[TOC]
5. 深度计算
5.1 层和块
5.1.1 块的概念
整个深度模型包含一些参数(所有组成层的参数集合),接受原始输入,生成输出。同样,每个层包含该层的参数,接受上一层提供的输出作为输入,并生成该层输出,这些参数根据下一层反向传播的信息被更新(误差反向传播)
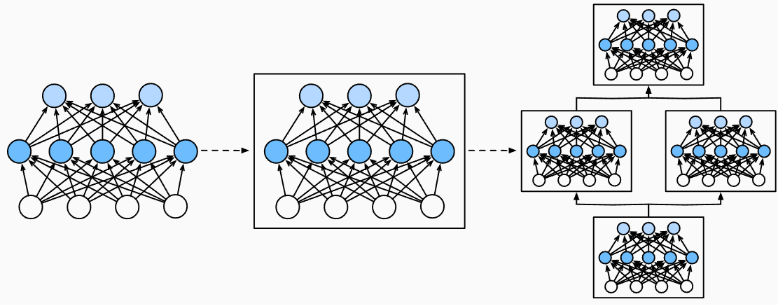
- 视觉领域,ResNet-152有数百层,这些层由 层组(groups of layers) 堆叠组成
- 其他领域,也有 层组 堆叠排列的类似架构
因此将神经网络组成模块划分为 块(Module), 块可描述单个层、多个层组成的 层组 或深度模型本身。
5.1.2 pytorc中的块
从编程实现角度,块 的概念就是 类 。块 nn.Module 的任何子类都必须定义 $输入\mapsto 输出$ 的前向传播函数 forward(self,X) ;对各层输入、输出参数的初始化(该层参数形状)
- 反向传播函数用于计算梯度,但由于自动微分的引入,不需要考虑
1 | import torch |
nn.Sequential 构建了一个深度模型,层的顺序是参数传入的顺序
nn.Sequential:是nn.Module的一个子类,维护 块 实例的有序列表(也是nn.Module的实例 / 子类实例 )1
2print(nn.Sequential.__mro__)
(<class 'torch.nn.modules.container.Sequential'>, <class 'torch.nn.modules.module.Module'>, <class 'object'>)
net(参数) 调用深度模型:相当于 net.__call__(X) 的简写
自定义块
块提供的功能
- 存储和访问前向传播计算所需的参数
- 根据需要初始化模型参数
- 接收输入数据:作为前向传播函数的参数
- 通过前向传播函数生成输出
- 计算输出关于输入的梯度:反向传播函数访问;通常自动微分完成
1 | class MLP(nn.Module): |
顺序块
Sequential的设计是为了把其他模块串起来
__init(self, *args)__:将块逐个追加到列表中forward:前向传播:将输入按追加块的顺序前向传播
1 | class MySequential(nn.Module): |
自定义有序字典类 OrderedDict 作用:在模型初始化过程中,pytorch从其实例 _modules 中查找需要初始化参数的子块
1 | net = MySequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10)) |
nn.ReLU()内部调用了F.rele(),具有状态和可学习参数
块访问
nn.Sequential 实例可以理解为一个 nn.module 类实例的有序列表,可以通过索引来访问模型的任一层
1 | # 访问顺序块,返回顺序块实例信息 |
自定义块的特殊用法
Sequential 类允许我们定制深度网络架构,并提供很大灵活性。如:可以在前向传播中引入控制流或自定义处理
层引入常数参数
若在某一层需要合并一些其他参数 常数参数(constant param) :既不是上一层结果也不是可更新参数,如 $f(\mathbf{x};\mathbf{W})=c\mathbf{x}\mathbf{W}^T$ ,$c$ 就是常数参数,整个优化过程没有被更新
1 | class FixedHiddenMLP(nn.Module): |
块组合
Sequential 类允许我们定制深度网络架构,并提供很大灵活性
1 | class NestMLP(nn.Module): |
5.1.3 操作效率
在一个高性能的深度学习库中进行了大量的字典查找、 代码执行和许多其他的Python代码。 Python的问题全局解释器锁 是众所周知的。 在深度学习环境中,我们担心速度极快的GPU可能要等到CPU运行Python代码后才能运行另一个作业。
5.2 参数管理
Paramater 类的实例是可优化的参数实例
在定义好模型架构并设置好超参数后,完成对 各层参数设置 后,就可以进行模型训练
- 访问参数
- 参数初始化
- 不同 块(module) 间共享参数
1 | import torch |
