则:尽量减少数据的移动来构建新的集群布局
对于利用率高的集群,建议先将新添加的OSD权重设置为0,再依据磁盘容量逐渐提高权重,减少Ceph集群再平衡的负载并避免性能下降
3.4 后端存储Object Store
Object Store完成实际的数据存储,封装了所有对底层IO的操作
- IO请求从客户端发出后,最终会使用ObjectStore提供的API将数据存储磁盘
目前有四种实现方式,可以在配置文件中通过 osd_objectstore 指定:
- MemStore:将所有的数据放入内存;仅由于测试
- KSStore(元数据):将元数据和Data全部放入KVDB;仅用于测试
3.4.1 FileStore
L版之前,OSD后端存储只有FileStore;L版~R版,默认为BlusStore;R版之后,FileStore废弃
FileStore基于Linux现有的文件系统,将Object存放在文件系统上。
每个Object会被FileStore看做一个文件,Object的属性(xattr)会利用文件属性存取
- 对于ext4,对xattr有限制,超出长度的属性会用 omap 存储
3.4.2 BlueStore
FileStore最初只针对机械盘设置,并未对SSD进行优化,且写数据前先写日志带来了一倍的写放大。
BlueStore专为管理Ceph OSD工作负载的磁盘数据而设计。去除了日志,直接管理裸设备来减少文件系统部分的开销,并且对SSD进行了单独优化
与传统文件系统类似,分为三部分:
- 数据管理
- 元数据管理
- 空间管理
与文件系统区别之处在于数据与元数据可以存储在不同的介质中
功能
直接管理存储设备
- BlueStore使用原始块设备或分区,避免文件系统(XFS)的限制与抽象干预层
使用RocksDB进行元数据管理
- 对象名到磁盘块位置的映射
完整数据和元数据校验和
- 写入BlueStore的所有数据和元数据都收到一个或多个校验和的保护
- 未经验证,不会从磁盘读取任何数据、元数据且不会返回给用户
内联压缩
- 数据在写入磁盘之前可以选择进行压缩
多设备元数据分层
- BlueStore允许将其内部日志(预写日志)写入单独的高速设备(SSD、NVMe或NVDIMM),以提高性能。
3.4.3 SeaStore
目前仅是设计雏形
设计目标:
- 专门为NVMe设备设计,不是PMEM和硬盘驱动器
- 使用SPDK访问NVMe,不再使用Linux AIO
- 使用SeaStar Future编程模型优化,使用share-nothing机制避免锁竞争
- 网络驱动使用DPDK实现零拷贝
由于Flash设备特性,重写时必须进行擦除操作,并不清楚哪些数据有效,哪些数据无效,但文件系统知道。
Ceph希望垃圾回收有SeaStore来做,SeaStore的设计思路:
SeaStore逻辑段应该与硬件(Flash擦除单位)对齐
SeaStar是每个线程一个CPU核,所以将底层按照CPU核进行分段
当空间使用率达到设定上限就进行回收,当segment完成回收后,就调用discard线程通知硬件进行擦除。
尽可能保证逻辑段与物理段对齐,避免出现逻辑段无有效数据但是底层物理段存在,会造成额外的读/写操作
同时由discard带来消耗,需要尽量平滑地处理回收工作,减少对正常读/写的印象概念股
用一个公用的表管理segment的分配工作