5.2.1 参数访问
net.state_dict() 返回块的所有参数信息组成的字典 OrderedDict
- 权重就是神经网络的状态,权重的一轮迭代就是网络状态的一次变化
1 | # 使用nn.Sequential,该类封装了一些按索引访问方法,支持列表式访问各层 |
Linear类实例的输出是一个字典,键包括:权重,偏置
- 键唯一标识每个参数
参数类
每个参数都被表示为一个参数类实例(<class 'torch.nn.parameter.Parameter'>),属性有:
- 值:
data - 梯度:
grad - 其他额外信息
这些参数信息可以被统一管理和更新,所以需要 Parameter 类
1 | print(type(net[2].bias)) |
一次性访问所有参数net.named_parameters()
1 | # *[...]参数解包 |
从嵌套块收集参数
深度模型中,层之间存在嵌套关系,也可以通过嵌套列表索引分层访问块参数
1 | def block1(): |

1 | # rgnet[0]=block2() |
5.2.2 参数初始化
pytorch提供默认随机初始化,也允许通过重写自定义初始化方法
- 默认情况下,PyTorch会根据一个范围均匀地初始化权重和偏置矩阵, 这个范围是根据输入和输出维度计算出的——Xavier初始化
预置初始化
nn.init 模块提供类很多预置的初始化方法
- 正态分布
- 全0,全1
- 常量
- Xavier初始化
正态分布、全0/全1
1 | def init_normal(m): |
net.apply(fn) 递归地将一个函数应用到神经网络中的每个子模块上,包括其本身
- 需要定义一个函数,该函数接收一个模块作为参数,并对该模块执行自定义操作
常量
1 | def init_constant(m): |
Xavier初始化
xavier_normalxavier_normal_:这个是更新后的版本,在计算时会考虑到ReLU激活函数的特性,以确保网络在初始化时的激活值分布更加合理xavier_uniformxavier_uniform_
1 | def init_xavier(m): |
自定义初始化
1 | def my_init(m): |
也可以在任意位置直接修改参数
1 | net[0].weight.data[:] += 1 |
5.2.3 参数共享
在层之间共享权重,实质上共享层引用是同一个参数矩阵的值
1 | # 我们需要给共享层一个名称,以便可以引用它的参数 |
net有4个隐藏层,第二个隐藏层和第三个隐藏层都由shared定义
- 作用:由于模型参数包含梯度,因此在反向传播期间参数共享层的梯度会加在一起
5.3 自定义层
与自定义块类似,只需要继承 nn.module ,并实现 __init__(self) 和 forward(self,X) 即可
5.3.1 不带参数的层
1 | import torch |
只要继承了 nn.Module 类的块都可以应用到更复杂的模型中
1 | net = nn.Sequential(nn.Linear(8, 128), CenteredLayer()) |
不管第1隐藏层输出是什么,$\overline{h_1-\overline{h}_1}=\frac{\sum\limits (h_1-\overline{h}_1)}{\vert h_1\vert}=\frac{\sum h_1-\vert h_1\vert\overline{h_1}}{\vert h_1\vert}=0$ ,即 Y.mean() 应该为0 ,在计算机中表示为一个非常小的数
5.3.2 带参数的层
接受层的输入与输出形状
由于参数在torch中以 Paramater 类封装便于计算,所以在 __init__() 中将参数定义为该类
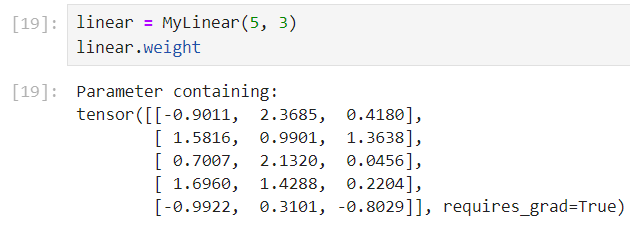
1 | class MyLinear(nn.Module): |
通过 nn.Paramater 实例化自定义参数的形状与定义时相同,即 p=nn.Parameter(torch.randn(5, 3)) ,则 p.shape=torch.Size([5,3])
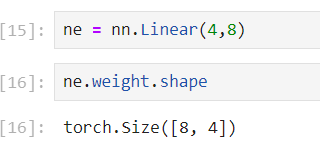
通过 net=nn.Linear(5,3) 实例化 块 ,其参数 ne.weight.shape=torch.Size([3, 5])
1 | linear(torch.rand(2, 5)) |
也可以将自定义应用于网络模型构建
1 | net = nn.Sequential(MyLinear(64, 8), MyLinear(8, 1)) |
5.3.3 自定义添加层—net.add()
net.add_module([key],[块声明]) :向神经网络中添加模块
net.add_module('layer1', nn.Linear(10, 20))
5.4 读写文件
有时我们希望保存训练的模型, 以备将来在各种环境中使用(比如在部署中进行预测)。 此外,当运行一个耗时较长的训练过程时, 最佳的做法是定期保存中间结果,以确保在服务器电源被不小心断掉时,我们不会损失几天的计算结果
5.4.1 加载和保存
对于基本类型:tensor ,tensor[] ,mydict={'a':a,'b':b} 直接调用 torch.load() 和 torch.save() 进行读写,参数为要保存的变量
1 | import torch |
5.4.2 保存和加载模型参数
深度学习框架提供了内置函数来保存和加载整个网络
但并不保存整个模型架构,为了恢复模型,我们需要用代码生成架构, 然后从磁盘加载参数
1 | class MLP(nn.Module): |
保存参数 :将模型 state_dict() 输出的参数字典 OrderedDict 实例,保存在 mlp.params 的文件中
1 | torch.save(net.state_dict(), 'mlp.params') |
恢复模型 :读取文件,并转换为 OrderedDict 类的实例作为参数
1 | clone = MLP() |
5.5 GPU
使用GPU来进行机器学习,因为单个GPU相对运行速度快
1 | 查看nvidia驱动程序及CUDA |
在torch中,每个数据都归属于一个设备 (device),称其为环境(context)。默认情况,所有的变量和计算都分配给CPU
设备间进行数据传输非常不划算 ,在设备(CPU、GPU和其他机器)之间传输数据比计算慢得多。这也使得并行化变得更加困难,因为我们必须等待数据被发送(或者接收),然后才能继续进行更多的操作。
- 根据经验,多个小操作比一个大操作糟糕得多。 此外,一次执行几个操作比代码中散布的许多单个操作要好得多。 如果一个设备必须等待另一个设备才能执行其他操作, 那么这样的操作可能会阻塞。
- 当我们打印张量或将张量转换为NumPy格式时, 如果数据不在内存中,框架会首先将其复制到内存中, 这会导致额外的传输开销。 更糟糕的是,它现在受制于全局解释器锁,使得一切都得等待Python完成。
在创建、使用变量是要合理分配环境,最大限度地减少设备间的数据传输时间
5.5.1 设备查看
GPU设备仅代表一个卡和相应的显存,如果有多个 GPU,使用 'cuda:0','cuda:1' 分别表示第1块和第2块GPU,'cuda' 默认返回第1块GPU
1 | import torch |
在torch中,通过 torch.device([设备字符串]) 查看在运算时可使用的设备
1 | # 查看设备数量 |
5.5.2 设备获取
1 | # 尝试将第i块gpu拿出来返回 |
5.5.3 使用GPU存储变量
1 | x = torch.tensor([1, 2, 3]) |
可见,不指定设备的前提下,变量默认存储在CPU上
将变量存储在GPU
若对两个张量运算,首先要确定两个张量存储在同一个设备上
创建时指定设备
1 | X = torch.ones(2, 3, device=try_gpu()) |
设备间复制
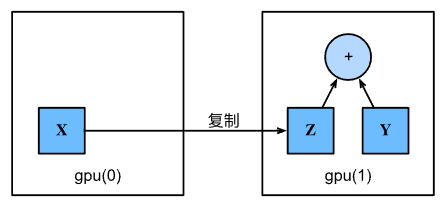
X与Y需要再同一个设备上才可以计算,否则由于在同一设备上找不到数据导致异常。 若不在同一GPU上,需要将变量复制到同一GPU上
1 | # 将X移动到GPU 1上作为变量Z |
假设变量 Z 已经在第2个GPU上,仍会返回 Z ,并不会复制并分配新内存
神经网络与GPU
神经网络模型也可以指定设备
1 | net = nn.Sequential(nn.Linear(3, 1)) |